【阿里云高校计划】阿里云AI训练营_Day03_电子相册
项目介绍
参加阿里云AI训练营的第3天,完成一个电子相册。
电子相册需要用到 “人脸属性识别” 和 “场景识别” 2个服务,开通之后就开始我们的项目吧!
项目用到文档地址
阿里云达摩院视觉开放平台:https://vision.aliyun.com/
阿里云视觉开放平台 “人脸属性识别” 地址:https://help.aliyun.com/document_detail/151968.html?spm=a2c4g.11186623.2.20.19714c68VRbnB9
阿里云视觉开放平台 “场景识别” 地址:https://help.aliyun.com/document_detail/152007.html?spm=a2c4g.11186623.6.670.19714c68sp5KFt
github给出的示例代码地址:https://github.com/aliyun/alibabacloud-viapi-demo
项目开始
(1)引入项目依赖
依赖就按照示例代码中的依赖来吧,引入之后可以支持本地图片上传。
<dependency>
<groupId>com.aliyungroupId>
<artifactId>aliyun-java-sdk-coreartifactId>
<version>4.4.9version>
dependency>
<dependency>
<groupId>com.aliyungroupId>
<artifactId>facebodyartifactId>
<version>0.0.7version>
dependency>
<dependency>
<groupId>com.aliyungroupId>
<artifactId>imagerecogartifactId>
<version>0.0.5version>
dependency>
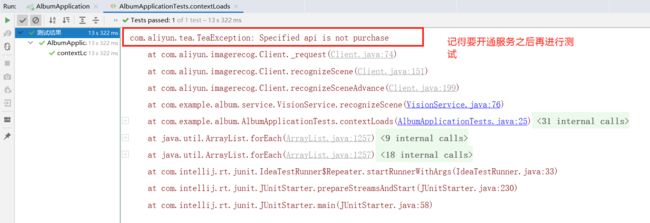
- 记得要开通对应场景的服务,否则就会报这样的错误
(2)创建并初始化 Client,Config
和之前的套路一样,我们需要创建对应场景的 Client 和 Config 类,关于这部分的详细解释可以参照我的上一篇博客 【阿里云AI训练营-_Day02-身份证识别】。
关于 Config 的属性配置,文档中也详细说明了,我们要根据不同的场景赋予不同的值。
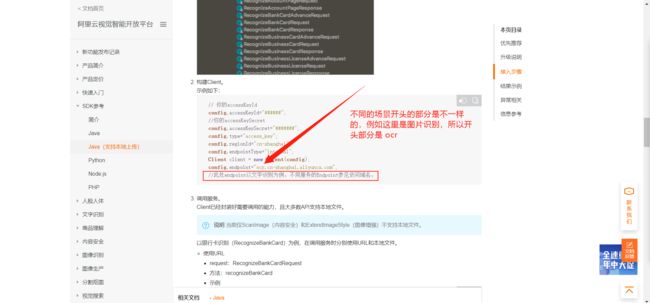
由于我们用到了 2 个场景的服务,所以可以先定义2个关于场景的变量用来标识不同的场景
定义 2 个标识场景的变量
// 我们自己的 accessKey 和 accessSecret,需要在配置文件中配置
@Value("${aliyun.accessKeyId}")
private String accessKey;
@Value("${aliyun.accessSecret}")
private String accessSecret;
// 人脸属性识别的场景标识
static String faceBodyEndpoint = "facebody";
// 图片场景识别的标识
static String imageRecogEndpoint = "imagerecog";
下面分别贴出关于 2 个场景的 Client 和Config 类的配置
Client 和 Config 配置
// 创建人脸属性识别的 Client
private com.aliyun.facebody.Client getFaceBodyClient(String endpoint) throws Exception {
com.aliyun.facebody.models.Config config = new com.aliyun.facebody.models.Config();
config.accessKeyId = accessKey;
config.accessKeySecret = accessSecret;
config.type = "access_key";
config.regionId = "cn-shanghai";
config.endpointType = "internal";
// 这里的 config.enpoint 由外部传入,就是传入我们一开始定义的变量,格式化之后为: facebody.cn-shanghai.aliyuncs.com , 对应 人脸属性识别的域名
config.endpoint = String.format("%s.%s", endpoint, "cn-shanghai.aliyuncs.com");
config.protocol = "http";
return new com.aliyun.facebody.Client(config);
}
// 创建场景识别的 Client
private com.aliyun.imagerecog.Client getImageRecogClient(String endpoint) throws Exception {
com.aliyun.imagerecog.models.Config config = new com.aliyun.imagerecog.models.Config();
config.accessKeyId = accessKey;
config.accessKeySecret = accessSecret;
config.type = "access_key";
config.regionId = "cn-shanghai";
config.endpointType = "internal";
// 这里的 config.enpoint 由外部传入,就是传入我们一开始定义的变量,格式化之后为: imagerecog.cn-shanghai.aliyuncs.com , 对应场景识别的访问域名。
config.endpoint = String.format("%s.%s", endpoint, "cn-shanghai.aliyuncs.com");
config.protocol = "http";
return new com.aliyun.imagerecog.Client(config);
}
(3)调用对应场景的 API
老规矩,看文档;示例代码永远只能是举了例子,关键部分的解释还是文档中更详细。
1. 人脸属性识别场景
文档中说了,返回的数据有很多,List,Integer之类的,他们都封装在这个叫 Data 的属性里面,那么我们调用之后就可以直接从 xxxResponse 中获取数据了。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BG86X7Lo-1591453819765)(http://image.linkaiblog.top/image-20200606214950120.png)]
但是实际上并没有想象中的怎么美好,我看了一下示例代码,发现这个 Data 里面只有一个名字叫做 elements 的对象数组,数组里面的对象是 RecognizeExpressionResponseDataElements 类的对象;然后在这个 RecognizeExpressionResponseDataElements 类里面只能够获取够获取 3 个属性:
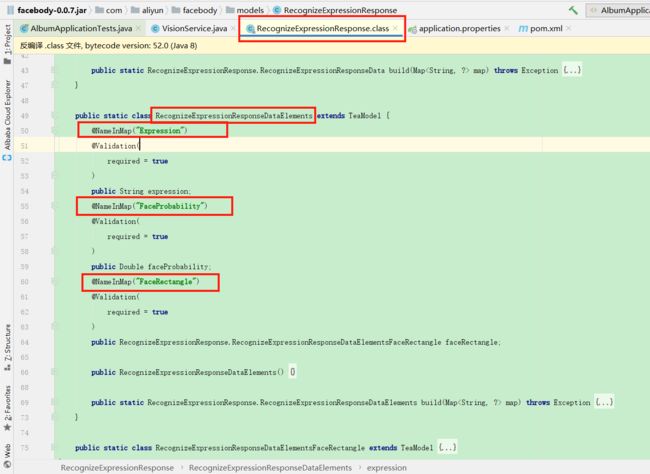
这明显和文档中的不符合啊,我个人感觉可能是依赖版本的问题,示例代码中的版本可能太低了,而文档是6月3号更新的,所以使用新版本后,应该以文档为标准;
由于临近期末,时间有限,我就不再尝试了,有兴趣的小伙伴可以测试一下新版本的SDK。
那么按照示例中的代码,这部分的代码应该这样
人脸属性识别代码 ,传入的参数为从图片获取的输入流
// 人脸属性识别主要有哪些表情
public List<String> recognizeExpression(InputStream inputStream) throws Exception {
RecognizeExpressionAdvanceRequest request = new RecognizeExpressionAdvanceRequest();
request.imageURLObject = inputStream;
List<String> labels = new ArrayList<>();
try {
// 调用我们前面的方法,获取一个 Client 对象
Client client = getFaceBodyClient(faceBodyEndpoint);
RecognizeExpressionResponse resp = client.recognizeExpressionAdvance(request, new RuntimeObject());
// 注意这里我们遍历的是 data 里面的 elements 对象数组,然后从对象中获取 expression 并放入 labels 中
for (RecognizeExpressionResponse.RecognizeExpressionResponseDataElements element : resp.data.elements) {
labels.add(ExpressionEnum.getNameByNameEn(element.expression));
}
} catch (ClientException e) {
log.error("ErrCode:{}, ErrMsg:{}, RequestId:{}", e.getErrCode(), e.getErrMsg(), e.getRequestId());
}
return labels;
}
2. 场景识别
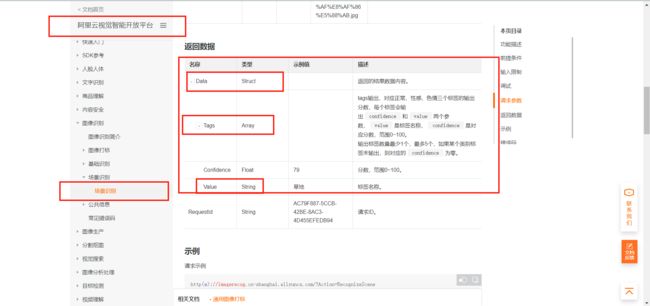
文档关键部分截图,这次文档和代码的出入比较很少,可以跟着文档来走。从 Data 中获取 Tags 进一步获取 Value
场景识别关键代码,传入的参数为从图片获取的输入流
// 场景识别部分代码
public List<String> recognizeScene(InputStream inputStream) throws Exception {
RecognizeSceneAdvanceRequest request = new RecognizeSceneAdvanceRequest();
request.imageURLObject = inputStream;
List<String> labels = new ArrayList<>();
try {
// 调用之前的方法获取一个 Client 对象
com.aliyun.imagerecog.Client client = getImageRecogClient(imageRecogEndpoint);
RecognizeSceneResponse resp = client.recognizeSceneAdvance(request, new RuntimeObject());
// 遍历 data 里面的 tags,从中获取 value 并放入 labels 中
for (RecognizeSceneResponse.RecognizeSceneResponseDataTags tag: resp.data.tags) {
labels.add(tag.value);
}
} catch (ClientException e) {
log.error("ErrCode:{}, ErrMsg:{}, RequestId:{}", e.getErrCode(), e.getErrMsg(), e.getRequestId());
}
return labels;
}
(4)测试
由于示例代码中的前端部分使用了 Vue + ElementUI,我对 Vue 不是很精通,所以我运行项目后拖入图片没有反应,F12控制里面的 Console 会报错。
所以这里直接使用本地的图片,直接调用 VisionService 类里面的方法(就是我们刚才写的那些方法)来测试
测试代码
@Autowired
VisionService visionService;
@Test
void contextLoads() {
try {
FileInputStream inputStream = new FileInputStream("D:\\Temp\\images\\5a4ca1f4ddd31.jpg");
List<String> expressions = visionService.recognizeExpression(inputStream);
for (String expersion:expressions
) {
System.out.println("人脸表情:" + expersion);
}
FileInputStream inputStream1 = new FileInputStream("D:\\Temp\\images\\5a4ca1f4ddd31.jpg");
List<String> recognizeScene = visionService.recognizeScene(inputStream1);
for (String scene:recognizeScene
) {
System.out.println("对应场景:" + scene);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
}
本地图片
最中的识别结果:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JySCE4FR-1591453819777)(http://image.linkaiblog.top/image-20200606212453730.png)]
关于
由于前端代码出现了Bug,所以只测试了后端调用服务API的关键代码,主要是结合代码和文档一起分析,这样才能一通百通。额,好吧,最主要的原因是时间不够,月底就期末考了,能抽出来的时间不是很多,所以不想把时间花费在解决前端的Bug上面。
友情推广
贴一下阿里云的活动,有兴趣的小伙伴可以参加一下
