Hadoop-2.6.5集群安装配置
Hadoop本身的安装配置过程比较简单,主要精力在于服务器环境的配置上。
一、服务器基础软件
由于机器有限,我在笔记本上使用VMware虚拟了出两台虚拟机来跑。一台作为名字节点(nameNode),一台作为数据节点(dataNode),勉强用着。
虚拟机操作系统版本:RedHat Linux 6.4(64-bit)
需要安装的服务:openssh,包括服务端和客户端(一般都自带有)
二、设置静态IP
将两台虚拟机修改为局域网的静态IP,可以修改网络配置问,也可以直接在Linux图形界面进行配置。
网络地址配置文件:/etc/sysconfig/network-scripts/ifcfg-eth0
我的两台虚拟机静态IP为:
192.168.205.193 255.255.255.0 192.168.205.1
192.168.205.165 255.255.255.0 192.168.205.1
三、设置主机名
RedHat的主机名配置文件位置为 /etc/sysconfig/network下,修改此文件的HOSTNAME即可。如下图:
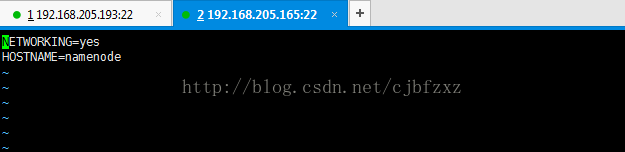
我将165的机器主机名设为namenode,193的机器主机名设为datanode1
四、设置hosts文件主机名与IP的映射
修改/etc/hosts文件,添加主机名与IP的映射,通过主机名访问服务器。

注意需要将每个节点的主机名都加入到hosts文件中。
五、配置ssh公钥免密登录
在Hadoop集群环境中,nameNode节点需要能够ssh无密码访问dataNode节点。
1、生成公钥秘钥对
使用命令:ssh-keygen -t rsa
如看到图形输出,说明生成成功。生成的秘钥文件在~/.ssh目录下。
使用命令进入该目录: cd ~/.ssh,看到两个秘钥文件:
私钥文件:id_rsa
公钥文件:id_rsa.pub
2、将公钥文件内容放入到authorized_keys中
使用命令:cat id_rsa.pub >> authorized_keys
目录下回生成authorized_keys文件。
3、分发authorized_keys文件到各dataNode节点
使用命令:scp authorized_keys root@dataNode:/root/.ssh/
也可以直接将该文件拷贝到dataNode对应的目录下。
ps:我自己的一个小技巧:先将一台虚拟机按照上述步骤配置好,然后直接克隆这台机器作为另外一台虚拟机,修改下ip和主机名即可。
4、验证无密码登录
使用命令:ssh root@dataNode1,看到如下输出即表示设置成功

六、安装Hadoop(每台机器都要安装配置)
去apache官网下载Hadoop-2.6.5版本,上传到服务器目录下(我的目录:/app)。
使用命令解压接口:tar -zxvf hadoop-2.6.5.tar.gz
七、配置Hadoop
进入配置文件目录 cd hadoop-2.6.5/etc/hadoop,修改如下配置文件:
1、core-site.xm
hadoop.tmp.dir
/appdata/hadoop/tmp
Abase for other temporary directories.
fs.defaultFS
hdfs://namenode:9000
io.file.buffer.size
4096
2、hdfs-site.xml
dfs.nameservices
hadoop-cluster1
dfs.namenode.secondary.http-address
namenode:50090
dfs.namenode.name.dir
file:///appdata/hadoop/name
dfs.datanode.data.dir
file:///appdata/hadoop/data
dfs.replication
2
dfs.webhdfs.enabled
true
mapreduce.framework.name
yarn
mapreduce.jobtracker.http.address
namenode:50030
mapreduce.jobhistory.address
namenode:10020
mapreduce.jobhistory.webapp.address
namenode:19888
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.address
namenode:8032
yarn.resourcemanager.scheduler.address
namenode:8030
yarn.resourcemanager.resource-tracker.address
namenode:8031
yarn.resourcemanager.admin.address
namenode:8033
yarn.resourcemanager.webapp.address
namenode:8088
datanode1
6、修改hadoop-env.sh和yarn-env.sh两个文件
在这两个文件中设置JAVA_HOME
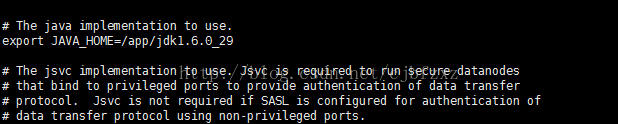
到此为止,配置文件修改完成。
小技巧:修改完一台机器的配置后,将相关配置文件直接拷贝到其他节点的机器上覆盖即可。
八、格式化文件系统
使用命令:bin/hdfs namenode -format
看到最后输出如下内容表示成功:
INFO namenode.NameNode: SHUTDOWN_MSG:
************************************************************
SHUTDOWN_MSG: Shutting down NameNode at nameNode/127.0.0.1
************************************************************/
(我只启动了nameNode,dataNode节点并不需要启动)
进入sbin目录下:
1、输入命令:./start-dfs.sh
2、输入命令:./start-yarn.sh
启动完成后使用jsp命令查看是否有进程,如下图:
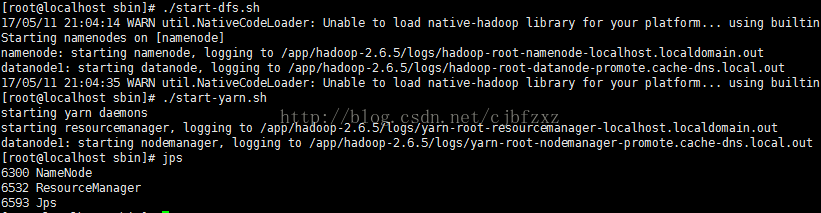
到其他节点服务器上执行jps命令,也可看到进程:

会发现进程名字不一样,第一个图是在nameNode上的进程,第二个是dataNode上的进程
十、通过浏览器访问
1、地址:http://192.168.205.156:50070/
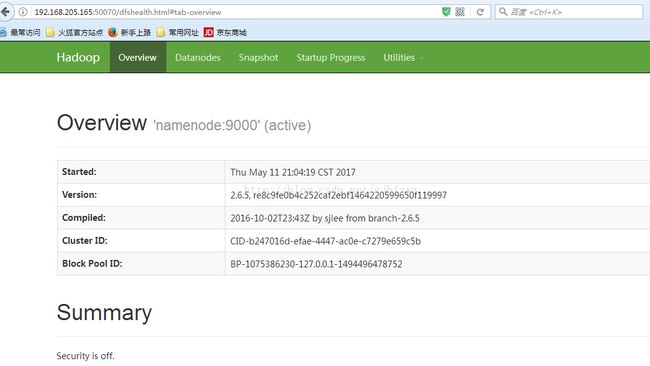
2、地址:http://192.168.205.156:8088/
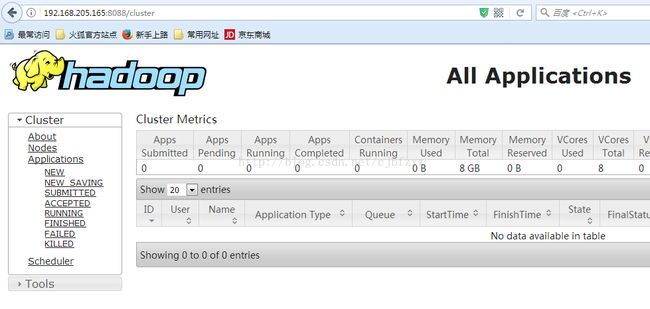
至此,整个配置全部完成。
由于目前的配置表面上看都是成功的,实际使用中还存在什么问题尚不得知,如有不妥的地方,希望各位指点交流。