Python实战---爬取B站视频弹幕和评论以及评论的评论
文章目录
- 使用requests库爬取B站视频弹幕和评论以及评论的评论
- 爬取目标
- 主要有四个获取数据的URL
- 1、爬取目标视频的URL
- 2、爬取目标视频弹幕的URL
- 3、爬取目标视频的评论URL
- 4、爬取目标视频评论的评论的URL
- 实现代码
- 运行结果
使用requests库爬取B站视频弹幕和评论以及评论的评论
爬取目标
明星大侦探巨想谈恋爱(上)、(下)和头号玩家Ⅱ(上)、(下)
urls = [
'https://www.bilibili.com/video/BV1St411S7GP', # 巨想谈恋爱
'https://www.bilibili.com/video/BV1Ut411i7dk',
'https://www.bilibili.com/video/BV14t411a7aN', # 头号玩家
'https://www.bilibili.com/video/BV1xt41187ti'
]
主要有四个获取数据的URL
1、爬取目标视频的URL
例如:https://www.bilibili.com/video/BV14t411a7aN
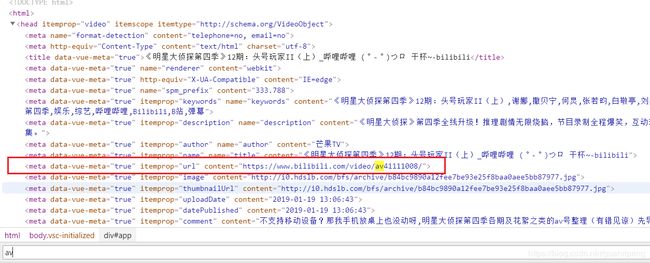
- 根据url获取BV号
- 从返回的请求页面中获取av号
- 根据BV号获取cid(cid是获取弹幕url中的参数)
URL为:https://api.bilibili.com/x/player/pagelist?bvid=BV14t411a7aN&jsonp=jsonp
返回结果如下:

2、爬取目标视频弹幕的URL
请求的URL:http://comment.bilibili.com/72211064.xml
返回结果如下:

可以看到是xml格式的数据,之后解析即可,具体解析代码:
response = requests.get(danmu_url, headers=headers)
if response.status_code == 200:
with open('bilibili.xml', 'wb') as fp:
fp.write(response.content)
html_comment = etree.parse('bilibili.xml', etree.HTMLParser())
ds = html_comment.xpath('//d')
danmu_list = []
for d in ds:
p = d.xpath('./@p')[0].split(',')
danmu_current_time = p[0] # 弹幕出现的时间
danmu_mode = p[1] # 弹幕模式:1..3 滚动弹幕 4底端弹幕 5顶端弹幕 6.逆向弹幕 7精准定位 8高级弹幕
danmu_font_size = p[2] # 弹幕字号
danmu_font_color = p[3] # 弹幕字体颜色
danmu_send_time = p[4] # 弹幕发送的时间
danmu_send_time = timestamp_datetime(int(danmu_send_time))
danmu_pool = p[5] # 弹幕池 0普通池 1字幕池 2特殊池 【目前特殊池为高级弹幕专用】
danmu_send_id = p[6] # 弹幕发送者id
danmu_id = p[7] # 弹幕在弹幕数据库中的id
text = d.xpath('./text()')[0]
comment = {
'danmu_current_time': danmu_current_time,
'danmu_send_time': danmu_send_time,
'danmu_send_id': danmu_send_id,
'text': text
}
danmu_list.append(comment)
3、爬取目标视频的评论URL
URL:https://api.bilibili.com/x/v2/reply?pn=1&type=1&oid=41111008&sort=1
其中oid就是之前获取到的av号
返回结果如下:

4、爬取目标视频评论的评论的URL
URL:https://api.bilibili.com/x/v2/reply/reply?&pn=1&type=1&oid=41111008&ps=10&root=1327071827
其返回结果如下:
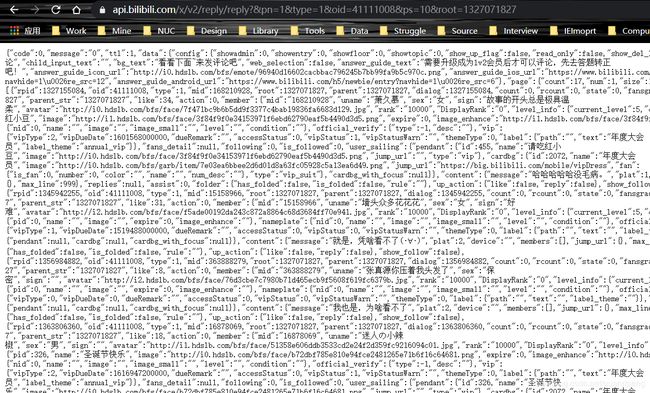
ps字段就是每页10条记录
root字段就是获取到评论的数据里面的rpid,如下图:

实现代码
'''
@Description: 爬取B站弹幕和评论
@Author: sikaozhifu
@Date: 2020-06-24 11:29:58
@LastEditTime: 2020-07-02 19:13:42
@LastEditors: Please set LastEditors
'''
import requests
from lxml import etree
import re
import time
import pymongo
import math
from pyecharts import options
from pyecharts.charts import Bar
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36'
}
'''
@description: 日期格式转换
@param : value
@return: dt
'''
def timestamp_datetime(value):
format = r'%Y-%m-%d %H:%M:%S'
# value为传入的值为时间戳(整形),如:1332888820
value = time.localtime(value)
# 经过localtime转换后变成
# time.struct_time(tm_year=2012, tm_mon=3, tm_mday=28, tm_hour=6, tm_min=53, tm_sec=40, tm_wday=2, tm_yday=88, tm_isdst=0)
# 最后再经过strftime函数转换为正常日期格式。
dt = time.strftime(format, value)
return dt
def parse_data(dbname):
com = dbname.comments
perfix = 'https:'
urls = [
'https://www.bilibili.com/video/BV1St411S7GP', # 巨想谈恋爱
'https://www.bilibili.com/video/BV1Ut411i7dk',
'https://www.bilibili.com/video/BV14t411a7aN', # 头号玩家
'https://www.bilibili.com/video/BV1xt41187ti'
]
ID = 0
for url in urls:
response = requests.get(url, headers=headers)
html = etree.HTML(response.text)
title = html.xpath('//h1[@class = "video-title"]/@title')[0] # video的标题
up_url = perfix + html.xpath('//div[@class = "name"]/a/@href')[0]
up_id = re.search(r'\d+', up_url).group(0) # up_id
up_name = html.xpath('//div[@class = "name"]/a/text()')[0] # up_name
av_id_url = html.xpath('//meta[@itemprop = "url"]/@content')[0]
av_id = re.search(r'\d+', av_id_url).group(0) # av_id
bvid = re.search(r'video/(.*)', url).group(1) # bv_id
bvid_url = 'https://api.bilibili.com/x/player/pagelist?bvid=%s&jsonp=jsonp' % bvid
response = requests.get(bvid_url, headers=headers)
cid = response.json()['data'][0]['cid']
danmu_url = 'http://comment.bilibili.com/%s.xml' % cid
time.sleep(1)
response = requests.get(danmu_url, headers=headers)
if response.status_code == 200:
with open('bilibili.xml', 'wb') as fp:
fp.write(response.content)
html_comment = etree.parse('bilibili.xml', etree.HTMLParser())
ds = html_comment.xpath('//d')
danmu_list = []
for d in ds:
p = d.xpath('./@p')[0].split(',')
danmu_current_time = p[0] # 弹幕出现的时间
danmu_mode = p[1] # 弹幕模式:1..3 滚动弹幕 4底端弹幕 5顶端弹幕 6.逆向弹幕 7精准定位 8高级弹幕
danmu_font_size = p[2] # 弹幕字号
danmu_font_color = p[3] # 弹幕字体颜色
danmu_send_time = p[4] # 弹幕发送的时间
danmu_send_time = timestamp_datetime(int(danmu_send_time))
danmu_pool = p[5] # 弹幕池 0普通池 1字幕池 2特殊池 【目前特殊池为高级弹幕专用】
danmu_send_id = p[6] # 弹幕发送者id
danmu_id = p[7] # 弹幕在弹幕数据库中的id
text = d.xpath('./text()')[0]
comment = {
'danmu_current_time': danmu_current_time,
'danmu_send_time': danmu_send_time,
'danmu_send_id': danmu_send_id,
'text': text
}
danmu_list.append(comment)
# print(danmu_send_time)
# print(text)
comment_url = 'https://api.bilibili.com/x/v2/reply?pn=1&type=1&oid=%s&sort=1' % av_id
response = requests.get(comment_url, headers=headers)
count = response.json()['data']['page']['count'] # 评论总数
page_count = math.ceil(int(count) / 20) # 评论总页数
comment_list = []
for pn in range(1, page_count + 1):
comment_url = 'https://api.bilibili.com/x/v2/reply?pn=%s&type=1&oid=%s&sort=1' % (pn, av_id)
response = requests.get(comment_url, headers=headers)
replies = response.json()['data']['replies']
for reply in replies:
reply_id = reply['member']['mid'] # 评论者id
reply_name = reply['member']['uname'] # 评论者昵称
reply_sex = reply['member']['sex'] # 评论者性别
reply_time = timestamp_datetime(int(reply['ctime'])) # 评论时间
reply_like = reply['like'] # 评论点赞数
reply_content = reply['content']['message'] # 评论内容
reply_info = {
'reply_id': reply_id,
'reply_name': reply_name,
'reply_sex': reply_sex,
'reply_time': reply_time,
'reply_like': reply_like,
'reply_content': reply_content
}
comment_list.append(reply_info)
rcount = reply['rcount'] # 表示回复的评论数
page_rcount = math.ceil(int(rcount) / 10) # 回复评论总页数
root = reply['rpid']
for reply_pn in range(1, page_rcount + 1):
reply_url = 'https://api.bilibili.com/x/v2/reply/reply?&pn=%s&type=1&oid=%s&ps=10&root=%s' % (reply_pn, av_id, root)
response = requests.get(reply_url, headers=headers)
rreplies = response.json()['data']['replies']
for reply in rreplies:
reply_id = reply['member']['mid'] # 评论者id
reply_name = reply['member']['uname'] # 评论者昵称
reply_sex = reply['member']['sex'] # 评论者性别
reply_time = timestamp_datetime(int(reply['ctime'])) # 评论时间
reply_like = reply['like'] # 评论点赞数
reply_content = reply['content']['message'] # 评论内容
reply_info = {
'reply_id': reply_id,
'reply_name': reply_name,
'reply_sex': reply_sex,
'reply_time': reply_time,
'reply_like': reply_like,
'reply_content': reply_content
}
comment_list.append(reply_info)
info = {
'ID': ID,
'video_title': title,
'up_id': up_id,
'up_name': up_name,
'danmu_list': danmu_list,
'comment_list': comment_list
}
print(info)
com.insert_one(info)
ID = ID + 1
time.sleep(1)
def show_web(show_data):
for data in show_data:
title = data[0]
danmu_month_count = data[1]
bar = Bar()
bar.add_xaxis(['1月', '2月', '3月', '4月', '5月', '6月', '7月', '8月', '9月', '10月', '11月', '12月'])
bar.add_yaxis('弹幕数量', danmu_month_count)
bar.set_global_opts(title_opts=options.TitleOpts(title=title))
bar.render('bar_danmu_count.html')
break
def get_show_data(dbname):
danmu_data = get_data(dbname)
show_data = []
for data in danmu_data:
title = data['video_title']
danmu_list = data['danmu_list']
danmu_month_count = []
for index, danmu in enumerate(danmu_list):
num = len(danmu)
danmu_month_count.append(num)
data = (title, danmu_month_count)
show_data.append(data)
return show_data
def sort_data_by_time(danmu_data):
danmu_data = sorted(danmu_data, key=lambda data_time: data_time['danmu_send_time'])
return danmu_data
def get_data(dbname):
com = dbname.comments
documents = com.find()
data_list = []
for document in documents:
danmu_data = []
video_title = document['video_title']
danmu_list = document['danmu_list']
# danmu_year_set = set()
danmu_month_set = set()
for danmu in danmu_list:
danmu_send_time = danmu['danmu_send_time']
year = danmu_send_time.split(' ')[0].split('-')[0]
month = danmu_send_time.split(' ')[0].split('-')[1]
day = danmu_send_time.split(' ')[0].split('-')[2]
# print('%s-%s-%s' % (year, month, day))
# danmu_year_set.add(int(year))
if year == '2019':
danmu_month_set.add(int(month))
data = {
'danmu_send_time': danmu['danmu_send_time'],
'month': int(month),
'day': int(day),
'text': danmu['text']
}
danmu_data.append(data)
# print(data)
danmu_data = sort_data_by_time(danmu_data)
data_group_by_month = []
for x in range(0, 12):
index = x + 1
data_month = []
for danmu in danmu_data:
if danmu['month'] == index:
data_month.append(danmu)
data_group_by_month.append(data_month)
# print(data_group_by_month)
data = {
'video_title': video_title,
'danmu_year': 2019,
# 'danmu_month': data_group_by_month,
'danmu_list': data_group_by_month
}
data_list.append(data)
return data_list
'''
@description: 根据日期获取星期
@param : 日期
@return: 0 - 6 表示周日到周六
'''
def get_week(date_time):
y = int(date_time.split(' ')[0].split('-')[0])
m = int(date_time.split(' ')[0].split('-')[1])
d = int(date_time.split(' ')[0].split('-')[2])
week = -1
if m == 1 or m == 2:
m += 12
y = y - 1
week = int((d + 2 * m + 3 * (m + 1) / 5 + y + y/4 - y/100 + y/400 + 1) % 7)
return week
'''
@description: 返回星期几的弹幕数量
@param : dbname
@return:
'''
def get_week_data(dbname):
com = dbname.comments
documents = com.find()
data_list = []
for document in documents:
video_title = document['video_title']
danmu_list = document['danmu_list']
danmu_data = sort_data_by_time(danmu_list)
data_group_by_week = []
for x in range(0, 7):
data_week = []
for danmu in danmu_data:
week = get_week(danmu['danmu_send_time'])
if week == x:
data_week.append(danmu)
data_group_by_week.append(data_week)
data = {
'video_title': video_title,
'danmu_list': data_group_by_week
}
data_list.append(data)
week_data = []
for data in data_list:
title = data['video_title']
danmu_list = data['danmu_list']
danmu_month_count = []
for index, danmu in enumerate(danmu_list):
num = len(danmu)
danmu_month_count.append(num)
data = (title, danmu_month_count)
week_data.append(data)
return week_data
def main():
client = pymongo.MongoClient(host='127.0.0.1', port=27017)
db = client.bilibili
parse_data(db)
# week_data = get_week_data(db)
# show_web(show_data)
# print(danmu_data)
# week = get_week('2020-7-5')
# print(week)
# print(week_data)
if __name__ == "__main__":
main()
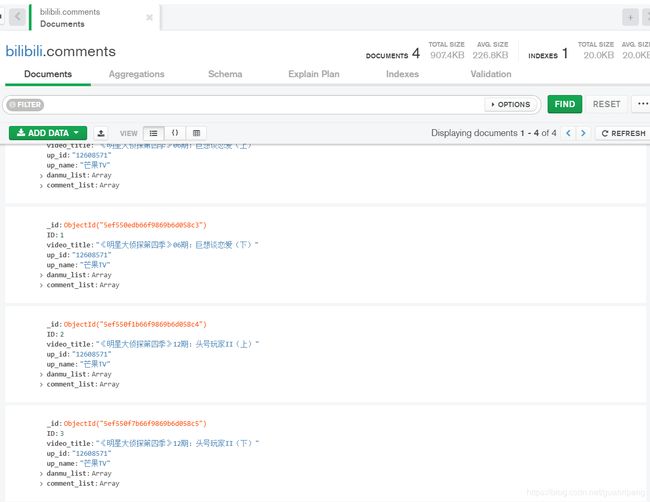
运行结果
存到Mongodb里面
在Mongodb compass里面展示如下: