智能问答系统:问句预处理、检索和深度语义匹配技术
更多干货内容敬请关注「平安寿险PAI」(公众号ID:PAL-AI),文末有本期分享内容资料获取方式。
智能问答系统是人机交互的核心技术之一,常见的应用场景主要是智慧客服。通过构建该系统,机器人可以快速找到与用户问题相匹配的答案并自动回答,从而大大减少企业的人力成本;除了提供专业领域的问答功能外,还可实现闲聊、私人助手等问答服务。
尽管业界在智能问答领域已经取得了令人瞩目的成就,但是智能问答系统还远未完美,在知识获取和对用户问句理解等核心技术上仍有较大的提升空间。
3月14日,由平安寿险AI团队在Paper Weekly直播间进行的主题为「智能问答系统」的技术分享,由资深算法工程师谢舒翼主讲,其内容分5个部分:
- 寿险的智能问答系统整体框架介绍
- 问句预处理核心技术
- 检索和深度语义匹配技术
- 基于深度学习的问答排序算法介绍
- 算法效果评估方案
分享老师:谢舒翼
平安人寿智能平台团队资深算法工程师。北航计算机系本硕,ACMer,Topcoder,多次获得各类编程赛冠军、数学竞赛一等奖。曾在百度、MSRA实习,任职于阿里巴巴,现为平安寿险人工智能研发团队资深算法工程师,主要研究方向为智能问答系统、知识图谱、NLP 相关算法。
以下是根据本期技术分享内容整理的文字稿。
一、框架介绍
首先介绍平安人寿智能问答引擎算法架构,如下图:

从问题输入开始,这里包括用户的问题以及语境中心提供上下文,其中包含用户的历史对话信息以及一些关于用户意图的结构化数据。
用户的问题输入后,首先进入预处理模块。在预处理模块里,分词、词性标注、实体识别都是比较成熟的技术,配合业务专用名词词典,我们采用Hanlp工具来做;多意图识别则用分类来做,主要处理用户一句话里有多个问题的意图,并给予不同的回答;问句改写主要是对保险名词的缩写和全称做改写;情感分析主要是通过句法分析去判断用户的话语是肯定意图或是否定意图。
预处理结束后,会进入检索模块。如果预处理经过纠错和问句改写,就会是多个query并行进入检索,触发ES字面检索和深度语义匹配。经过这两个检索模块得到的答案后,我们会从知识库以及Redis本地存储,把答案拿到后做多路结果归并。然后简单计算字面得分、语义得分、关键词得分,编辑距离作为LR的feature。
还有保险实体对齐,主要是重要名词、疾病、地区等的对齐。在排序模块里,比如用户问的问题是关于A保险,匹配的答案是B保险,处理的方式是在实体对齐的时候把答案去除,剩余的答案会做深度语义精排。
排序后,就进入输出模块。在输出模块里,有直接问输出、推荐问输出等,如果阈值比较低,还会做问句澄清。在输出模块,关联问可能会用到用户画像。
二、问句预处理核心技术
1. 长难句
为什么需要做长难句?因为用户在进行语音输入时,可能会提交一段很长的话(如下图示例),而一般在知识库里检索的标准问其实是比较精短的。用比较长的用户问题去匹配一个比较短的问题,算法上存在一定困难,因此我们会进行长难句的句子压缩。

做长难句的句子压缩比较直观的一种方法是语法树分析+关键词典。
- 第一步,通过标点或空格分割长句成若干个短句,然后对短句分类,去掉口水语句。
- 第二步,基于概率和句法分析的句子压缩方案,只保留主谓宾等核心句子成分。配合保险关键词典,确保关键词被保留。
关于句子压缩通用的方法分为两种:一种是抽取式(extractive),另一种是生成式(abstractive)。
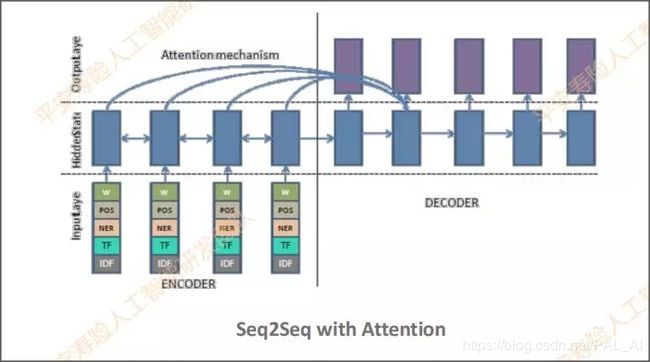
从传统的TextRank抽取式,到深度学习中采用RNN、CNN单元处理,再引入Attention、Self-Attention、机器生成摘要的方式,这些方式跟人类思维越来越像,都建立在对整段句子的理解之上。与此同时,生成摘要的效果,也常常令人惊艳。
- 抽取式:即压缩之后的句子,所有的成分都来自原来用户提问的句子。
- 生成式:主要基于带有Attention模型的seq2seq实现的。简单描述的话,它可以被看作一个概率模型。概率模型可以确定哪些词保留、删除或被改写。这里用到copynet和pointer-generate这两个思路,去解决OOV和低频词的问题,效果比较显著。
去年ByteCup赛题是对文章生成摘要,其中冠军方案是基于transformer去做的。该方案在原先的transformer的Encoder端加了NER和POS特征,得到了较好的效果。
2. 纠错
纠错模块主要是为了处理用户输入出现错别字的情况,因为错别字可能会对后面的模型识别造成影响,所以需要先进行纠错动作。
比较直观的做法是基于字典和规则的纠错。在寿险的业务场景里,保险名词是非常重要的,所以基于字典主要指的是是基于保险关键词的字典。
如下图例子,“在背景哪里可以买一生保”,其中“一”(应为“e”)是一个错别字。根据字典可以将这个错别字纠出来,但“背景”(应为“北京”)在此之中是无法被纠错的。

因此我们做了基于Transformer的通用纠错模型。这个思路是,在Encoder端输入句子的拼音以及相对比较关键的词,这个关键词与词典匹配的话,就无需再转成拼音。经过纠错模型后,Decoder端将拼音转成汉字。
这块的训练数据集主要用到寿险已落地应用的智慧客服的一些线上日志,经过标注的形成文本训练集。
3. 指代消解
有时候用户的问题是带上下文信息的。比如,用户第一句话问,“感冒可以投保平安福吗?得到回答后,用户可能会接着问,“那癌症呢?”
第二句话“那癌症呢?”其实缺少动词和宾语,单单把这句话放到后面的匹配算法中,或许无法得到比较精确的答案,所以需要通过指代消解的方案做问句补全。例如可以用“癌症”去替换上文的“感冒”,然后得到一个指代消解的输出结果,即“癌症可以投保平安福吗?”
其实现思路是:分词→词性标注→依存句法分析→主谓宾提取→实体替换/指代消解
比如下面的例子,第一句话中,“感冒”与“投保”是一个主谓关系,“可以”与“投保”是一个状中关系,“平安福”和“投保”又是动宾关系,其中,投保是一个核心词。

这块基于策略的方案,其能够解决的问题也是有限的,目前主要是用来解决一些保险实体或者是疾病名称(如下图例子)。

下面介绍业界通用方案的三种思路:
- Mention Pair models:将所有的指代词(短语)与所有被指代的词(短语)视作一系列pair,对每个pair二分类决策成立与否。
- Mention ranking models:显式地将mention作为query,对所有candidate做rank,得分最高的就被认为是指代消解项。
- Entity-Mention models:一种更优雅的模型,找出所有的entity及其对话上下文。根据对话上下文聚类,在同一个类中的mention消解为同一个entity。但这种方法其实用得不多。

首先把先行词候选项的embedding放到输入层,然后将先行词feature,即当前词的前、后词embedding放入输入层。
Mention是用word embedding作为输入,Mention Features是用Mention前后的词,Additional Features考虑到的比较重要的因素是距离因素。
有一个很直观的思路是,代消解项和前面的先行词,肯定是离代消解项比较近的词,作为正确消解的概率会更大一些。
中间经过前馈的神经网络,用的是Relu激活函数。损失函数主要是用max martin,其实也是hinge loss的变种。这里用了一个分段的损失函数,同时涉及到一个增强学习的reward方法。
三、检索和深度语义匹配技术
1. ElasticSearch字面检索
目前字面检索用的是ElasticSearch,这是一个基于lucene的高可用分布式开源搜索引擎。
除了ElasticSearch外,其实还有Solr搜索引擎。选择前者的原因是,在处理实时的搜索应用时,ES的效率明显比Solr要高。线上的产品其实对运行时间有较高的要求,整个系统跑下来要求控制在100毫秒以内。
我们会根据知识库去建立所有数据的索引,同时支持一些分类和机构的查询。
其中ES的分词进行了统一配置的动作,里面配置了保险专用名词和同义词。ES默认为TFIDF的算法,但也支持BM25的算法。ES搜索结果的得分则会被零到一的归一化以及分片优化。
2. 孪生网络
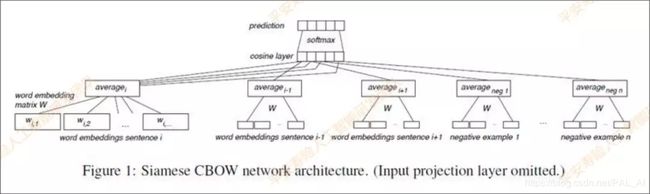
接下来介绍深度语义匹配模块,其中主要使用的是孪生网络Siamese CBOW。
词向量会得到预训练,然后用求和取平均的方式来表征句向量,对标准问和相似问进行训练,添加负采样,损失函数为Contrastive Loss,让正样本之间的句向量表征尽量相似。预先算出语料的所有句向量表征,将用户问题通过模型转化成句向量,搜索语料里最相似的若干个句向量作为候选答案列表。
而孪生网络的优化点,首先是word embedding,寿险这边的线上系统主要使用的是词向量及字向量。
关于字向量,这里推荐一篇论文:《Character-based Neural Networks for Sentence Pair Modeling》2018, character-based ngram。
直观来看词向量和字向量的区别,词的表达能力比字强。日常常用汉字为6000-7000,但词的组合有很多种。
实验发现,在样本足够多的情况下,用词向量的效果一般会更好;但如果样本很小,则应选择用字向量。
这里提到上下文词向量,这是去年NLP界比较火的技术,包括Elmo、GPT以及谷歌Bert,它们主要提供的是经过海量语料训练的可迁移模型。
而关于带上下文的词向量,在此之前,word2vec不能很好的表示一词多义的问题。经过Elmo语言模型后,不同的上下文同一个词的word embedding可能是不一样的。
后面要做的是知识清洗,输入的数据源和训练数据源必须保证是准确的。
再就是做数据扩充,上文也提到可以引入预训练的Bert模型更强的表征。
对于孪生网络,两边的模型除了CBOW以外,也可以支持LSTM、RNN、CNN。
一个小优化点是,网络output的位置可以使用Attention,而不是直接对每个时刻的输出求均值。
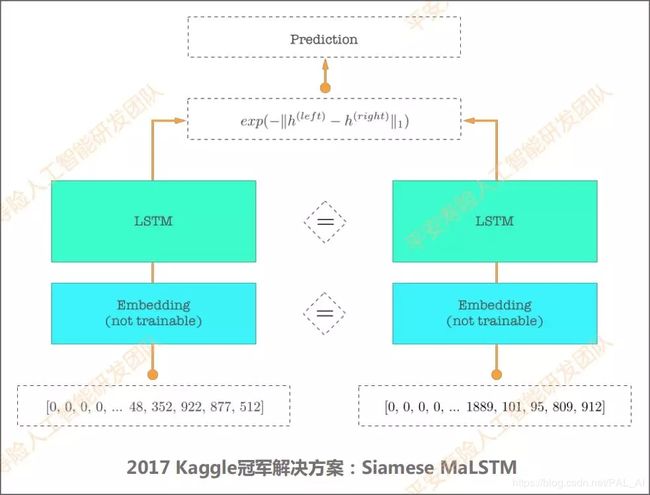
下图是2017年Kaggle问答比赛的冠军方案,该方案其实是在孪生网络的模型框架下用了曼哈顿LSTM,从而达到了一个最优效果。
3. BERT for QA
BERT这一块的主要工作是,在BERT之后做一层微调。我们会自定义Fine-tune这块的Processor,然后把BERT表征之后的句向量再接一个孪生网络进行训练。
实验结果显示,加入BERT表征会比之前存的词向量准确率提升3个点左右。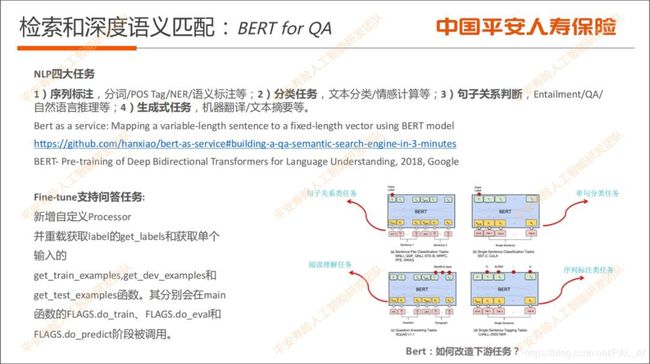
4. 交互矩阵
前文提到的孪生网络Siamese CBOW其实是一个表示模型。深度语义匹配除了表示模型以外,还有一类是交互模型。从论文看,前面一种叫做representation model,后面这种交互模型主要是叫interaction model。
这里先简单介绍交互模型MatchPyramid的思路,其主要是借鉴了CNN的处理图像时的原理,因为CNN就是在提取像素、区域之间的相关性,进而提取图像的特征。
假设有两句话,需要计算两句话的相似度。第一句话有M个单词,第二句话有N个单词,那么它们的相似度矩阵就是MN。MN里面的数字怎么确定呢?
-
第1种方案,如果单词相同就是1,否则为0
-
第2种方案,计算词向量的余弦距离
-
第3种方案,计算词向量的内积
表示成相似度矩阵之后,就可以通过卷积提取feature map,再通过最大池化max pooling去抽取一些更高维的特征,最后再经过多层感知机得到相似度匹配得分。
5. MatchZoo
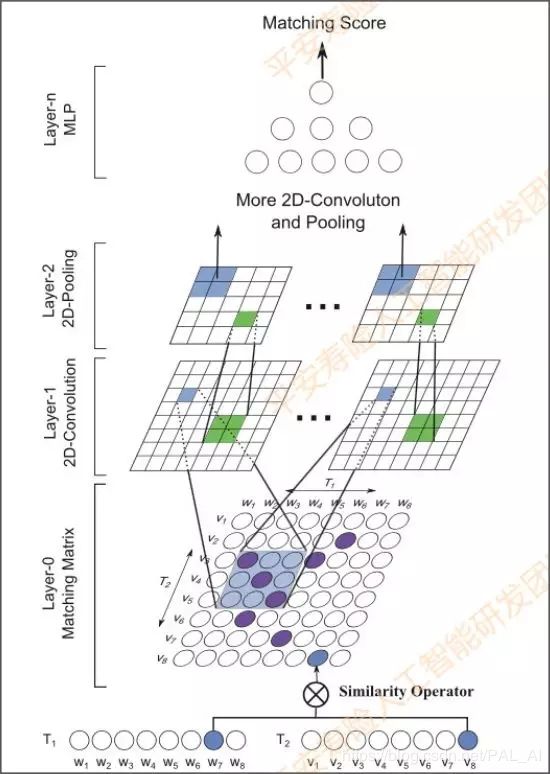
这里给大家推荐一个优秀的开源工具:MatchZoo,这是一个开源的Python环境下基于TensorFlow开发的文本匹配工具,实现了主流的20多种深度语义匹配算法。其主要用Keras实现,代码结构非常好。
我们也基于这个工具,做了MV-LSTM,ESIM的算法。
6. 知识库和知识指引
下面介绍一下检索算法。通过语义搜索和句向量的表达之后,需要从已建好的语义向量索引里,搜索最近邻的N个答案。
-
Annoy搜索算法:建立一个数据结构,使得查询一个向量的最近邻向量的时间复杂度是次线性。二叉树,随机选2个点聚类,超平面分割。同一批数据建立多棵树,检索答案合并排序。
-
小问题:第一次查询的速度比较慢;近似算法,准确率逼近100%。
四、基于深度学习的问答排序算法介绍
1. Deeprank
通过索引可以得到若干个答案,将这若干个答案合并去除重复的答案之后,就进入排序模块。接下来将详细介绍我们采用的深度学习排序算法。
-
使用n-gram 窗口,可以捕捉更长的上下文语义
-
将query和document 的语义向量及其相似度拼接成新的特征向量输入 MLP 层进行 learning to rank
-
可以在 learng2rank 模型的输入向量中方便地融入外部特征
-
支持 end-to-end 的 matching + ranking 任务
首先做分词,每一个词向量的维度矩阵就是sentence matrix这个矩阵高度。一列其实就是一个单词的word embedding,然后把每一个单词的word embedding拼接起来就变成我们需要的sentence matrix。
sentence matrix出来之后,会经过好几个过滤器去提取特征,例如下图是用tri-gram来提取。

把这些特征提取之后拼接在一起,有多个Filter的话就会生成多个Feature maps。多个卷积Feature maps提取好之后,会经过pooling层,把每个Feature maps做Pooling后,再把Pooling拼接到一起。
中间看到的Similarity Matching有个矩阵M。矩阵M是在模型里是通过参数训练得到的;Xd是用户匹配的问题;Xq是用户问题经过Pooing后提取的特征。
通过XdMXq得到Xsim,得到Join Layer。除了Xsim向量以外,Join Layer还会有额外Feature,包括TFIDF的特征、两句话之间共现词的特征,还有其他统计的特征。
实验发现,共现词特征其实影响比较大,加上这个特征之后大概会有2-3个点的提升。
过了join Layer之后,最后那层是隐层,也是一个MLP多层感知机,最后经过softmax就会得到答案。
- 排序打分方案
打分方案主要分5级打分,S、A、B、C、D:S=完全匹配,A=非常相关,B=相关,C、D基本上不怎么相关。

该排序打分模型支持对pointwise和pairwise方法进行训练。假设只是pointwise,就看用户的问题跟匹配的问句是否相关;pairwise的话,就看用户匹配的两个问题,针对用户的query到底哪个更加相关。
2. DRMM+PACRR
下面再介绍一个state of art的方法,是去年谷歌提出的DRMM+PACRR的排序方案,这个方法目前还在实验中。
这个方案的主要思路也是先做卷积,但不一样的是它会做两层池化:首先是max pooling,然后是row-wise max pooling,再将两层拼接,经过全连接层。使用相同的MLP网络独立地计算每一个q-term encoding(矩阵的每一行)的分数,再通过一个线性层得到query与doc的相关性得分 。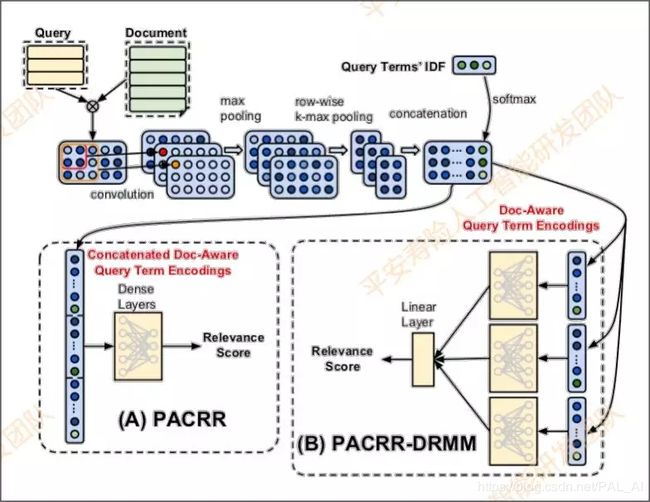
五、算法效果评估方案
1. 话术澄清
排序结束后,根据用户问题最相关的答案得分从高到低做排序,然后到输出层。
假设排序最高得分的答案置信度不够高,就会触发话术澄清,然后让用户确认是否在问这样的问题。
例如下面介绍的意图图谱,就是意图不明确的时候可以反问用户以确认,可应用在任务型机器人,也可用于QA。
意图图谱的节点代表一个个意图节点。这些“意图”之间的关系包括**需求澄清(disambiguation)、需求细化(depth extension)、需求横向延展(breadth extension )**等。
下图所示的例子中,当“阿拉斯加”的意思是“阿拉斯加州”时,与之关联的意图是城市、旅游等信息。当“阿拉斯加”的含义是“阿拉斯加犬”时,它延伸的意图是宠物狗、宠物狗护理,以及如何喂食等。
假设用户问“哪里可以买到阿拉斯加犬”,那“阿拉斯加”必定代表“阿拉斯加犬”;如果用户问“阿拉斯加今天的天气如何?”,那“阿拉斯加”必定代表“阿拉斯加州”。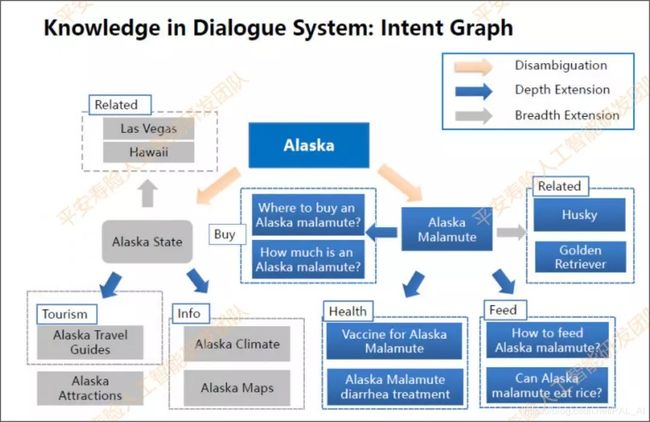
2. 自动化测试框架+验证集+效果评估
做完话术澄清后,结合答案的输出结果,根据业务需求可以提供:
-
直接回答:提供Top1答案
-
推荐问:提供Top3答案
-
关联问:基于大数据推荐算法挖掘
-
搜索式问答:非保险类问题,答案可以来自网络wiki
-
闲聊:结合检索式+生成式模型两种方式。我们有10万检索语料,如果用户闲聊问题命中了检索语料,就直接给答案,如果没有命中,而且是非专业问题,就用生成模型给用户生成一个答案。
以下是问答评估指标:
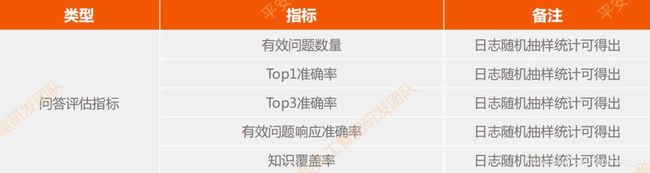
关于效果评估主要有五大验证集和测试集。测试集主要是调好的模型,去测试准确率相关的指标;验证集主要是模型调参。
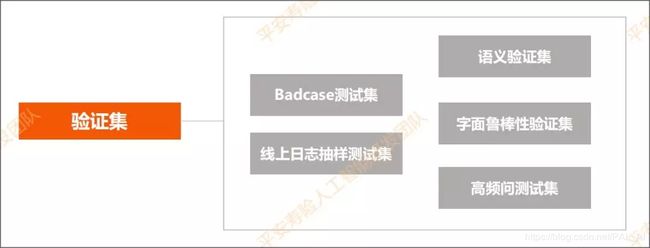
测试集主要依靠以下方式获得:
-
Badcase测试集:依靠日常业务体验,或者亲自体验和不断进行测试,发现bad case并收集起来并且不断累积。
-
线上日志抽样测试集:每周从线上日志抽样,获得最新的用户问题做标注。
-
高频问测试集:基于大量数据进行高频问统计。不管模型或算法有改动,都会跑高频问测试集,保证Top100高频问准确率100%。
-
字面鲁棒性验证集:根据知识库语料,用算法删除里面的非关键词,或增加一些噪音,又或者把里面的同义词做转换等等,有十几种方式生成字面鲁棒性验证集。这里主要是测模型的间断性。
-
语义验证集:根据业务需求,做全面的测试样例覆盖,再根据有特点的线上日志做标注抽样。
六、附录:
- 附录1:迁移学习
迁移学习解决的问题主要是,在数据集非常少的场景下,可以用作问答训练的语句非常少,就需要从数据集大的场景已经训练好的模型做迁移学习。
这里推荐ACL2018的论文。这个迁移学习在问答系统上的创新,准确率比state of art模型略低,但比单纯的表示模型高,比QPS高,同时支持大规模线上系统。
它在传统迁移学习的框架上,引入了半正定协方差矩阵,对输出层的域内以及域间信息权重进行建模;引入对抗损失,增强shared 层的抗噪能力。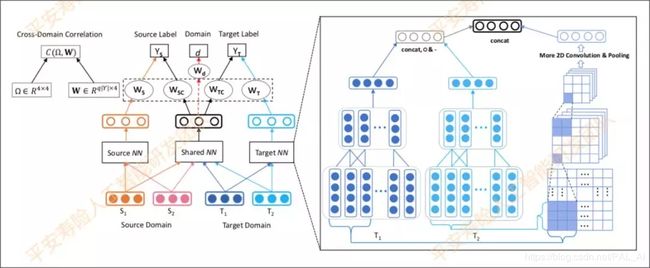
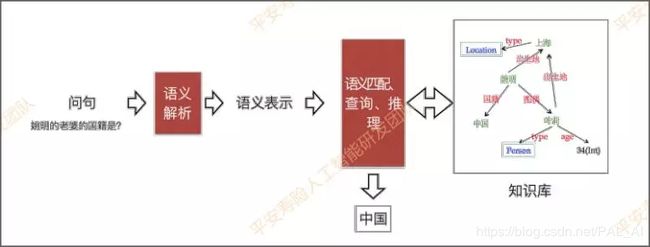
- 附录2:基于知识图谱的问答——KBQA
基于知识图谱的问答模块,需要解决两个核心问题:①如何理解问题语义,并用计算机可以接受的形式进行表示(问题的理解和表示);②以及如何将该问题表示关联到知识图谱的结构化查询中(语义关联)。
前文提到的Siamese CBOW模型是对词向量相加求平均。
举个例子: “谢霆锋的爸爸是谁?”和“谢霆锋是谁的爸爸?” 这两个问题,分词之后词是完全一样的,如果用词向量相加求平均,最后得到的句向量一样,无法区分。而知识图谱可以解决简单逻辑推理的问题。
-
基于模版的方法:自然语言查询–>意图识别(Intention Recognition)–>实体链指(Entity Linking)+关系识别(Relation Detection) -->查询语句拼装(Query Construction)–>返回结果选择(Answering Selection)
-
基于语义解析的方法
-
基于神经网络的方法
-
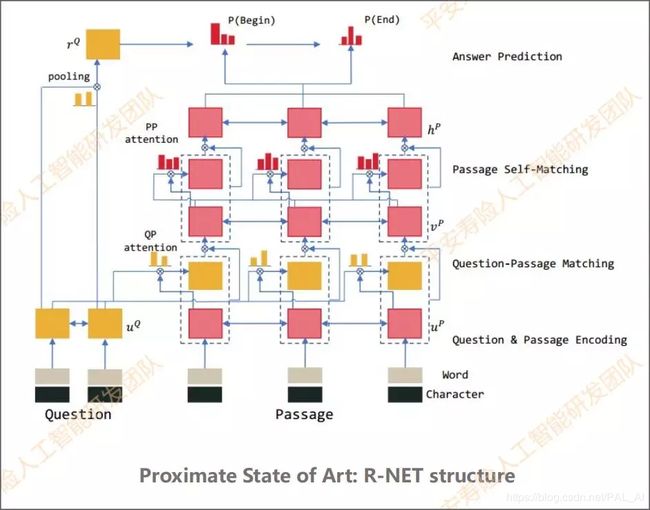
附录3:阅读理解式问答
基于阅读理解的问答,适用数据类型为(给定一个问题Q和一个与Q相关的文档D,自动得到Q对应的答案A)非结构化文本,主要的方法有匹配式,抽取式和生成式。
-
匹配式:给出文章、问题和答案集,从答案集中选出最高得分的答案,像选择题。例如Attentive-reader、Impatient-reader。
-
抽取式:即从文档中抽取出答案,前提是文档中包括问题答案。抽取式的一般框架是:Embedder+Encoder+Interaction-layer+Answer。主要模型有Match-LSTM、R-NET、BiDAF。
-
生成式:其答案形式是:①答案完全在某篇原文;②答案分别出现在多篇文章中;③答案一部分出现在原文,一部分出现在问题中;④答案的一部分出现在原文,另一部分是生成的新词;⑤答案完全不在原文出现(Yes / No 类型)。常见模型:改进的R-Net、S-NET、R3-NET。
-
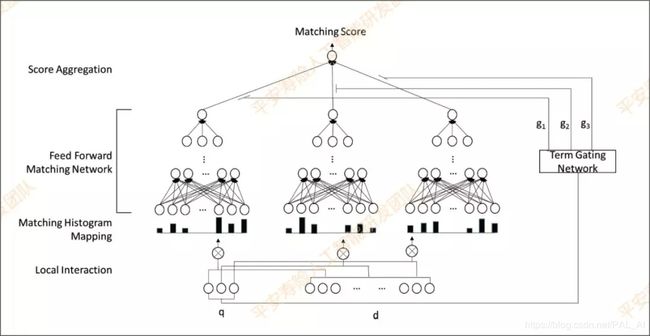
附录4:DeepRank
深度语义排序模型介绍,主要解决相关度排序(relevance matching)。
DRMM:Deep relevance matching model. Relevance matching is different from semantic matching!
1.Matching Histogram Mapping
2.Feed forward Matching Network
3.Term Gating Network
Semantic matching vs Relevance matching: 根据query去找到相关性更大的documents,这里的相关性可以理解为相同关键字,相同主旨等等,但是句式(问句&答句),长短(短查询&长文本)等等可能都不相同。
semantic matching忽略了查询术语的重要性,而NLP的matching tasks则是指两句话的大意相同,matching tasks是更严谨的一种matching。
1.输入:query中的每个词和doc所有词产生term pair,对于每一个pair使用相似度计算,按照得分区间来统计直方图的个数
2.前馈神经网络:Zi = tanh(WiZi-1+b)
3.对于每个query词产生的zi,最后通过一个gating network gi 生成最后的分数,类似于注意力机制,s=sigma(GiZi),Gi权重通过学习得来
(参考论文:A Deep Relevance Matching Model for Ad-hoc Retrieval)
资料获取
本期直播视频及资料获取方式如下:
1 / **扫码关注「平安寿险PAI」
2 / 后台回复“智能问答系统”即可获取下载链接