Python反爬虫的四种常见方式-JS逆向方法论
前言
文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: 王平
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
现在的网页代码搞得越来越复杂,除了使用vue等前端框架让开发变得容易外,主要就是为了防爬虫,所以写爬虫下的功夫就越来越多。攻和防在互相厮杀中结下孽缘却又相互提升着彼此。
本文就JS反爬虫的策略展开讨论,看看这中间都有着怎样的方法破解。
一 、JS写cookie
我们要写爬虫抓某个网页里面的数据,无非是打开网页,看看源代码,如果html里面有我们要的数据,那就简单了。用requests请求网址得到网页源代码然后解析提取。
等等!requests得到的网页是一对JS,跟浏览器打开看到的网页源码完全不一样!这种情况,往往是浏览器运行这段JS生成一个(或多个)cookie再带着这个cookie做二次请求。服务器那边收到这个cookie就认为你的访问是通过浏览器过来的合法访问。
其实,你在浏览器(chrome、Firefox都可以)里可以看到这一过程。首先把Chrome浏览器保存的该网站的cookie删除,按F12到Network窗口,把“preserve log”选中(Firefox是“Persist logs”),刷新网页,这样我们就可以看到历史的Network请求记录。比如下图:

第一次打开“index.html”页面时返回的是521, 内容是一段JS代码;第二次请求这个页面就得到了正常的HTML。查看两次请求的cookies,可以发现第二次请求时带上了一个cookie,而这个cookie并不是第一次请求时服务器发过来的。其实它就是JS生成的。
对策就是,研究那段JS,找到它生成cookie的算法,爬虫就可以解决这个问题。
二、JS加密ajax请求参数
写爬虫抓某个网页里面的数据,发现网页源代码里面没有我们要的数据,那就有点麻烦了。那些数据往往是ajax请求得到的。但是也不用怕,按F12打开Network窗口,刷新网页看看加载这个网页都下载了哪些URL,我们要的数据就在某个URL请求的结果里面。这类URL在Chrome的Network里面的类型大多是XHR。通过观察它们的“Response”就可以发现我们要的数据。
然而事情往往不是这么顺利,这个URL包含很多参数,某个参数是一串看上去无意义的字符串。这个字符串很可能是JS通过一个加密算法得到的,服务器也会通过同样的算法进行验证,验证通过了才认为你这是从浏览器来的请求。我们可以把这个URL拷贝到地址栏,把那个参数随便改个字母,访问一下看看是不是能得到正确的结果,由此来验证它是否是很重要的加密参数。
对于这样的加密参数,对策是通过debug JS来找到对应的JS加密算法。其中关键的是在Chrome里面设置“XHR/fetch Breakpoints”。

三、JS反调试(反debug)
前面我们都用到了Chrome 的F12去查看网页加载的过程,或者是调试JS的运行过程。这种方法用多了,网站就加了反调试的策略,只有我们打开F12,就会暂停在一个“debugger”代码行,无论怎样都跳不出去。它看起来像下面这样:

不管我们点击多少次继续运行,它一直在这个“debugger”这里,每次都会多出一个VMxx的标签,观察“Call Stack”发现它好像陷入了一个函数的递归调用。这个“debugger”让我们无法调试JS。但是关掉F12窗口,网页就正常加载了。
解决这种JS反调试的方法我们称之为“反-反调试”,其策略是:通过“Call Stack”找到把我们带入死循环的函数,重新定义它。
这样的函数几乎没有任何其它功能只是给我们设置的陷阱。我们可以把这个函数在“Console”里面重新定义,比如把它重新定义为空函数,这样再运行它时就什么都不做,也就不会把我们带人陷阱。在这个函数调用的地方打个“Breakpoint”。因为我们已经在陷阱里面了,所以要刷新页面,JS的运行应该停止在设置的断点处,此时该函数尚未运行,我们在Console里面重新定义它,继续运行就可以跳过该陷阱。
四、JS发送鼠标点击事件
还有些网站,它的反爬都不是上面的方式。你从浏览器可以打开正常的页面,而在requests里面却被要求输入验证码或重定向其它网页。起初你可能一头雾水,但不要怕,认真看看“Network”或许能发现些线索。比如下面这个Network流里面的信息:
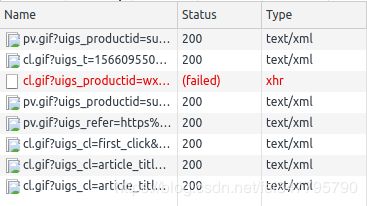
认真观察后发现,每点击页面的的链接,它都会做一个“cl.gif”的请求,它看上去是下载一个gif图片,然而并不是。它请求时发送的参数非常多,而且这些参数都是当前页面的信息。比如包含了被点击的链接等等。
我们先来梳理一下它的逻辑。JS会响应链接被点击的事件,在打开链接前,先访问cl.gif,把当前的信息发送给服务器,然后再打开被点击的链接。服务器收到被点击链接的请求,会看看之前是不是已经通过cl.gif把对应信息发过来,如果发过来了就认为是合法的浏览器访问,给出正常的网页内容。
因为requests没有鼠标事件响应就没有访问cl.gif的过程就直接访问链接,服务器就拒绝服务。
明白了这个过程,我们不难拿出对策,几乎不需要研究JS内容(JS也有可能对被点击链接进行修改哦)就可以绕过这个反爬策略,无非是在访问链接前先访问一下cl.gif即可。关键是要研究cl.gif后的参数,把这些参数都带上就万事大吉啦。
结尾
爬虫和网站是一对冤家,相克相生。爬虫知道了反爬策略就可以做成响应的反-反爬策略;网站知道了爬虫的反-反爬策略就可以做一个“反-反-反爬”策略……道高一尺魔高一丈,两者的斗争也不会结束。