k8s随着社区不断壮大国内使用率现在也是比较高的,常用的部署方式主要还是以二进制和kubeadm为主,当然1.13之前大部分人还是以二进制,但是随着版本更新kubeadm已经逐步适用于生成环境,由于kubeadm的简便部署相信以后使用率也会增加很多。今天主要是想总结一些常见的报错和解决方法思路希望能在日后大家使用过程中提供帮助,内容可能不会很完善,讲解不当之处望大家提宝贵意见多多指点,这篇文档主要以自身部署为主也会参考一些官网和其他博客汇总一部分,多说两句其实部署真心不是很难,主要还是要细心,很多时候碰到的错误后面解决时才发现原来是前面一些基础环境配置没有配好导致的。
1.问题描述:cordns一直重启logs报dial tcp 10.96.0.1:443: i/o timeout
(1)检查hosts,查看主机名和ip是否对应
(2)swap分区是否关闭(/etc/fstab注释swap行)
(3)检查防火墙和selinux是否关闭
(4)创建程序目录(这个是转载他人,实际并没有碰到过,如果碰到类似问题解决不了可以尝试)
mkdir -p /opt/kubernetes/{bin,cfg,ssl}
echo 'PATH=/opt/kubernetes/bin:$PATH' >>/etc/profile
source /etc/profile
2. init初始化不成功
这里简单说一下,因为这块碰到的问题比较杂
(1) 首先保证能科学**上网,如果无法科学**上网就要用国内的镜像,这里可以看日志具体情况具体解决,总结一点就是镜像原因导致的。
(2) 驱动类型,保证docker驱动与kube驱动一致
(3) vi /etc/sysctl.d/k8s-sysctl.conf
net.bridge.bridge-nf-call-iptables=1 net.bridge.bridge-nf-call-ip6tables=1 sysctl -p /etc/sysctl.d/k8s-sysctl.conf
3.使用kubeadm init 去初始化master node
注意你可能需要设置http代理,因为kubeadm init需要访问https://dl.k8s.io去获取package的信息;你可能还需要设置docker daemon的代理,因为kubeadm init要从http://k8s.gcr.io(这是google cloud的container registry)上pull一些image;你还需要设置no_proxy环境变量为master的IP。否则会报错:“Unable to update cni config: No networks found in /etc/cni/net.d。注意--pod-network-cidr=172.16.0.0/16这个参数,cidr的选取一定不要和你本地的网络有冲突。
4.kubeadm join一个新的worker node的时候报错:Unauthorized
这是因为你使用的token已经失效了,默认情况下,kubeadm init产生的token的有效期是24个小时;你肯定是在一天之后才kubeadm join的。你可以使用下面的命令来重新产生token:
kubeadm token create --print-join-command5.0/1 nodes are available: 1 node(s) had taints that the pod didn't tolerate.解决方法是安装flannel
有时候一个pod创建之后一直是pending,没有日志,也没有pull镜像,describe的时候发现里面有一句话: 1 node(s) had taints that the pod didn't tolerate.
直译意思是节点有了污点无法容忍,执行 kubectl get no -o yaml | grep taint -A 5 之后发现该节点是不可调度的。这是因为kubernetes出于安全考虑默认情况下无法在master节点上部署pod,于是用下面方法解决:
kubectl taint nodes --all node-role.kubernetes.io/master-6.机器非正常关机,kubernetes无法启动
![]()
发现产生的原因可能跟docker启动不起来有关

/var/lib/docker下的应该是container启动时跟-v参数mount的文件夹相关,也可能跟一个启动了的container所创建的文件系统有关。但是container被rm后理应被删除,删不掉就是出问题了,原因可能是mount的文件被其他container-B或XX-B链接或挂载,...-B非正常退出(或某行为)导致docker以为这个文件还被引用着。需要手动解决:stop docker后手动删除即可,删除的方法只能是umount再rm
7.在增加kubernetes节点时,ERROR CRI]报错
![]()
在增加kubernetes节点时,冒出这个错误。
configmaps "kubelet-config-1.11" is forbidden: cannot get configmaps in the namespace "kube-system" [ERROR CRI]: unable to check if the container runtime at "/var/run/dockershim.sock" is running: fork/exec /usr/bin/crictl -r /var/run/dockershim.sock info: no such file or directory
解决办法:
卸载cri-tools yum remove cri-tools
8.Error: Package: kubelet-1.10.0-0.x86_64
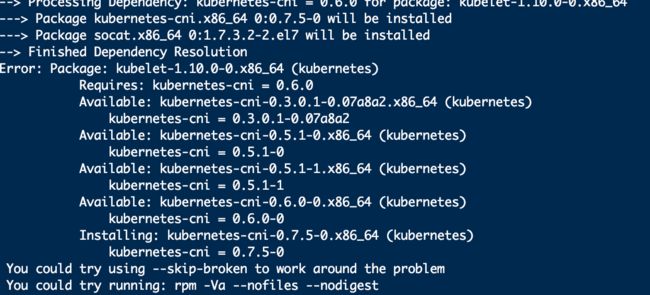
这个是缺少依赖包,报错部分也有提示Requires: kubernetes-cni = 0.6.0,
yum -y install kubernetes-cni = 0.6.0
大部分常见问题也就这么多,部署主要参考官网基础环境正常的情况下碰到问题的概率真的很低,还是细心为主了解原理解决问题也会方便很多,后面如果碰到新的问题会慢慢加进来,不足之处望指点