Redis 基础简谈
本文主要从使用者的角度介绍 Redis 常见基础内容。内容选择偏向实用性。本文会从一些典型应用案例介绍Redis的数据类型和基础命令。然后介绍基础管理与维护的常见注意事项,以及典型集群模式。
1. Redis 简介
1.1 SQL vs NoSQL
此处 “SQL” 通常是指 Oracle、MySQL 等传统的 关系型数据库,“NoSQL” 则是指 MongoDB、Cassandra 等 “非关系型”数据库。
SQL 和 NoSQL 之间有什么区别呢?是SQL的数据结构化程度高?是NoSQL高性能和高可扩展性?是SQL事务的ACID四大特性?
不要相信炒作!每项新的技术应用出来时,都会有一帮“布道师”吹得天花乱坠,放大原有的事物缺陷,却对新事物的局限遮遮掩掩。还会有大量不明真相的小白跟风膜拜,一起宣扬“谁没跟上,谁就被淘汰”。投资人的钱袋子真是危险啊。
画外音:我没有将这些新事物称为“技术”,而是将它们称为“应用”。因为它们绝大多数不是技术创新,而是对已有技术的创新性应用。
传统关系型数据库功能强大,可以轻松应对绝大多数业务场景。为了应对那些特殊的业务场景,人们开发了各种不同的 “非关系型数据库” 来替代传统的关系型数据库。这些 “非关系型数据库” 就被人们称为 “NoSQL”。业务场景不同,需求侧重点也不同,催生出的 NoSQL 数据库之间也有非常大的差异。它们大致可分为:
- Key-Value数据库:非常适合缓存数据
- 文档型数据库:适用于数据结构灵活多变的场景
- 列式存储数据库:传统关系型数据库是把一行的数据一起存放,而它是把一列的数据一起存放。从这个角度来说,它是与传统关系型数据库最类似的。这类数据库非常适合数据分析的场景
- 图数据库:此“图”不是指“图片”,而是指“节点和节点间的关系组成的图”。这类数据库强调的是“关系”,非常适合社交网络、推荐系统相关业务
其实 SQL 和 NoSQL 关键区别还是在 “关系”上。所以当你考虑不用关系型数据库时,首先确定不同类型的数据之间不会产生“关系”。此外,“性能优先”也是选用 NoSQL 的主要考量点。当然,高性能不是白给的。高性能的代价往往是舍弃部分一致性校验或冗余校验等特性。这意味着你得承受更多数据不规整的风险。例如,MongoDB虽然支持跨文档事务,但为了更好的性能,官方不建议使用此特性。
图数据库虽然处理“关系”很强,但其它方面的能力没有传统关系型数据均衡。
通常,
SQL数据库适合稳定可预测的关系型数据,
NoSQL数据库适合临时性或动态性高的数据。
注意:NoSQL数据库之间差别还是很大的,不能一概而论。
1.2 Redis 的特性简介
Redis 就是我们前述的 Key-Value数据库的一种。
Redis 名称的由来。Redis名称的本意是“Remote Dictionary Server”。取其部分首字母组成 “Redis”。
Redis “事务”。Redis中的“事务”与传统关系型数据的“事务”有非常大的区别(可从此文后续章节的介绍中了解更多)。如果强行套用 ACID 四个特性,那么可认为 Redis的“事务”是:“非原子性”、“一致性”(使用watch命令)、“隔离性”(由单线程模式保证)、“持久性”(设置 appendfsync=always)。
Redis CAP。因为Redis集群的主从复制机制是异步模式的,所以不能保证一致性(Consistency)。Redis哨兵模式是一种高可用集群方案(Availability)。这种模式是具备分区容忍性的(Partition tolerance),但也可以设置为不容忍。Redis Cluster 一种数据分片的集群模式。为了让Redis Cluster具备高可用特性,就需要为每个分片部署一套哨兵集群。
Redis 适用场景。Redis适合 写操作很多,数据经常变动的场景。数据结构的契合度也是一个重要的考量点。比如某些分析类数据的结构与Redis非常契合,也可以考虑存放在Redis。
Redis 不适用场景。如果数据集非常大,但热数据占比很小,那么就不适合用Redis。当然,本身就不适合放在内存里的数据也不合适。(Redis的数据都放在内存)
2. 典型应用案例 与 Redis功能简介
2.1 用 Redis 实现任务队列

此案例主要应用 Redis 的 list 数据类型。
假设有一个 list,其对应的 Redis key 为 “queue-x”。那么相关队列操作可使用以下 Redis 命令:
- 入队:LPUSH queue-x T5
- 出队:RPOP queue-x
- 清空队列:DEL queue-x
- 查看队列长度:LLEN queue-x
- 移除成员:LREM queue-x 0 T5
2.2 执行“出队”的时机
客户端轮询当然是一种方法。但是轮询频率非常高,而队列中有元素的时间占比很小,那么大量的出队操作是在浪费资源。
Redis 提供 BRPOP 命令。它是 RPOP 的阻塞版本。执行 BRPOP 时,如果队列当前没有元素,则连接会阻塞,直到有元素入队或超时才会返回。然后客户端可以再次发起 BRPOP。
命令示例:BRPOP queue-x 30
我们也可以利用 Redis 的 Pub/Sub 机制来触发“出队”操作。

这种方式也需要有阻塞 Redis 连接(监听线程)。而且监听线程必须在任务入队前开启监听。
我们结合这些方式来实现出队策略:
- 以客户端轮询为主。
- 为了避免队列长时间无元素,浪费过多轮询,可以将轮询周期设置得稍微长一点。
- 为了避免有轮询周期过长导致元素被延迟处理过久,可以利用 Pub/Sub 通知机制。一旦监听到新任务,就立即发起一轮出队操作。注意此处是指“一轮”,不是“单次”。因为任务可能是批量入队的。
- 任务可能在某个时间段频繁出现。为了提高单次轮询请求的有效性,可以用 BRPOP 代替 RPOP,并设置一个合适的超时时间。
当然,鉴于 Redis 无法保证数据一致性的特点,某些业务场景可能基于Kafka等其它基础架构实现队列,或者将Redis队列作为方案的一部分。
2.3 利用 Pipeline 提升性能
如果是临时队列,要让它能自动过期,则可以在元素入队操作时将设置对应 Redis key 的过期时间。命令示例:
- RPUSH tmp-queue-x "item-1"
- EXPIRE tmp-queue-x 86400
每次执行元素入队时都需要执行上述两个命令。为了提高效率,可以利用 Redis Pipeline 特性。


Redis请求的处理大致可分为4个阶段:
- 客户端发出请求到Redis
- 请求进入Redis的待处理队列
- 请求出队,并被处理
- Redis返回执行结果至客户端
这4个阶段中,“发出请求”和“返回结果”是最耗时的。其中网络往返的耗时占比非常高。客户端和Redis读写数据时需进行内核态与用户态的转换,这也是比较耗时的。利用 Pipeline 就是要一次发出多个命令,减少网络往返和 Socket I/O 次数,从而提高整体效率。以前述 RPUSH 和 EXPIRE 操作为例:
分两次独立的请求,其流程如下:

利用 Pipeline 合并请求,其流程如下:

- 此处省略了请求的出入队过程
- Redis收到 expire 请求可能晚于 rpush 的执行。expire 肯定是在 rpush 之后被执行。
2.4 Redis Script
Redis 的 Script 特性也允许一次提交多个命令。它允许向Redis提交一段Lua脚本,并让Redis执行这段脚本。
命令示例:EVAL "return redis.call('set', KEYS[1], 'bar')" 1 foo
《分布式锁之误“解锁”》中就有一段典型的Lua脚本:
if ARGV[1] == redis.call('GET', KEYS[1])
then
return redis.call('DEL', KEYS[1])
else
return 0
end
Script vs Pipeline
Script 和 Pipeline 我该选哪个呢?
通常而言,优先使用 Script。Script 的性能更好。因为 Script 本质上是单次请求。而 Pipeline 本质上多次请求合在一起发送,多个响应合在一起返回。此外 Script 支持更复杂的服务端计算。这是Lua脚本所提供的能力。当然,如果Script太复杂,其指定的操作太耗时,性能也不好,而且会阻塞其它客户端请求。因为Redis是单线程执行请求内容的。
2.5 Redis 事务
Redis 的“事务”也支持一次提交多个命令。而且具有隔离性的特点。
对于单个命令而言,因为Redis是单线程执行请求内容的,所以单个命令肯定具备隔离性。
对于Script而言,虽然它可以包含多个命令,但它本质上还是单个请求,所以它的整个脚本具备隔离性。Redis在执行这段脚本时不会穿插执行其它请求内容。
但如果是 Pipeline 合并提交多个请求,那么这批请求的内容在Redis被执行的时候,中间可能会穿插其它客户端提交的请求。也就是说这批请求不具备隔离性。
而 Redis 的“事务”底层是基于 Pipeline 特性实现的,那它是如果做到隔离性的呢?Redis “事务”是以特殊的命令 Multi/Exec 来圈定范围的。当 Redis 发现这对关键字时,会将其范围内的命令一起逐个执行,期间不会执行其它请求内容。
典型命令示例:
MULTI
RPUSH tmp-queue-x "item-1"
EXPIRE tmp-queue-x 86400
EXEC
Redis 提供了5个事务相关命令:multi、exec、discard、watch、unwatch。其中watch和unwatch是用于实现类似 check-and-set 效果。详见官方文档。
注:Redis 的事务与传统关系型数据库的事务差异非常大。Redis 事务不支持回滚就是其中的一个显著差异。
2.6 Redis Key 的过期机制
Redis key 有两种过期方式。一种是“被动过期”。即,当客户端访问已过期的key时,Redis会立即将该key删除。另一种是“主动过期”。即,Redis会定期主动删除已过期的key。默认每秒执行10次主动过期操作。但它并不是每次都遍历所有key,而是基于概率的算法。它会随机选择设置了过期时间的20个key,并删除其中已过期的key;如果此次操作中已过期key的个数超过1/4(5个),那么它会再次随机选择20个key重复该操作。
“主动过期”是不可预测的。有些已过期的key可能永远不会被删除。当然,我们可以使用 scan 命令来遍历key,从触发“被动过期”操作。
2.7 Redis 数据类型
Redis 最常用的数据结构有:String, List, Hash, Set, SortedSet。它也支持地理位置数据类型(Geo)等多种其它类型。其中 HyperLogLog 就是在统计场景中常用的类型。它被用于统计不同元素的个数。如果不同元素的数量非常大,那么用Set统计时,内存消耗非常高,而且有显著的性能下降。如果无需保存元素内容,那么 HyperLogLog 就非常适合。HyperLogLog 的内存消耗很小,性能高。它可以用固定数量的内存(12KB)计算最多 2^64 个不同元素的基数。当然,这也不是凭空获得的优势。它的统计结果可能不准确(标志差小于1%)。这有点“有损压缩”的意味。
3. 基础管理与维护
3.1 Key的管理
Redis 通常是用于高速缓存,追求高性能。但是它的部分命令可能会耗时较长,而Redis又是单线程执行命令。这就很可能导致单个比较耗时的客户端请求,阻塞了其它客户端请求。此处列举几个典型的命令。
高风险命令 keys
此命令的功能是查询符合给定模式的 key。当 key 非常多时 Redis 会被长时间阻塞。我们可以用 scan 命令来代替。keys 的使用模式是一次性获取所有符合条件的key,而scan则是增量式的迭代获取。所以scan有个明显的缺陷:在增量式查询过程中,key 可能被修改,导致结果不准确。类似的命令还有 sscan、hscan、zscan。它们分别对应 Set、Hash、SortedSet 这几种数据类型。

中风险命令 del
此命令的功能是删除指定的 key。当对应的 value 数据量很大时,内存回收操作会阻塞较长时间。我们可以用 unlink 命令来替代。unlink 只是移除 key,value 内存则由另一个后台线程来回收。

中风险命令 rename
此命令的功能是重名名指定的 key。如果 新key 已经存在,那么 Redis 会先执行 del 删除 新key。所以类似前述操作,我们可以先对 新key执行 unlink。

画外音:其实在 Redis 中存储数据量过大的 value 并不是特别适合。正常情况下我们也不会这么干。这也可能是 Redis 直接在 del 操作中回收 value 内存的原因之一。
3.2 禁用高风险命令
为了避免误用高风险命令,我们可以屏蔽它们。原理类似 Linux 的 alias。就是将目标命令“重定向”为空字符串。我们可以在 Redis 的配置文件 redis.conf 中设置。
配置文件路径示例:/opt/redis/redis.conf

这样,客户端提交相应命令时,Redis就会告诉它无法识别命令。

3.3 Redis 数据持久化
我们通常是将 Redis 作为缓存使用。即使 Redis 数据被清空,业务的正确性不会受到根本性的破坏,只是会性能差一些。但是很多时候我们还是选择恢复 Redis 数据,或将 Redis 服务迁移到其它服务器,从而加快缓存的重建,减少业务损失。这种情况下,我们就需要事先将 Redis 数据持久化。Redis 数据持久化方式主要有两种:快照、AOF
3.3.1 快照
快照,顾名思义就是将全量数据备份到磁盘中。
快照文件路径示例:/opt/redis/dump.rdb
Redis 的 快照文件内容以魔法字符串“REDIS”开头。前面部分是 Redis 版本号等一些元信息。
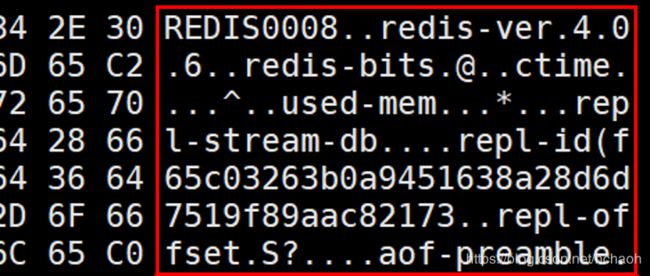
那么什么时候执行快照操作呢?
我们可以设置成周期性执行,或数据变更次数达到某个阈值时自动触发。
"900 1" 表示在 900 秒内至少有1次数据变更就触发一次快照。类似的,“300 10”表示“300内至少有10次数据变更”,“60 10000”表示“60秒内至少有10000次数据变更”。

我们也可以使用命令 save 或 bgsave 手动触发。这两个命令的区别是 bgsave 完全由后台进程执行,不会阻塞当前线程。所以 save 也是一个高风险命令。当 Redis 数据量较大时,save 的阻塞效果非常显著。


3.3.2 AOF
AOF 是 Redis 的另一种持久化方式。它的原理类似 ZooKeeper 的事务日志。MySQL 的 binlog 也是类似的套路。就是将 Redis 的写操作记录到一个文件中。Redis 是以“追加”的方式写这个文件。这种写入方式下,即使写文件操作被意外中断,也可以舍弃文件末尾被破坏的部分数据,来“修复”文件,使得之前的内容仍然可用。“AOF”这个名词的含义也就是“append-only file”。
画外音:我很不喜欢这种命名方式。它是以文件的使用方式来命名,而不是文件真实的业务作用来命名。大家不要学它。ZooKeeper 的事务文件名“log”也不是个好名字,它容易被误认为是 ZooKeeper 的程序运行时日志。
AOF 文件路径示例:/opt/redis/appendonly.aof

一个绕不开的问题:什么时候将 AOF 内容落盘?
Redis 会调用操作系统的 fsync() 命令,将 AOF 内容强制刷新到磁盘中。这种事情,肯定是刷新频率越高,服务崩溃时,丢失数据的可能性越小。但是过高的刷新频率势必降低 Redis 的性能。Redis 提供了3种刷新操作系统缓存的策略:
- always:对每个写命令都调用 fsync()。服务崩溃时只丢一个命令。
- everysec:每秒调用一次 fsync()。这样最多之丢一秒钟内的数据。这是 Redis 的默认策略。
- no:不调用 fsync(),而是让操作系统自行决定刷新频率。Linux 中通常是每30秒刷新一次。
- Linux 相关设置项示例:vm.dirty_expire_centisecs = 3000
3.3.3 快照 vs AOF
那么我们该选哪一种持久化方式呢?
通常有以下 4个 方面需要考虑:
- 意外停机时的数据丢失数量
- 保存数据时的性能开销
- 持久化文件的大小
- 数据恢复的速度
快照的优点是 占用磁盘少、数据恢复速度快。但是当写入流量和数据量较大时,系统调用 fork() 延迟较高,内存开销也比较高。
AOF 的优点是 数据一致性较高。(每次写操作都记录下来,而且落盘频率通常比快照高得多,丢失数据的量当然会小一些)。但是写操作频繁时,AOF文件会非常大。(每个key的最后一次数据变更才会真正被使用,前面那些变更记录都没用。)
当然,Redis也支持重写AOF。其原理就是只记录最新的value,清除那些已过期的信息。我们可以通过 bgrewriteaof 命令来手动触发重写操作(在后台执行);也可以设置AOF文件的最大值,让Redis自动触发重写。


3.3.4 快照 + AOF
Redis 也支持 快照 与 AOF 结合使用,得到一个表现较为均衡的持久化方案。即,将 AOF 文件内容起始部分设置为快照数据。


3.4 内存配置
3.4.1 操作系统配置
- vm.overcommit_memory=1
- 即,允许Redis分配所有物理内存,不管当前是否有足够的内存
- vm.swappiness=0
- 即,禁用虚拟内存,避免 Redis 被磁盘I/O阻塞
- 也就是说,我们宁愿 Redis 因为内存不足被 kill,也不愿它因为交换分区被阻塞。Redis 被 kill 的情况,就由高可用方案来处理。
- 禁用 Linux 的 透明大页 功能(Transparent Huge Pages)
- 计算机将内存分为N个“页”管理,并创建一个表来保存 虚拟地址 和 这些内存页(物理地址) 之间的映射关系。CPU必须将虚拟地址转换为物理地址,才能访问目标内存。在“页”大小确定的情况下,总物理内存越大,“页”数就越多,需要与其映射的虚拟地址也越多。即,需要在映射表中增加更多条目。但这势必降低检索效率。所以我们就增大“页”的大小,来减少映射条目。也就是使用“大页”。比如,原来每页是 4KB,我们可以将其扩大为 2MB、4MB 等。但是“大页”的使用比较繁琐,甚至需要更改程序代码才能发挥其作用。所以“透明大页”技术就登场了。
- 透明大页是一种类似“代理”的效果。“透明”就是它可以实现对传统“大内存页”的自动管理(大多数情况下),大大简化了上层代码的编写。但是某些情况下也会遇到性能问题,或导致程序异常。
- Oracle 数据库也有类似的问题。其官方也是建议禁用“透明大页”。
![]()
3.4.2 Redis key 淘汰策略
为了防止内容消耗过多导致整个 Redis 不可用,Redis 支持淘汰部分 key。我们可以设置 maxmemory-policy 来指定一种淘汰策略。Redis 共支持 8 种策略:volatile-lru、allkeys-lru、volatile-lfu、allkeys-lfu、volatile-random、allkeys-random、volatile-ttl、noeviction。默认策略是 noeviction,即不淘汰任何key。volatile-lru 是一个常用的策略,即只讨论那些已设置了过期时间的key,且先讨论最近最少被使用的key(LRU,Least-Recently-Used)
3.5 “慢”操作诊断
3.5.1 定义“慢”
首先我们需要确定慢到什么程度才算是慢。比如,我们通过设置,规定 Redis 执行一个命令超过 10毫秒 就属于慢。Redis 会将这些慢操作记录下来,供后续分析。
![]()
注意,这耗时只衡量 Redis 服务端线程被阻塞且不能响应其它请求的时间。它不包括磁盘 I/O 和网络传输时间。所以客户端感受到“慢”,不一定会被 Redis 认为慢,也就没有对于的慢日志。
3.5.2 获取“慢”日志

3.5.3 基准延迟测试
为了分析慢的原因,我们需要对某些延迟进行基准测试。
首先是服务器系统固有延迟。Redis 自带的客户端提供了相关测试工具。其原理就是执行一些非常简单的计算,而且这些计算不会被编译器优化。

这个自带工具也提供了测试网络延迟的能力。其原理就是 ping。
![]()
3.5.4 延迟问题的常见分析对象
通常,我们可以从以下信息中分析慢的原因:
- 运行缓慢时的应用日志
- Redis 延迟指标日志、ping探测时间、网络状态(可以用dstat工具)
- 可以将这些日志记录到 ElasticSearch 中供后续分析
- Redis 命令处理的统计信息(通过命令 info commandstats 获取。见下图示例)
- Redis “慢”日志(slowlog get)
- Redis CPU 使用率
- 客户端连接数通常是 CPU 使用率过高的排查点。连接数过大会导致 CPU 使用率较高。
- 如果客户端连接数频繁地短时间内急剧增加,那么很可能是客户端没有正确管理连接导致(可能是没有用连接池)
- Redis 持久化开销
- 磁盘 I/O 和 fork() 耗时是衡量持久化开销的主要方面
- 其它 Redis 自带检测工具,如 Watchdog 和 latency-monitor,也可以为我们提供一些线索

4. 典型集群模式
Redis 有两种典型的集群模式:哨兵模式 和 Redis Cluster。哨兵模式主要用于实现高可用。Redis Cluster 模式则用于解决单机内存不足的问题,也就是对数据进行分片。
4.1 哨兵模式
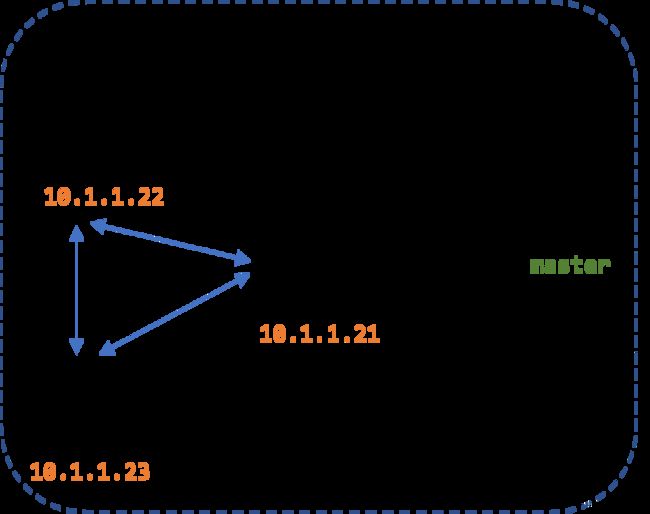

客户端配置三个哨兵的地址,从哨兵处获得当前 master 实例的地址,再与 master 通信。
哨兵的职责:
- 监视 master 和 slave 的运行状态
- 通知 Redis 实例异常
- 自动处理 故障转移(即,选择新的 master)
- 提供服务 配置信息
- 向客户端提供 master 地址
- 当发生故障转移时,通知客户端连接新的 master
注意:master 和 slave 之间的数据同步是异步模式的。所以已提交的改动在未同步到 slave 前,如果 master 崩溃并丢失数据,那么这些更改将丢失。即,Redis 的主从架构不保证已提交操作的持久性。
哨兵模式——关键配置
master - slave 的关系可通过 Redis 的 slaveof 命令配置,也可以在配置文件 redis.conf 中配置。此节主要将哨兵配置文件中的最关键配置。
哨兵配置文件路径示例:/opt/redis/sentinel.conf
哨兵配置文件可以包含很多内容。其中最关键的是 master 实例信息。示例:
sentinel monitor mymaster 10.1.1.21 6379 2“mymaster”是这组主从集群的名称。“10.1.1.21”是 master 的IP地址。“6379”是 master 对客户端提供服务的端口号。“2”是值“法定人数(quorum)”。此“法定人数”与 ZooKeeper 的“法定人数”有较大不同。ZooKeeper 的“法定人数”对于保证集群数据一致性有非常强的约束(用多数原则防止“脑裂”)。而 Redis 的“法定人数”仅用于判定 master 是否可用。
例如,总共有5个 sentinel,quorum被设置2。那么当同时有2个sentinel判定master不可达时,其中一个就会尝试启动故障转移。此时如果多数sentinel(此处至少3个)批准,那么会真正执行故障转移。
另,sentinel能自动发现其它sentinel和副本实例,所以无需在配置文件中指定。
哨兵模式——网络分区
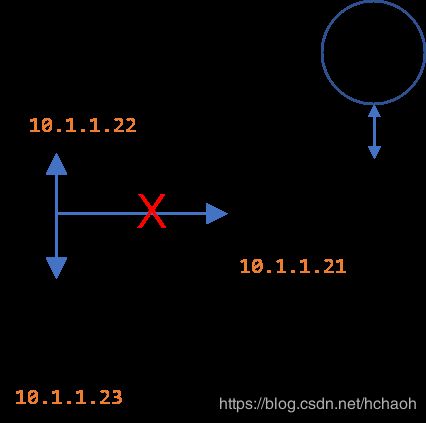

上图中,Redis 服务端是三个实例组成的哨兵模式集群。
初始时,M1 是 master。客户端 C1 先向 M1 提交了数据 data1。但是在 data1 同步到其它副本之前,发生了网络分区。两个副本 R2 和 R3 处于一片可以互通的网络内,M1 和 C1 处于另一片可以互通的网络内,但这两片网络无法互通。这就导致 S2 和 S3 这两个哨兵认定 M1 出现故障,于是选举 R2 成为新的 master M2。而在这个网络分区事件期间,客户端 C1 可以继续向 M1 提交数据(data2)。当网络恢复后,因为 M2 的数据版本(epoch)更高,所以 M1 会转变为 slave 角色,并同步 M2 的数据。这就导致 data1 和 data 2 都丢失。
怎么解决这个问题呢?Redis 提供了一种改善方法。可以通过配置采用更严格的副本策略:
min-replicas-to-write = 1
min-replicas-max-lag = 10上述配置的字面意思就是,master执行写操作的时候必须至少完成一个副本实例的同步,且副本响应时间不能超过10秒。若满足不了这个要求,master 将拒绝客户端继续提交写操作。这样就可以降低数据丢失的量。前文我们讲过,master 和 slave 之间的数据同步是异步模式的。所以该配置的实际意思是,若所有从实例都不可达,或超过10秒未收到确认消息,则拒绝客户端继续提交写操作。
当然,这种方式也是有代价的。如果从实例都不可达,那么整个集群将无法处理写操作。
(Redis 的这个副本策略设计思想与 MongoDB 的 “Write Concern” 非常类似。ZooKeeper 则是通过 zab 协议,用两阶段提交和多数原则的模式来保证一致性。)
Redis分布式锁的数据一致性
既然讲到了 Redis 集群无法保证数据一致性的问题,我们就讲讲应用很广的 Redis分布式锁。因为Redis的高性能,很多软件系统都基于它来实现分布式锁。对于“锁”,我们通常都会对它的实现提出很高的可靠性要求。而因为 Redis集群的数据一致性问题,基于 Redis的分布式锁 风险就值得说道说道。

上图中,Redis 服务端是由三个实例组成的哨兵模式集群。
客户端 C1 先向 master M1 提交了 setnx 命令,获得了独占式的“锁”。但是在“锁”的数据同步到其它副本之前,发生了网络分区。R2、R3 和 客户端 C2 同处一片可互通的网络内,M1 处于另一片网络,且这两片网络无法互通。然后就发生了我们熟悉的一幕,R2 被选举为新的 master M2。之后,客户端 C2 向新的 master M2 提交了 setnx 命令,尝试获得 C1 已拥有的独占式锁,并且 M2 告诉它成功了。这就导致在同一时刻有两个实例(C1和C2)拥有了同一个独占式锁,破坏了业务规则。
4.2 Redis Cluster

此图中 Redis 服务端结合了 Redis Cluster 模式 和 哨兵模式。A、B、C 三个 Redis 实例组成 Redis Cluster 集群。A1、B1、C1 等多个 Redis 实例分别是它们的副本。如,A、A1、A2 组成了一个哨兵模式的集群。这样既能实现数据分片的效果,又满足高可用需求。
注意:因为副本数据同步还是之前哨兵模式提到过的异步模式,所以这类集群也不能保证已提交操作的持久性。
在 Redis Cluster 模式中,我们可以按照 key 分出多个数据分片。每个分片称为一个 slot。Redis 支持最多 16384 个 slot。每个 Redis 节点负责部分 slot。比如上图中,A负责索引为 0 到 5500 的 slot,B负责索引为 5501 到 11000 的 slot,C负责索引为 11001 到 16383 的 slot。而且这些实例(A、B、C)都知道其它实例负责的是哪些 slot。
对于一个给定 key,应将其分配到哪个 slot 呢?slot计算公式如下:
slot = CRC16(key) mod 16384
如果客户端提交的key不属于接收请求的Redis实例,会怎样?Redis将返回一个特定的错误(MOVED),并告诉客户端对应服务实例的 IP 和 端口号。这样客户端就可以向新的 IP 和 端口号 再次提交请求。这就是个“重定向”模式,与 HTTP 的重定向设计思想类似。
GET x
-MOVED 3999 127.0.0.1:6381如果一个请求中包含对多个 key 的操作如何解决呢?这些key可能由不同的 Redis 实例负责。这种情况下就需要用到 “hash tag” 特性。即,Redis Cluster 只针对 key 字符串中,“{}”内的内容进行hash,计算slot。如,"this{foo}key" 和 "another{foo}key" 只有 "foo" 会被用于计算 slot,所以它们会位于同一个 slot 内。
Redis Cluster 的应用并不常见。因为数据量达到不得不分片的情况其实不多。而且现在微服务架构盛行,单个微服务直接访问的缓存数据量通常不大。而且很多软件运维组织都倾向于为每个微服务单独部署一套 Redis 服务(哨兵模式),缓解了多个微服务共享同一 Redis 服务实例导致内存不足的问题。
4.3 Codis
很多软件组织都有自己的 Redis 衍生产品,包括客户端实现、服务端集群解决方案等。在众多 Redis 集群架构解决方案中,Codis 算是一个比较典型的案例。

Codis 通过 codis-proxy 对客户端提供服务。codis-proxy 实现了 Redis 协议。可以用 Codis 自己的客户端 jodis-client,也可以其它普通客户端访问。其中一个较大的区别是,jodis-client 会通过 ZooKeeper 监控可用的 codis-proxy。因为 codis-proxy 会将自己注册到 ZooKeeper 中。这是一个典型的服务注册-发现机制。与 Dubbo 有些类似。codis-proxy 背后是 N 个 codis-group,用于实现数据分片。每个 codis-group 包含多个 codis-server,它们组成一个哨兵模式的集群。codis-server 是一个定制版的 Redis。codis-dashboard 则是用于管理这整个集群的运维中心,codis-fe 是其前端。这整个集群的元信息会被存放在 Storage。
5. 结束
虽然新技术应用层出不穷,但是这些应用背后绝大部分技术原理都是经过长时间考验的“老”技术。只有了解这些“老”技术,才能更好地了解“新”应用的优势与局限。比如,ZooKeeper、Redis、MongoDB、MySQL 等应用的数据持久化与恢复方案有非常大的相通性。它们的设计者对数据提交和持久化等各种细节有不同的侧重点,所以底层使用了不同的实现逻辑,最终呈现的特性差异就非常大。本质上并不是谁的技术更强,而是它们为了适应不同的业务场景,作出了不同的决定,走了不同的岔路。
作为这些应用的使用者,就要基于具体业务,选择合适的方案。不要相信炒作!
技术架构就得深入一线编码,解决实际落地问题!