自动化运维之后,你还在人工巡检吗?
自动化运维监控工具诞生
初期阶段IT基础设施通常处在小规模状态。几台至几十台机器的规模,足以满足业务需求。很多公司都不一定配有专门的运维人员或者部门,业务开发人员完成自己业务工作的同时,也一并完成所负责管理相关业务的设备。随着云时代到来了,IT基础设施迅速发展成几百上千服务器。更多的业务系统上线,业务人员也无暇再顾及运维工作。此时,运维人员开始专业化,独立成部门。各类孤岛式的运维管理工具上线,提升运维效率。
可是在各类运维工具上线之后,大家发现运维人员仍然时常要充当“救火队员”,收警告、修机器,哪里宕机去哪里。虽然有了运维管理工具自动化收集监控数据之后,但还是有很多问题,让底层物理资源运维工作无法实现完全自动化。
逃不开的人工巡检
目前,多数客户所选择的运维监控方式都是在操作系统上安装Agent访问设备驱动,读取硬件状态数据。所有监控状态的数据抓取都受限于驱动程序。而驱动程序的编写人员所关注的重点在于设备的正常运行,而不在于设备的状态监控。因此,通过驱动程序所抓取的硬件状态参数始终有限。这也就能解释,为什么很多客户在上线了运维监控软件之后,还是需要人工巡检。我们来看几个大家经常遇到的问题:
事例1:某客户数据库系统上线,3块900G 硬盘做raid5。当出现一块坏盘之后,监控软件看不到有坏盘,因为系统还在正常运行。人工巡检之后,发现设备上有硬盘告警灯。监控软件下又无法查看到系统是JBOD还是做了raid。巡检中,数据库服务器出现硬盘告警,监控软件在这种时候却帮不上忙。如果不是人工巡检,甚至可能都没有发现这个严重告警。
事例2:某客户的核心业务服务器配置双电源,却在一次电源故障中出现了服务器掉电问题。严重事故之后,追查责任,才发现原来双电源中的备用电源一直处于离线状态。系统下的agent无法监控到冗余电源离线,因为一直有一个电源在线,供电没有出现任何问题,因而没有告警信息出现。最终客户发现,监控系统上线了,还是得巡检。
事例3:某客户想要扩容旧系统上内存容量,监控软件显示内存容量为256G。还有多少内存槽位呢?机器上是16G*16,还是32G*8呢?监控软件获取不到!很崩溃,只能去机房拆机器验内存T_T
……
日常工作量大,加班是常态。还要经常面临设备问题而带来了业务中断风险。监控系统上线了,一切都没有开始好转。
带外解带内之困,远离人工巡检
从专业的角度来看,网络管理可分为带外管理(out-of-band)和带内管理(in-band)两种管理模式。上述在系统下,也就是客户的生产环境下抓取数据,通过生产网络读取监控数据属于带内管理。这种管理方式,最大的问题就在于当系统出现故障时,机器就无法管理。而且如上所述,获取的监控数据有限。而几乎所有的it设备厂商都为客户提供带外管理口,也就是与生产系统相隔离的管理口。管理口下,设备厂商本身就提供了详细的硬件参数。这些硬件参数直接来自于服务器上百多个sensor,直接从硬件层面获取的状态参数。数据更为细节、全面和直观。
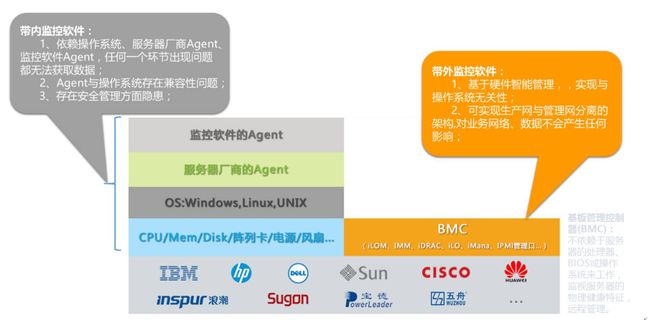
带外监控通过sensor监视服务器状态,就像在设备上安装了上百个摄像头一样,时刻巡视设备运行状态。冗余电源离线、机器上任一条内存容量、内存频率、内存槽位信息、HBA卡槽位信息等等,这些带内软件无法捕捉的信息,都可以通过带外监控获取。这就等同于人工巡视,拆机验选件。并且,轮训所有机器的时间周期要远远大于人工巡视的时间周期。带外监控的轮训周期可以达到秒级,而人工巡检的工作量大,以日为周期已经是相当大的巡检密度了。通过带内监控来弥补带外监控的部分空缺,可以极大的提升运维效率,真正意义上实现无需人工巡检。
扬带外之长,建数据中心操作系统
带外管理最大的好处就在于与生产系统相隔离,直接实现与机器对话。这样效率更高,同时可以有效减少对生产系统的影响。现在的数据中心,通常对所有设备都已经建立了比较完善的带外管理网络。这一日益完善的架构,不仅仅可以用来做带外管理,还可以利用其优势构建一个完整的底层DCOS(Data Center Operating System)。扬带外之长,实施建造一套完整的底层运维架构。
什么是DCOS?
DCOS是为数据中心所有设备全生命周期服务的一套管理平台。简单的说,是为数据中心的设备进行全生命周期的管理,从采购到安装使用,再到维修、报废的整个过程服务。
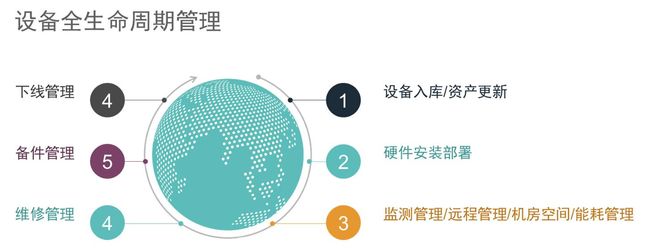
通过DCOS的全生命周期自动化平台管理,实现部署、监控、分析、管理全自动,数据中心的无人值守。尽可能的保证服务过程的标准化,减少其中的人为管理。
我们梳理一下DCOS需要完成哪些部分的自动化运维工作。

1. 部署
当设备进入数据中心,首先通过DCOS进行业务流程审批,包含上架申请等过程。然后,DCOS对资产进行自动化的验收,主要检验配置是否符合规范,对各个选件(CPU/内存/硬盘等)做自动化的压力测试。可以实现选件级别的资产验证,所有信息都为自动更新采集。如内存信息,可以自动收集所有内存的插槽信息、容量、频率等。
设备验收可以实现选件级设备验收:如内存,可以验收内存总容量,同时可以验证型号、容量和数量信息。当设备通过验收之后,可以通过带外网络自动化发现设备,可以自动化获取设备上带有的资产信息,并将设备自动化列入资产管理。
然后从模板库当中,选择对应的自动化安装模板进行全自动化的安装,包括自动化的阵列卡配置、OS配置,配置标准化的基础设施给上层资源运维使用。
完成整个过程后,在设备状态列表中将设备状态更新为已上线的可用状态。
整个过程只有上架申请和模板库选择模板操作需要人为干预,其它过程均为标准化的自动化流程,可以大大提高部署效率,并减少人为操作带来的上线质量不合格问题。
2. 监控/分析
监控分析是DCOS最核心的功能。为了更好的与上层资源运维做隔离,DCOS采用带外管理的方式尽量与上层业务做隔离。这种方式,可以在设备无论上层系统是否正常运行的情况下,都可以对设备进行监控分析。且带外的管理方式,可以保障带外的管理工作可以不影响正常的业务运行效率,同时也在一定程度上保证了业务数据的安全性。
DCOS主要可以从资源、机房、业务、设备等多种不同的视图监控数据中心的各种资源。不同视图下,可以随时查看设备的健康状态、性能状态,可以用列表以及多种图标形式更加自动化的直观展现。对于设备异常状态可以实现多途径的告警,包括邮件、短信、微信等形式。DCOS实行多级告警制度,根据告警的严重性分成不同等级。对于部分严重警告,可以设置告警升级规则,将告警自动化上报高层,实现问题的自动化升级。为了避免出现单一故障(如交换机故障)导致的与交换机连接的服务器同时报警所产生的告警风暴,DCOS可以实现对告警进行自动化的收敛,减少批量告警所带来的不必要的恐慌。通过这种方式,实现百分之百的硬件状态查看。
DCOS提供所有服务器远程虚拟KVM功能,不占用系统资源和网络资源、不需要安装代理程序(Agent)。同时,可以节省大量购买物理KVM费用等设备的采购费用。
DCOS通过带外方式自动化获取各个设备的主要性能参数,以图形化界面展示,或者生成报表,实现设备资产的大数据化,帮助分析设备资产资源利用率,更加合理利用、扩充的配备设备资产。
通过DCOS的监控、分析功能,可以有效的替代对于小型机、X86服务器、存储设备、备份带库、光纤交换机等设备的人工机房巡检。这种方式大大节省了人工巡检所需的人力,也提高了巡检的效率。整个监控、分析都有DCOS后台自动化执行,只需要人为干预去处理部分设备故障。调查显示,多数运维事故都是因为人为误操作而导致。相信大家还记得前不久发生的Gitlab运维人员误删库,导致Gitlab网站丢失了6小时数据。因此人为干预操作的减少,可以避免更多的运维事故。
3. 管理
管理部分包括对于数据中心资产(服务器、存储、网络、UPS、精密空调等)的资产信息进行管理,其中包含对设备位置的追踪。以及设备维保情况、工作状态等实时状态的自动化更新提醒。帮助形成it资产的全局化统一视图。
除了自动化生成设备数据列表,还能通过过滤信息,自动化灵活生成资产报表。同时,可以根据数据中心设备之间的互联状态,生成设备的逻辑视图,以及数据中心机架的位置视图。除了资产管理之外,还需要进行知识库管理,形成运维人员之间,以及运维人员和维保商/厂商之间更快的自动化沟通渠道,让维保商可以更快的将设备固件更新等信息自动化推送给用户,减少原有的繁琐沟通渠道。
DCOS的知识库也可以帮助运维人员之间实现一个长期的技术知识累计,可以实现技术文档的快速自动化检索,让平台不仅仅是一个自动化的管理平台,还是一个很好的技术积累平台。
部署、监控分析和管理三大自动化功能板块看似互相独立,实际上实现了数据的互联互通,为彼此的业务提供数据支撑,形成统一的自动化管理视图。
未来:“简生态”运维系统
数据中心运维包含很多的内容,从底层往上,包含物理资源、虚拟资源、系统、应用、业务的运维。复杂度往上逐层递增。而重要性却是以底层运维为基础。

众所周知,运维部门的多数的运维工作80%集中在底层物理资源、系统资源运维。这正符合二八定律,我们在花80%的时间做20%的工作内容。如果是这样,我们需要将运维工作做剥离。将这20%的工作从整个运维体系剥离开来,通过带外网络架构来进行统一管理,建立一个底层运维的“简生态”。用更直观、更标准化的视图来简化这一部分的管理,提升基础工作的管理效率,实实在在的提升日常运维管理工作的质量。这就好像物理设备是水杯,而设备上承载的万千业务是水杯里的可乐或者柠檬茶,无论水杯里装的是什么,带外管理的任务只负责保障水杯的完整,不会有水杯里的内容流失。最最重要的任务,用最简化的方式来保驾护航,反而能赢得最佳的效果。
未来的理想是通过带外来弥补带内设备管理的空缺,真正意义上实现最佳的物理设备管理,24小时不间断保障物理设备的正常运行。可以点击鼠标,就能完成成千上万服务器的运营管理,让生活不再是眼前的苟且,还有诗和远方。