华为CloudNative分布式数据库技术解析
【IT168 专稿】 本文根据Calvin Sun在2018年5月11日【第九届中国数据库技术大会】现场演讲内容整理而成。
讲师简介:Calvin Sun, 华为云数据库首席架构师。Calvin Sun于2017年10月加入华为加拿大多伦多研究所,目前担任Cloud BU云数据库首席架构师。Calvin有20多年的数据库内核开发经验,曾担任过Oracle云服务团队MySQL云服务高级顾问;是Twitter MySQL内核团队的负责人;也曾担任 Oracle InnoDB开发团队负责人,期间带领团队负责了InnoDB MySQL 5.5和5.6版本的开发。更早的时候,他还挡任MySQL存储引擎开发团队的负责人。Calvin曾在多个数据库会议上做过专题演讲。

摘要:
在云时代,企业IT业务走向跨地区、全球化部署,IT应用软件逐渐云化、分布式化,要求数据库也要基于云场景架构设计,具备跨地区分布式部署的能力。华为Cloud Native分布式数据库正是这样的一款新型数据库。在这次讲座中,将简要介绍其高可靠、高性能、易扩展等金融级的关键特性,并重点剖析其技术原理,最后还将深入揭开其背后的技术内幕。
分享大纲:
1、金融行业云技术发展现状;
2、云数据库发展历程;
3、高可用架构实践。
正文:
1、金融行业云技术发展现状
2018年中国信息通讯学院公布了一份统计数据。数据显示:大概41%的金融企业在用云计算,还有46%是计划使用。这对于云计算运营商来说,说明整个市场存在着很大的发展机会。
另外,从数据库应用情况看,主要是Oracle、DB2、MySQL和PostgreSQL。其中Oracle占比为62.61%,DB2占比为21.8%,MySQL占比为15.23%,PostgreSQL占6.76%,其他占比7.88%。由于金融行业对数据库要求比较高,所以Oracle是首选。但是现在来看,尤其随着云环境的成熟,AWS、阿里、华为等企业都基于MySQL在做云部署。在今后的几年内,MySQL大有靠前之势。
数据还显示,金融行业对于云计算有着特定的行业要求。大概67.81%的企业希望缩短应用部署时间;62.56%的企业希望节约成本;60.94%的企业希望在服务安全性上有保障。
上述这些数据,对于我们云服务商来说,有很大的参考作用。对于华为来说,这几年一直致力于云端。华为的策略是,提供云服务的“黑土地”,即提供基础设施服务。不同的应用服务提供商可以基于华为提供的底层技术平台来为用户提供服务。
2017年11月份,华为和招商银行共同成立了“分布式数据库联合创新实验室”。这将是华为云在金融行业的样板,双方将共同应对“Cloud First”的挑战。利用云、大数据、人工智能先进技术,借助领先的金融业务实践和优秀资源,以及在分布式数据库上积极探索,双方为客户提供普惠、个性化、智能化的金融服务。
2、云数据库发展历程
在传统数据库中,存储和计算都是一体模式,一主多辅的架构。如果一个主机宕掉,那么备机就会替代主机。这种架构在很多情况下还算实用,但是在金融这种强调高可靠性、数据量大的行业,传统数据库架构很难支撑。尤其,在主机和备机切换的时候,要花很长时间,还可能会造成数据丢失。
最近几年有几个大的趋势,特别是在云端。
第一,数据和存储的分离。Gartner有份数据,到2019年,90%以上的云数据库都会战略性地采取数据和存储的分离。如果你不这样做,就意味着被淘汰。这种说法可能存在着夸张的成份,但是这确实是不可忽略的趋势。
第二,硬件的进步。在CPU、存储、网络方面,都有大的改进,尤其在GPU、FPGA方面,进步明显。如何借助这些硬件的发展来提高云数据库的性能?这是我们在设计新的数据库时,必须要考量的因素。
第三,人工智能和机器算法的提高。AI和机器学习,也是云数据库开发重点要考虑的问题。
那么,最近几年,云数据库一些先驱都做了哪些事情呢?
1)、AWS Aurora
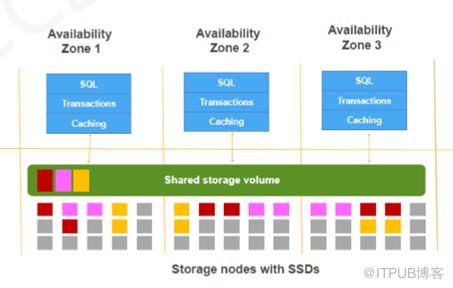
Aurora是Amazon为云计算而专门定制的一款关系型数据库,于2014年底发布,其目标主要是最小化网络IO,提升系统的可扩展性与可用性。Aurora的设计哲学是log is database,对数据的更改只写日志,也即write-once。Aurora系统设计人员认为传统的数据库不论如何扩展都在复制整个系统栈,在不同的层面做耦合;为了更好地适应云计算,他们认为应该将数据库系统这个“盒子”打开,把计算和存储分离,在不同的层面进行扩展。Aurora将恢复子系统委托给底层可靠的存储系统,依赖这个来保障系统服务层级(Service Level Agreement, SLA)。这种方式大大减少了网络流量的使用,后来很多企业都想模仿Aurora,做类似的架构。
2)、阿里的PolarDB

PoalrDB,最大的特点也是计算和存储的分离,但是和AWS的Aurora有些不同。页面依然是从计算节点写到存储节点,对于网络的要求相对较高。但是减少了很多用户状态和系统状态的切换,数据库做了很多IO优化。另外,主库通过RDMA将日志数据发送到存储节点的内存中,存储节点之间再通过RDMA互相复制,每个存储节点用SPDK将数据写入NVMe接口的存储介质里,整个过程CPU不用访问被同步的数据块(Payload),实现数据零拷贝。
3)华为Cloud Native
这种计算和存储分离的模式,华为也在做。在设计Cloud Native数据库的时候,就考虑到灵活性需求,包括主备的切换和节点的增加等,把更多操作下沉。华为Cloud Native在硬件方面有很强大的团队,和华为存储有深度合作,存储部门提供了专用平台,把数据库本身的操作下沉到存储节点。华为Cloud Native最大化地利用了ssd的属性,提升了数据库的性能。另外,还有多租户的考虑。利用新的网络技术,包括人工智能技术,帮助用户提升数据中心的吞吐量,提升网络应用的可伸缩性,并且能自动调优。
3、高可用架构实践

实际上,华为把数据库分成了三部分:SQL层、抽象层和存储层。从物理层面看,就两层,一个是SQL层,采取的是一主多备的模式;另外是存储层,可维护不同租户的数据库服务,包括构建页面、日志处理等相关功能。

针对SQL层,通过管理客户端连接,解析SQL请求,把计划、查询和管理事务隔离,采用的是一个RW和RO多个副本的形式。同时,华为还有个HWSQL,基于HWSQL在做很多性能增强,包括Query result cache、 Query plan cache以及Online DD等。
整个设计的独特之处是,通过多个节点的SQL复制,可减少频繁从存储器读取页面。当主服务器上发生更新时,read replicas数据库也会收到事务,提交更新列表。
另外还有一个存储抽象层(SAL)。SAL是一个逻辑层,可在存储单元里隔离SQL前端、事务和查询执行。在操作数据库页面时,SAL可支持访问同一页面的多个版本。基于spaceID、pageID,SAL可将所有数据分片,并且存储和内存资源也按照比例增长。
在性能方面,我们也充分利用了华为自身的一些特点,系统容器用的是华为自己的Hi1882高性能芯片。所以,在性能上要比一般容器要好。还有RDMA,通过这个应用大大减少了计算成本。而Co-Processor,则用尽量少的资源实现了数据处理,减少了SQL节点的工作负载。
来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/31545808/viewspace-2221073/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/31545808/viewspace-2221073/