MPI编程——分块矩阵乘法(cannon算法)
要求:




分析
本题难点在于不同process之间的通信,算法主要利用了cannon算法,cannon算法描述如下:

以上算法主要分为两个过程:分配初始位置、进行乘-加运算、循环单步移位。为了方便,下面以p = 9时的3*3矩阵为例:
初始化
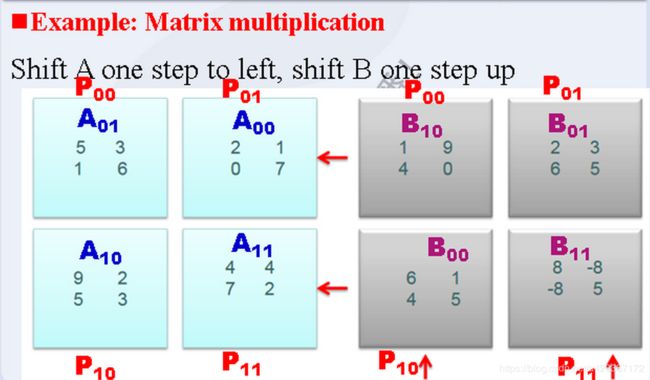
根据以上描述,A向左循环移动i位,做如图操作:
| A(0,0) | A(0,1) | A(0,2) | |
| A(1,0) | A(1,1) | A(1,2) | ← |
| A(2,0) | A(2,1) | A(2,2) | ←← |
以上操作,对于每一行,将列坐标做 j - i 操作,当操作小于零时,加上rootp(根号p)用来循环移位。
而在mpi中实现是借助mpi通信函数,其中发送函数需要指明dest,接收函数需要指明source,所以我需要计算dest即rank_next_a,公式如下:
//其中myrank是当前进程号,rootp是指根号p
curRowP = myrank / rootp;//当前节点所在行i
curColP = myrank%rootp;//当前节点所在列j
//获得左移i步后的节点号
//左移后的列坐标为j - i(小于0时加rootp补齐)
if ((curColP - curRowP)<0)
{
rank_next_a = myrank + rootp - curRowP;
}
else
{
rank_next_a = myrank - curRowP;
}而source(即rank_last_a)的计算方法如下:
if ((curColP + curRowP) >= rootp)
{
rank_last_a = myrank + curRowP - rootp;
}
else
{
rank_last_a = myrank + curRowP;
}对于矩阵B,做如下操作:(对于每一列,将行坐标做 i - j 操作,注意小于零时需要补齐)
| B(0,0) | B(0,1) | B(0,2) |
| B(1,0) | B(1,1) | B(1,2) |
| B(2,0) | B(2,1) | B(2,2) |
| ↑ | ↑↑ |
图中每小块对应进程如下:
| p0 | p1 | p2 |
| p3 | p4 | p5 |
| p6 | p7 | p8 |
所以,对于rank_next_b,公式如下:
if ((curRowP - curColP)<0)
{
rank_next_b = myrank - curColP*rootp + rootp*rootp;
}
else
{
rank_next_b = myrank - curColP*rootp;
}同理,可以获得rank_last_b。
接下来我们就可以进行进程的相互通信了,但需要注意的是,若完全使用MPI阻塞函数进行通信,会出现环路等待,造成死锁。为了解决这个问题,MPI提供了MPI_Isend和MPI_Irecv函数。使用时需要注意:
由于非阻塞通信在调用后不用等待通信完全结束就可以返回,所以非阻塞通信的返回并不意味着通信的完成。在返回后,用户还需要检测甚至等待通信的完成。MPI提供了MPI_Wait函数来完成该目的。则初始化的流程如下:
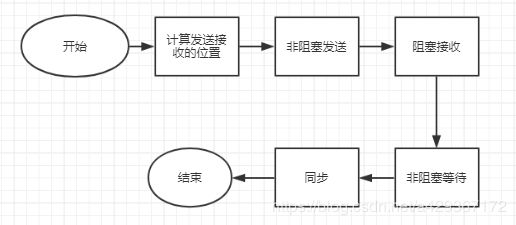
计算循环单移位坐标并计算
理解了如何初始化化,那么循环就好理解了,由于循环过程中每次都是0进程->1进程->2进程->0进程,所以我们发送接收进程号不用每次都计算,计算一次即可。
类比初始化的过程rank_next_a、rank_next_b、rank_last_a、rank_last_b的计算如下:
if (myrank%rootp == 0)//第一列的节点
{
rank_next_a = myrank + rootp - 1;
}
else
{
rank_next_a = myrank - 1;
}
if (myrank / rootp == 0)//第一行的节点
{
rank_next_b = myrank + rootp*(rootp - 1);
}
else
{
rank_next_b = myrank - rootp;
}
if (myrank%rootp == (rootp - 1))//最后一列的节点
{
rank_last_a = myrank - rootp + 1;
}
else
{
rank_last_a = myrank + 1;
}
if (myrank / rootp == (rootp - 1))//最后一行的节点
{
rank_last_b = myrank - rootp*(rootp - 1);
}
else
{
rank_last_b = myrank + rootp;
}需要注意的地方
我们平时swap数据的时候,通常会加一个tmp,不然原始数据会被覆盖掉,从而交换失败,而在这里,我们利用非阻塞通信的时候,数据交换我们也需要加一个buf,而在这里buf的作用是将交换完成之后的数据存到buf中,以此来完成通信,而下一次交换,将原数据作为buf,buf作为原数据,如此交替使用,我们在这里要加一个tag标记我们正确的数据存在哪里。
cannon代码
//A and bufA : n1_block*n2_block; B and bufB : n2_block*n3_block
//进行cannon算法,各个节点在本地进行矩阵乘法,并交换矩阵块,进行循环,直到计算完毕
void cannon(double* A, double* bufA, double* B, double* bufB, double* C, int n1_block, int n2_block, int n3_block, int rootp)
{
MPI_Request send_a_req, send_b_req;
MPI_Status send_a_status, send_b_status, recv_a_status, recv_b_status;
int cycle_count;
int rank_next_a, rank_next_b;
int rank_last_a, rank_last_b;
int curRowP, curColP, i, j;
int tag = 0;//表示当前正确数据再A中还是bufA中,0表示在A中,1表示在bufA中
//先初始化各个块,即A_ij循环左移i步,B_ij循环上移j步,C_ij初始化为零
//初始化矩阵C,值全部设为0
for (i = 0; i= rootp)
{
rank_last_a = myrank + curRowP - rootp;
}
else
{
rank_last_a = myrank + curRowP;
}
//获得接受上移j步的节点号
if ((curRowP + curColP) >= rootp)
{
rank_last_b = myrank + curColP*rootp - rootp*rootp;
}
else
{
rank_last_b = myrank + curColP*rootp;
}
//非阻塞发送矩阵,如果不需要移动,则直接本地memcpy
if (rank_next_a != myrank)
{
MPI_Isend(A, n1_block*n2_block, MPI_DOUBLE, rank_next_a, 0, MPI_COMM_WORLD, &send_a_req);//非阻塞发送矩阵A,避免死锁
}
else
{
memcpy(bufA, A, n1_block*n2_block * sizeof(double));//本地直接memcpy
}
if (rank_next_b != myrank)
{
MPI_Isend(B, n2_block*n3_block, MPI_DOUBLE, rank_next_b, 0, MPI_COMM_WORLD, &send_b_req);//非阻塞发送矩阵B,避免死锁
}
else
{
memcpy(bufB, B, n2_block*n3_block * sizeof(double));//本地直接memcpy
}
//阻塞接受矩阵
if (rank_last_a != myrank)
{
MPI_Recv(bufA, n1_block*n2_block, MPI_DOUBLE, rank_last_a, 0, MPI_COMM_WORLD, &recv_a_status);//阻塞接受矩阵A
}
if (rank_last_b != myrank)
{
MPI_Recv(bufB, n2_block*n3_block, MPI_DOUBLE, rank_last_b, 0, MPI_COMM_WORLD, &recv_b_status);//阻塞接受矩阵B
}
//阻塞等待发送矩阵结束
if (rank_next_a != myrank)
{
MPI_Wait(&send_a_req, &send_a_status);//阻塞发送矩阵A到结束
}
if (rank_next_b != myrank)
{
MPI_Wait(&send_b_req, &send_b_status);//阻塞发送矩阵B到结束
}
MPI_Barrier(MPI_COMM_WORLD);//同步
tag = 1;
if (myrank%rootp == 0)//第一列的节点
{
rank_next_a = myrank + rootp - 1;
}
else
{
rank_next_a = myrank - 1;
}
if (myrank / rootp == 0)//第一行的节点
{
rank_next_b = myrank + rootp*(rootp - 1);
}
else
{
rank_next_b = myrank - rootp;
}
if (myrank%rootp == (rootp - 1))//最后一列的节点
{
rank_last_a = myrank - rootp + 1;
}
else
{
rank_last_a = myrank + 1;
}
if (myrank / rootp == (rootp - 1))//最后一行的节点
{
rank_last_b = myrank - rootp*(rootp - 1);
}
else
{
rank_last_b = myrank + rootp;
}
//循环,每次做当前块的乘加运算,并使得A_ij循环左移1步,B_ij循环上移1步
for (cycle_count = 0; cycle_count < rootp; cycle_count++)
{
if (tag == 1)//数据在bufA中
{
matmul(bufA, bufB, C, n1_block, n2_block, n3_block);//做当前节点的矩阵乘法
//循环传播小矩阵
MPI_Isend(bufA, n1_block*n2_block, MPI_DOUBLE, rank_next_a, 0, MPI_COMM_WORLD, &send_a_req);//非阻塞发送矩阵A,避免死锁
MPI_Isend(bufB, n2_block*n3_block, MPI_DOUBLE, rank_next_b, 0, MPI_COMM_WORLD, &send_b_req);//非阻塞发送矩阵B,避免死锁
MPI_Recv(A, n1_block*n2_block, MPI_DOUBLE, rank_last_a, 0, MPI_COMM_WORLD, &recv_a_status);//阻塞接受矩阵A
MPI_Recv(B, n2_block*n3_block, MPI_DOUBLE, rank_last_b, 0, MPI_COMM_WORLD, &recv_b_status);//阻塞接受矩阵B
MPI_Wait(&send_a_req, &send_a_status);//阻塞发送矩阵A到结束
MPI_Wait(&send_b_req, &send_b_status);//阻塞发送矩阵B到结束
tag = 0;
}
else //数据在A中
{
matmul(A, B, C, n1_block, n2_block, n3_block);//做当前节点的矩阵乘法
//循环传播小矩阵
MPI_Isend(A, n1_block*n2_block, MPI_DOUBLE, rank_next_a, 0, MPI_COMM_WORLD, &send_a_req);//非阻塞发送矩阵A,避免死锁
MPI_Isend(B, n2_block*n3_block, MPI_DOUBLE, rank_next_b, 0, MPI_COMM_WORLD, &send_b_req);//非阻塞发送矩阵B,避免死锁
MPI_Recv(bufA, n1_block*n2_block, MPI_DOUBLE, rank_last_a, 0, MPI_COMM_WORLD, &recv_a_status);//阻塞接受矩阵A
MPI_Recv(bufB, n2_block*n3_block, MPI_DOUBLE, rank_last_b, 0, MPI_COMM_WORLD, &recv_b_status);//阻塞接受矩阵B
MPI_Wait(&send_a_req, &send_a_status);//阻塞发送矩阵A到结束
MPI_Wait(&send_b_req, &send_b_status);//阻塞发送矩阵B到结束
tag = 1;
}
MPI_Barrier(MPI_COMM_WORLD);//同步
}
return;
} 其中使用的matmul代码如下:
// Compute C = A*B. A is a n1*n2 matrix. B is a n2*n3 matrix.
void matmul(double* A, double* B, double* C, int n1, int n2, int n3)//做矩阵乘法,结果累加到C矩阵中(需要保证C矩阵初始化过)
{
int i, j, k;
//简单的串行矩阵乘法
for (i = 0; i < n1; i++)
{
for (j = 0; j < n3; j++)
{
for (k = 0; k < n2; k++)
{
C[i*n3 + j] += A[i*n2 + k] * B[k*n3 + j];
}
}
}
}所有代码见:
https://github.com/a429367172/mpi_hadoop
maxtrix.cpp文件
文章参考:
1.Cannon算法的原理实现以及性能评测
https://blog.csdn.net/cncyww/article/details/80727732
2.PI_Isend与MPI_Irecv小例子
https://www.jianshu.com/p/c27d1e2ab458