FusionCompute计算虚拟化
文章目录
- 计算虚拟化相关概念及技术
- 计算虚拟化概念
- 什么是虚拟化?
- 虚拟化的本质
- 计算虚拟化技术分类
- 根据虚拟化对象分类:
- 根据虚拟化过程分类:
- CPU虚拟化
- 首先我们要考虑,CPU虚拟化需要解决哪些问题?
- CPU与vCPU对应关系
- 内存虚拟化
- 内存虚拟化需要解决的问题?
- 影子页表
- EPT(扩展页表)
- 透明大页(THP)
- I/O虚拟化
- I/O虚拟化需要解决的问题
- 在QEMU/KVM中,客户机可以使用的设备大致可分为三类
- 模拟设备
- Virtio设备
- PCI设备直接分配
- FusionCompute计算虚拟化介绍
- 计算虚拟化功能特性
- 兼容行业特殊操作系统
- 灵活管理架构
- 支持GPU虚拟化、GPU直通
- 在线调整CPU和内存
- 主机内存超分配
- 内存复用包括:
- NUMA亲和性调度
- 虚拟机HA
- 虚拟机热迁移
- DRS动态资源调度
- DPM分布式电源管理
- IMC集群策略
- 规则组
计算虚拟化相关概念及技术
计算虚拟化概念
什么是虚拟化?
虚拟化可以看作是一个抽象层,它打破了原本物理硬件和操作系统之间紧耦合的关系。
虚拟化可以将资源抽象成共享资源池,实现对资源的动态调度和管理。
本质上,虚拟化就是由位于下层的软件模块,通过向上一层软件模块提供一个与它原先所期待的运行环境完全一致的接口的方法,抽象出一个虚拟的软件或硬件接口,使得上层软件可以直接运行在虚拟环境上。
虚拟化的本质

分区:虚拟化层为多个虚拟机划分所需的服务器资源,每个虚拟机可以同时运行一个单独的操作系统。
隔离:虚拟机之间相互隔离(可以进行资源控制、性能隔离)
封装:意味着整个虚拟机(硬件配置、BIOS 配置、内存状态、磁盘状态、CPU 状态)都存储在一个文件夹当中,只需要复制文件,就可以实现虚拟机的移动、复制。
相对于硬件独立 :由于虚拟机运行在虚拟化层上,使用虚拟的硬件,不用考虑物理服务器的情况。因此在任何x86服务器上都可以无需任何修改的运行虚拟机。
计算虚拟化技术分类
根据虚拟化对象分类:
CPU虚拟化—为了虚拟机上的指令可以被正常执行
内存虚拟化—做到虚拟机之间的内存空间相互隔离,使它们都认为自己拥有整个内存空间
I/O虚拟化—让虚拟机可以访问到所需的I/O资源
根据虚拟化过程分类:
全虚拟化—使用VMM实现CPU、内存、设备I/O的虚拟化。(兼容性好,但处理器会产生额外开销。)
半虚拟化—使用VMM实现CPU和内存虚拟化,I/O虚拟化交给GusetOS实现。(因此需要修改操作系统内核,使得它们可以协同工作。兼容性差,只有Suse、Ubuntu等少数Linux系统支持。但性能比全虚拟化好)
硬件辅助虚拟化—借助硬件(主要为处理器)的支持来实现高效的全虚拟化。
CPU虚拟化
首先我们要考虑,CPU虚拟化需要解决哪些问题?
- 如何模拟CPU指令(敏感指令)
敏感指令:可以读写系统关键资源的指令
系统关键资源:处理器呈现给软件的接口是指令集和寄存器。而 I/O 设备呈现给软件的接口是状态和控制寄存器。这些都是系统的资源,其中影响处理器和设备状态和行为的寄存器称为关键资源 。
特权指令:绝大多数的敏感指令都是特权指令,特权指令只在处理器的最高特权级执行。 - 如何让多个虚拟机共享CPU
类似于原生操作系统的定时器中断机制。(中断:在计算机执行程序期间,系统发生了需要紧急处理的事件,cpu会立刻停止当前操作,转而去处理相应的中断处理程序。处理完毕后,返回原本被中断的位置继续执行。)
在CPU虚拟化场景下,当中断触发时陷入VMM,从而根据调度机制进行资源的调度。
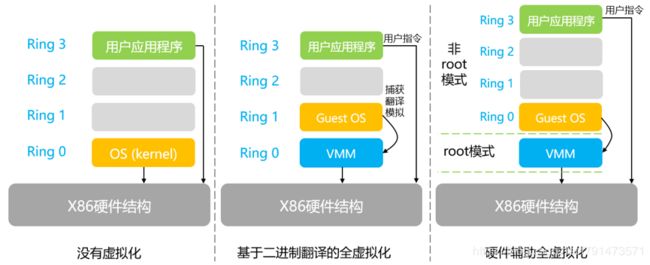
全虚拟化可以分为软件辅助虚拟化和硬件辅助虚拟化。
(参考博客:https://blog.csdn.net/jmilk/article/details/51824935)
软件辅助虚拟化能够成功的将所有在GuestOS中执行的系统内核特权指令进行捕获、翻译,使之成为只能对GuestOS生效的虚拟特权指令。(主要是由于CPU不能准确判断一个特权指令到底是GuestOS还是HostOS发出的,所以需要翻译。)
硬件辅助虚拟化主要使用了支持虚拟化功能的CPU进行支撑,CPU可以明确的分辨出来自GuestOS的特权指令,并针对GuestOS进行特权操作,而不会影响到HostOS。
半虚拟化:
需要对GuestOS的内核代码做一定的修改,才能够将GuestOS运行在半虚拟化的VMM中。其中修改的部分则是加入了hypercall(超级调用),例如:可将GuestOS
访问物理网卡做成系统调用,当GuestOS需要访问物理网卡时,就可明确告诉它可直接通过系统调用来访问物理网卡,这样可绕过宿主OS的参与直接完成访问,其效率更高。
FusionCompute计算虚拟化技术采用的是KVM技术。KVM的CPU虚拟化是基于CPU辅助的全虚拟化(硬件辅助虚拟化)。
x86 架构提供四个特权级别给操作系统和应用程序来访问硬件。 Ring 是指 CPU 的运行级别,Ring 0是最高级别。
Ioctl—专用于设备输入输出操作的系统调用。
CPU与vCPU对应关系

以RH2288H V3服务器使用2.6GHz主频CPU为例,单台服务器有2个物理CPU,每颗CPU有8核,又因为超线程技术可以提供每个物理内核两个处理线程,因此每颗CPU有16线程,总vCPU数量为282=32个vCPU。总资源为32*2.6GHz=83.2GHz。
虚拟机vCPU数量不能超过单台CNA节点可用vCPU数量。多个虚拟机间可以复用同一个物理CPU,因此单CNA节点上运行的虚拟机vCPU数量总和可以超过实际vCPU数量。
内存虚拟化
内存虚拟化需要解决的问题?
从物理地址0开始的:物理地址0只有一个,无法同时满足所有客户机从0开始的要求
地址连续:虽然可以分配连续的物理地址,但是内存使用效率不高,缺乏灵活性
通过内存虚拟化共享物理系统内存,动态分配给虚拟机。
影子页表
由于宿主机MMU不能直接装载客户机的页表来进行内存访问,所以当客户机访问宿主机物理内存时,需要经过多次地址转换。也即首先根据客户机页表把客户机虚拟地址 (GVA)转换成客户机物理地址 (GPA),然后再通过客户机物理地址 (GPA)到宿主机虚拟地址 (HVA)之间的映射转换成宿主机虚拟地址,最后再根据宿主机页表把宿主机虚拟地址 (HVA)转换成宿主机物理地址 (HPA)。而通过影子页表,则可以实现客户机虚拟地址到宿主机物理地址的直接转换

EPT(扩展页表)
CR3(控制寄存器3)将客户机程序所见的客户机虚拟地址(GVA)转化为客户机物理地址(GPA),然后在通过EPT将客户机物理地址(GPA)转化为宿主机物理地址(HPA)。这两次转换地址转换都是由CPU硬件来自动完成的,其转换效率非常高。
EPT只需要维护一张EPT页表,而不需要像“影子页表”那样为每个客户机进程的页表维护一张影子页表,从而也减少了内存的开销。

透明大页(THP)
增加了内存页面的大小,从而减少了页表的数量,所需要的地址转换也减少,TLB缓存失效次数也减少,提高了内存访问的性能。(另外,由于地址转换信息一般保存在CPU的缓存当中,大页的使用让地址转换减少,从而降低了CPU缓存的使用,提升了整体性能。)
I/O虚拟化
I/O虚拟化需要解决的问题
- 设备发现:
需要控制各虚拟机能够访问设备 - 访问截获:
通过I/O端口或者MMIO(内存映射I/O)对设备的访问
设备通过DMA(直接内存存取)与内存进行数据交换
在QEMU/KVM中,客户机可以使用的设备大致可分为三类
模拟设备
模拟I/O设备方式的优点是对硬件平台依赖性较低、可以方便模拟一些流行的和较老久的设备、不需要宿主机和客户机的额外支持,因此兼容性高;
而其缺点是I/O路径较长、VM-Exit次数很多,因此性能较差。一般适用于对I/O性能要求不高的场景。

Virtio设备
优点是实现了VIRTIO API,减少了VM-Exit次数,提高了客户机I/O执行效率,比普通模拟I/O的效率高很多;
而其缺点是需要客户机中与virtio相关驱动的支持 (较老的系统默认没有自带这些驱动,Windows系统中需要额外安装virtio驱动),因此兼容性较差。

PCI设备直接分配
设备直接分配让客户机完全占有PCI设备,这样在执行I/O操作时大量地减少甚至避免了VM-Exit陷入到Hypervisor中,极大地提高了I/O性能,可以达到几乎和Native系统中一样的性能。
存在问题:一台服务器主板上的空间有限,所以允许添加的PCI设备也有限。另外成本较高。

FusionCompute计算虚拟化介绍
虚拟机生命周期管理:创建、删除、开关机、克隆、快照、迁移等
虚拟资源管理:主机组、模板管理、数据中心/集群/主机/虚拟机分层管理等
虚拟资源配置管理:内存复用、虚拟机资源、CPU超分配、NUMA调度等
计算虚拟化功能特性
兼容行业特殊操作系统
(比较好理解不多谈了)
灵活管理架构
(比较好理解不多谈了)
支持GPU虚拟化、GPU直通
GPU虚拟化:类似于CPU虚拟化,提高GPU利用率,支持对vGPU资源管理和调度。
GPU直通:物理GPU在硬件支持虚拟机通过绑定GPU直接访问物理GPU的部分硬件资源。

在线调整CPU和内存
支持主流Linux系统虚拟机在线调整CPU和内存;支持主流Windows系统虚拟机在线调整内存,在线调整CPU后重启生效。
主机内存超分配
支持虚拟机总配置内存超过物理主机实际运行内存,通过虚拟机之间使用内存气泡、内存交换以及内存共享等技术实现物理内存超规格使用。
内存复用包括:
内存共享:多台虚拟机共享数据内容相同的内存页。
内存置换:将外部存储虚拟成内存给虚拟机使用,将虚拟机上暂时不用的数据存放到外部存储上。系统需要使用这些数据时,再与预留在内存上的数据进行交换。
内存气泡:系统主动回收虚拟机暂时不用的物理内存,分配给需要复用内存的虚拟机。内存的回收和分配均为系统动态执行,虚拟机上的应用无感知。整个物理服务器上的所有虚拟机使用的分配内存总量不能超过该服务器的物理内存总量。

NUMA亲和性调度
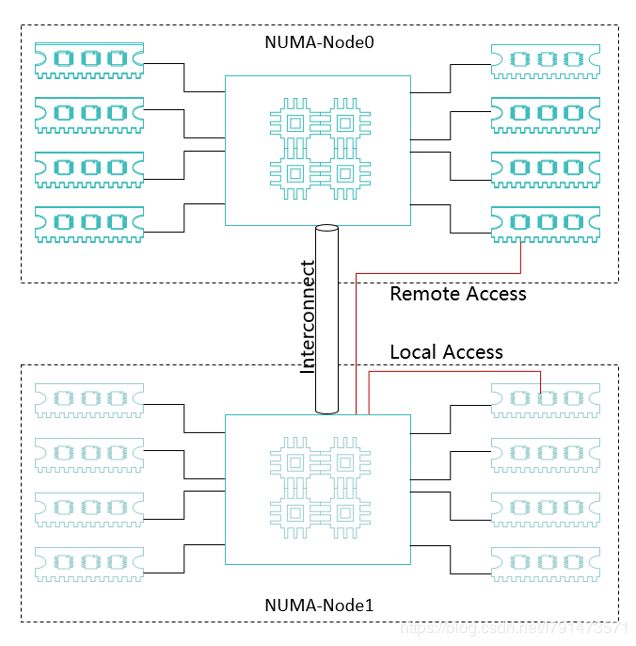
NUMA—非统一内存访问
NUMA把一台计算机分成多个节点(node),每个节点内部拥有多个CPU,节点内部使用共有的内存控制器,节点之间是通过互联模块进行连接和信息交互。
只有当CPU访问自身内存对应的物理地址时,才会有较短的响应时间(后称Local Access)。而如果需要访问其他节点的内存的数据时,就需要通过inter-connect通道访问,响应时间就相比之前变慢了(后称Remote Access)
所以在NUMA架构下,我们选择同一节点的CPU和内存,保证虚拟机的运行效率。
虚拟机HA
当虚拟机所处节点故障时,选择集群内可用节点重新启动该虚拟机,保障业务连续性,降低业务中断时间。
支持主机、虚拟平台、虚拟机内部多种故障场景的检测和虚拟机恢复
虚拟机热迁移
支持在不影响用户使用或中断服务的情况下在服务器之间实时迁移虚拟机,这样就不需要为了服务器维护而中断业务了。
DRS动态资源调度
统一集群内,均衡各节点资源使用并保障业务有充足资源可用。因此,DRS是实现自动负载均衡的基础。
DPM分布式电源管理
该功能会自动检测集群内服务器资源使用情况。当出现资源利用率不足时,将该主机上的虚拟机迁移到其他主机,并做下电操作。反之同理。
IMC集群策略
设置集群的IMC策略,使虚拟机可以在不同CPU类型的主机之间进行迁移。不会因为CPU类型不同而导致虚拟机迁移失败。因为集群内主机会向虚拟机提供相同的CPU功能集。
规则组
设定规则组可以控制虚拟机与虚拟机、虚拟机与主机之间的位置关系,以满足不同应用场景的需求
主要分为:聚集虚拟机、互斥虚拟机、虚拟机到主机
(这个比较好理解,在这里就不多谈了)