本篇博客将介绍Spark RDD的Map系算子的基本用法。
1、map
map将RDD的元素一个个传入call方法,经过call方法的计算之后,逐个返回,生成新的RDD,计算之后,记录数不会缩减。示例代码,将每个数字加10之后再打印出来, 代码如下
import java.util.Arrays;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.VoidFunction;
public class Map {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("spark map").setMaster("local[*]");
JavaSparkContext javaSparkContext = new JavaSparkContext(conf);
JavaRDD listRDD = javaSparkContext.parallelize(Arrays.asList(1, 2, 3, 4));
JavaRDD numRDD = listRDD.map(new Function() {
@Override
public Integer call(Integer num) throws Exception {
return num + 10;
}
});
numRDD.foreach(new VoidFunction() {
@Override
public void call(Integer num) throws Exception {
System.out.println(num);
}
});
}
}
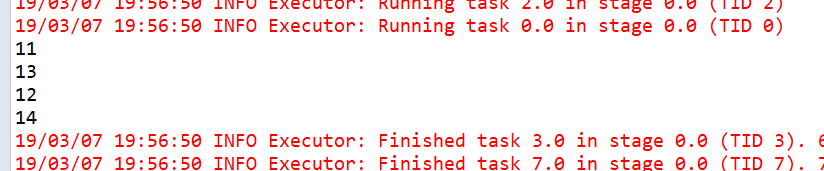
执行结果:
2、flatMap
flatMap和map的处理方式一样,都是把原RDD的元素逐个传入进行计算,但是与之不同的是,flatMap返回值是一个Iterator,也就是会一生多,超生
import java.util.Arrays;
import java.util.Iterator;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.VoidFunction;
public class FlatMap {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("spark map").setMaster("local[*]");
JavaSparkContext javaSparkContext = new JavaSparkContext(conf);
JavaRDD listRDD = javaSparkContext
.parallelize(Arrays.asList("hello wold", "hello java", "hello spark"));
JavaRDD rdd = listRDD.flatMap(new FlatMapFunction() {
private static final long serialVersionUID = 1L;
@Override
public Iterator call(String input) throws Exception {
return Arrays.asList(input.split(" ")).iterator();
}
});
rdd.foreach(new VoidFunction() {
private static final long serialVersionUID = 1L;
@Override
public void call(String num) throws Exception {
System.out.println(num);
}
});
}
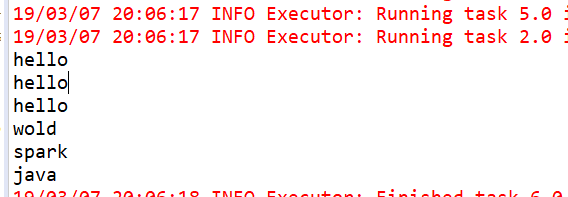
} 执行结果:
3、mapPartitions
mapPartitions一次性将整个分区的数据传入函数进行计算,适用于一次性聚会整个分区的场景
public class MapPartitions {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("spark map").setMaster("local[*]");
JavaSparkContext javaSparkContext = new JavaSparkContext(conf);
JavaRDD listRDD = javaSparkContext.parallelize(Arrays.asList("hello", "java", "wold", "spark"), 2);
/**
* mapPartitions回调的接口也是FlatMapFunction,FlatMapFunction的第一个泛型是Iterator表示传入的数据,
* 第二个泛型表示返回数据的类型
*
* mapPartitions传入FlatMapFunction接口处理的数据是一个分区的数据,所以,如果一个分区数据过大,会导致内存溢出
*
*/
JavaRDD javaRDD = listRDD.mapPartitions(new FlatMapFunction, String>() {
int i = 0;
@Override
public Iterator call(Iterator input) throws Exception {
List list = new ArrayList();
while (input.hasNext()) {
list.add(input.next() + i);
++i;
}
return list.iterator();
}
});
javaRDD.foreach(new VoidFunction() {
@Override
public void call(String t) throws Exception {
System.out.println(t);
}
});
}
} 运行结果:
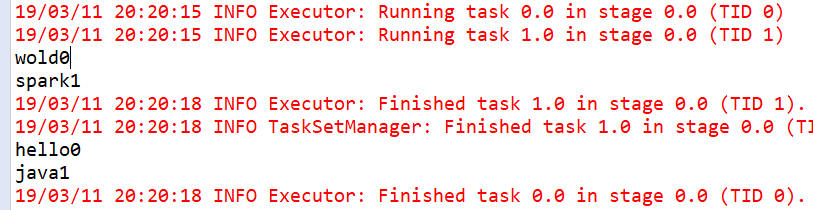
上面的运算结果,后面的尾标只有0和1,说明FlatMapFunction被调用了两次,与MapPartitions的功能吻合。
4、mapPartitionsWithIndex
mapPartitionsWithIndex和mapPartitions一样,一次性传入整个分区的数据进行处理,但是不同的是,这里会传入分区编号进来
public class mapPartitionsWithIndex {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("spark map").setMaster("local[*]");
JavaSparkContext javaSparkContext = new JavaSparkContext(conf);
JavaRDD listRDD = javaSparkContext.parallelize(Arrays.asList("hello", "java", "wold", "spark"), 2);
/**
*和mapPartitions一样,一次性传入整个分区的数据进行处理,但是不同的是,这里会传入分区编号进来
*
*/
JavaRDD javaRDD = listRDD.mapPartitionsWithIndex(new Function2, Iterator>() {
@Override
public Iterator call(Integer v1, Iterator v2) throws Exception {
List list = new ArrayList();
while (v2.hasNext()) {
list.add(v2.next() + "====分区编号:"+v1);
}
return list.iterator();
}
},true);
javaRDD.foreach(new VoidFunction() {
@Override
public void call(String t) throws Exception {
System.out.println(t);
}
});
}
} 执行结果:
