图像识别:常用的attention代码
SEnet(Squeeze-and-Excitation Network)
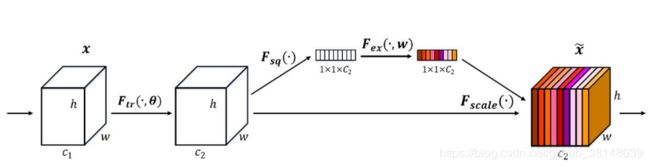
#https://github.com/Amanbhandula/AlphaPose/blob/master/train_sppe/src/models/layers/SE_module.py
class SELayer(nn.Module):
def __init__(self, channel, reduction=1):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc1 = nn.Sequential(
nn.Linear(channel, channel / reduction),
nn.ReLU(inplace=True),
nn.Linear(channel / reduction, channel),
nn.Sigmoid())
#加推荐使用1*1卷积
self.fc2 = nn.Sequential(
nn.Conv2d(channel , channel / reduction, 1, bias=False)
nn.ReLU(inplace=True),
nn.Conv2d(channel , channel / reduction, 1, bias=False)
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc1(y).view(b, c, 1, 1)
return x * y
CBAM(Convolutional Block Attention Module)

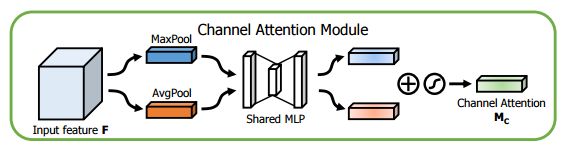

#https://github.com/luuuyi/CBAM.PyTorch/blob/master/model/resnet_cbam.py
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes / 16, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes / 16, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
#https://github.com/luuuyi/CBAM.PyTorch/blob/master/model/resnet_cbam.py
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
对于2017年中实现的MPNCOV
#一下代码来自:https://github.com/jiangtaoxie/fast-MPN-COV/blob/master/src/representation/MPNCOV.py
import torch
import torch.nn as nn
from torch.autograd import Function
class MPNCOV(nn.Module):
"""Matrix power normalized Covariance pooling (MPNCOV)
implementation of fast MPN-COV (i.e.,iSQRT-COV)
https://arxiv.org/abs/1712.01034
Args:
iterNum: #iteration of Newton-schulz method
is_sqrt: whether perform matrix square root or not
is_vec: whether the output is a vector or not
input_dim: the #channel of input feature
dimension_reduction: if None, it will not use 1x1 conv to
reduce the #channel of feature.
if 256 or others, the #channel of feature
will be reduced to 256 or others.
"""
def __init__(self, iterNum=3, is_sqrt=True, is_vec=True, input_dim=2048, dimension_reduction=None):
super(MPNCOV, self).__init__()
self.iterNum=iterNum
self.is_sqrt = is_sqrt
self.is_vec = is_vec
self.dr = dimension_reduction
if self.dr is not None:
self.conv_dr_block = nn.Sequential(
nn.Conv2d(input_dim, self.dr, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(self.dr),
nn.ReLU(inplace=True)
)
output_dim = self.dr if self.dr else input_dim
if self.is_vec:
self.output_dim = int(output_dim*(output_dim+1)/2)
else:
self.output_dim = int(output_dim*output_dim)
self._init_weight()
def _init_weight(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def _cov_pool(self, x):
return Covpool.apply(x)
def _sqrtm(self, x):
return Sqrtm.apply(x, self.iterNum)
def _triuvec(self, x):
return Triuvec.apply(x)
def forward(self, x):
if self.dr is not None:
x = self.conv_dr_block(x)
x = self._cov_pool(x)
if self.is_sqrt:
x = self._sqrtm(x)
if self.is_vec:
x = self._triuvec(x)
return x
class Covpool(Function):
@staticmethod
def forward(ctx, input):
x = input
batchSize = x.data.shape[0]
dim = x.data.shape[1]
h = x.data.shape[2]
w = x.data.shape[3]
M = h*w
x = x.reshape(batchSize,dim,M)
I_hat = (-1./M/M)*torch.ones(M,M,device = x.device) + (1./M)*torch.eye(M,M,device = x.device)
I_hat = I_hat.view(1,M,M).repeat(batchSize,1,1).type(x.dtype)
y = x.bmm(I_hat).bmm(x.transpose(1,2))
ctx.save_for_backward(input,I_hat)
return y
@staticmethod
def backward(ctx, grad_output):
input,I_hat = ctx.saved_tensors
x = input
batchSize = x.data.shape[0]
dim = x.data.shape[1]
h = x.data.shape[2]
w = x.data.shape[3]
M = h*w
x = x.reshape(batchSize,dim,M)
grad_input = grad_output + grad_output.transpose(1,2)
grad_input = grad_input.bmm(x).bmm(I_hat)
grad_input = grad_input.reshape(batchSize,dim,h,w)
return grad_input
class Sqrtm(Function):
@staticmethod
def forward(ctx, input, iterN):
x = input
batchSize = x.data.shape[0]
dim = x.data.shape[1]
dtype = x.dtype
I3 = 3.0*torch.eye(dim,dim,device = x.device).view(1, dim, dim).repeat(batchSize,1,1).type(dtype)
normA = (1.0/3.0)*x.mul(I3).sum(dim=1).sum(dim=1)
A = x.div(normA.view(batchSize,1,1).expand_as(x))
Y = torch.zeros(batchSize, iterN, dim, dim, requires_grad = False, device = x.device).type(dtype)
Z = torch.eye(dim,dim,device = x.device).view(1,dim,dim).repeat(batchSize,iterN,1,1).type(dtype)
if iterN < 2:
ZY = 0.5*(I3 - A)
YZY = A.bmm(ZY)
else:
ZY = 0.5*(I3 - A)
Y[:,0,:,:] = A.bmm(ZY)
Z[:,0,:,:] = ZY
for i in range(1, iterN-1):
ZY = 0.5*(I3 - Z[:,i-1,:,:].bmm(Y[:,i-1,:,:]))
Y[:,i,:,:] = Y[:,i-1,:,:].bmm(ZY)
Z[:,i,:,:] = ZY.bmm(Z[:,i-1,:,:])
YZY = 0.5*Y[:,iterN-2,:,:].bmm(I3 - Z[:,iterN-2,:,:].bmm(Y[:,iterN-2,:,:]))
y = YZY*torch.sqrt(normA).view(batchSize, 1, 1).expand_as(x)
ctx.save_for_backward(input, A, YZY, normA, Y, Z)
ctx.iterN = iterN
return y
@staticmethod
def backward(ctx, grad_output):
input, A, ZY, normA, Y, Z = ctx.saved_tensors
iterN = ctx.iterN
x = input
batchSize = x.data.shape[0]
dim = x.data.shape[1]
dtype = x.dtype
der_postCom = grad_output*torch.sqrt(normA).view(batchSize, 1, 1).expand_as(x)
der_postComAux = (grad_output*ZY).sum(dim=1).sum(dim=1).div(2*torch.sqrt(normA))
I3 = 3.0*torch.eye(dim,dim,device = x.device).view(1, dim, dim).repeat(batchSize,1,1).type(dtype)
if iterN < 2:
der_NSiter = 0.5*(der_postCom.bmm(I3 - A) - A.bmm(der_postCom))
else:
dldY = 0.5*(der_postCom.bmm(I3 - Y[:,iterN-2,:,:].bmm(Z[:,iterN-2,:,:])) -
Z[:,iterN-2,:,:].bmm(Y[:,iterN-2,:,:]).bmm(der_postCom))
dldZ = -0.5*Y[:,iterN-2,:,:].bmm(der_postCom).bmm(Y[:,iterN-2,:,:])
for i in range(iterN-3, -1, -1):
YZ = I3 - Y[:,i,:,:].bmm(Z[:,i,:,:])
ZY = Z[:,i,:,:].bmm(Y[:,i,:,:])
dldY_ = 0.5*(dldY.bmm(YZ) -
Z[:,i,:,:].bmm(dldZ).bmm(Z[:,i,:,:]) -
ZY.bmm(dldY))
dldZ_ = 0.5*(YZ.bmm(dldZ) -
Y[:,i,:,:].bmm(dldY).bmm(Y[:,i,:,:]) -
dldZ.bmm(ZY))
dldY = dldY_
dldZ = dldZ_
der_NSiter = 0.5*(dldY.bmm(I3 - A) - dldZ - A.bmm(dldY))
der_NSiter = der_NSiter.transpose(1, 2)
grad_input = der_NSiter.div(normA.view(batchSize,1,1).expand_as(x))
grad_aux = der_NSiter.mul(x).sum(dim=1).sum(dim=1)
for i in range(batchSize):
grad_input[i,:,:] += (der_postComAux[i] \
- grad_aux[i] / (normA[i] * normA[i])) \
*torch.ones(dim,device = x.device).diag().type(dtype)
return grad_input, None
class Triuvec(Function):
@staticmethod
def forward(ctx, input):
x = input
batchSize = x.data.shape[0]
dim = x.data.shape[1]
dtype = x.dtype
x = x.reshape(batchSize, dim*dim)
I = torch.ones(dim,dim).triu().reshape(dim*dim)
index = I.nonzero()
y = torch.zeros(batchSize,int(dim*(dim+1)/2),device = x.device).type(dtype)
y = x[:,index]
ctx.save_for_backward(input,index)
return y
@staticmethod
def backward(ctx, grad_output):
input,index = ctx.saved_tensors
x = input
batchSize = x.data.shape[0]
dim = x.data.shape[1]
dtype = x.dtype
grad_input = torch.zeros(batchSize,dim*dim,device = x.device,requires_grad=False).type(dtype)
grad_input[:,index] = grad_output
grad_input = grad_input.reshape(batchSize,dim,dim)
return grad_input
def CovpoolLayer(var):
return Covpool.apply(var)
def SqrtmLayer(var, iterN):
return Sqrtm.apply(var, iterN)
def TriuvecLayer(var):
return Triuvec.apply(var)
参考博客
CV领域的注意力机制综述
最后一届ImageNet冠军模型:SENet