12-何为分,何为合-Mapper&Reducer介绍
Mapper&Reducer介绍
1 Mapper&Reducer概述
MapReduce是Hadoop进行数据处理的核心组件。Hadoop MapReduce是一个软件框架,通过它我们可以非常轻松的写出应用程序来处理存储在Hadoop分布式文件系统中的各种结构化和非结构化的数据。MapReduce工作分成两个阶段:Map阶段和Reduce阶段。每个阶段都以键值对作为输入和输出。
Mapper是Hadoop数据处理的第一个阶段,它处理每一条来自RecordReader的输入记录并生成键值对形式的中间结果。Hadoop Mapper在本地磁盘存储中间输出。

Reducer接收Mapper的输出(中间键值对),并逐一处理,最后生成输出。Reducer的输出是最终输出,将存储到HDFS中。通常,在Hadoop Reducer中,我们完成聚合或者分类求和计算。
我们本节将介绍什么是MapReduce Mapper,它是如何生成键值对的,什么是InputSplit和RecordReader,以及mapper是怎样工作的。我们还将讨论Hadoop MapReduce运行任何程序时Mapper的数量,以及这个Mapper数量是如何计算出来的。
同时,我们还会介绍什么是Reducer,Reducer又分为哪些阶段,有何不同,Hadoop reducer类的功能。我们还将讨论在Hadoop中需要多少reducer以及如何改变这个reducer数量。

2 Hadoop Mapper
Hadoop Mapper任务处理每个输入记录并且生成一个新的
MapReduce框架为每个InputSplit(输入分片,由作业的InputFormat生成)生成一个map任务。
Mapper仅理解数据的
下面我们讨论Hadoop键值对是如何生成的。
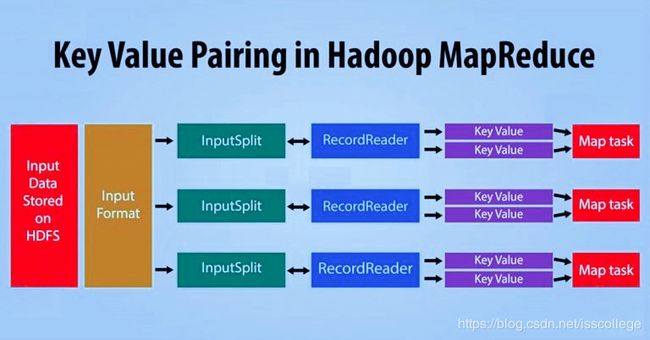
- InputSplit:它是数据的逻辑表示。在MapReduce程序中,它是每个map任务的工作单元。
- RecordReader:它和InputSplit交互,将数据转换成适合Mapper读取的键值对。默认使用TextInputFormat将数据转换成键值对。
2.1 Hadoop Mapper是如何工作的
下面让我们来看看Hadoop中mapper的处理过程。InputSplit为Hadoop mapper将数据块的物理表示转换成逻辑表示。要读取100MB的文件,需要两个InputSlit。每个数据块建立一个InputSplit,每个InputSplit将建立一个RecordReader和一个Mapper。
InputSplit也不总是取决于数据块的数量,我们也可以为特定的文件指定分片数,在作业执行时,可以设置mapred.max.split.size属性。
RecordReader复制读取数据,并将数据转换成键值对,直到文件结束。RecordReader会为文件中的每一行指定一个字节偏移量(唯一编号),然后这个键值对会发送给mapper。mapper程序的输出被称作中间数据(reduce所理解的键值对)。
2.2 Hadoop中有多少map任务
对于Hadoop MapReduce程序来说到底需要多少mapper?根据给定的数据,我们是如何计算这个mapper数量的?
输入文件数据块的总数控制着程序中map的数量。对于map来说,并行处理的map数大约是每个节点10-100个,当然,对于cpu占用少的map任务可以达到300个。由于任务的设置也需要花费一些时间,因此,map执行时间最少在1分钟以上。
比如,我们数据块大小为128MB,我们要处理10TB的输入数据,那么我们需要82000个map。因此输入数据决定了map数。
map数=总数据大小/输入分片大小
比如,如果数据大小时1TB,而输入分片(InputSplit)大小时100MB,那么,map数=(1000*1000)/100=10000
3 Hadoop Reducer
Reducer处理mapper的输出。在处理完这些数据后,会产生新的输出。最后在HDFS上存储输出数据。
Hadoop Reducer接收mapper产生的中间键值对作为输入,并对它们逐一运行Reducer函数,进行包括聚合,过滤,键值对合并等等一系列处理。Reducer首先处理由map函数生成的某个key的中间值,然后生成输出(0或多个键值对)。
key和reducer是一对一的,reducer彼此独立,因此key并行运行。用户可以决定reducer的数量,reducer的默认值是1.
3.1 Reducer的各个阶段
正如你从前面那副图看到的,Reducer分为3个阶段,下面我们就逐一讨论。
1 Reducer的Shuffle阶段
在此阶段,来自mapper的排序后的输出作为Reducer的输入。在Shuffle阶段,借助HTTP的帮助,框架获取所有mapper输出的相应分区。
2 Reducer的Sort阶段
在本阶段,来自不同mapper的输入被再次按key排序。shuffle和sort阶段是同时发生的。
3 Reduce阶段
在本阶段,在完成shuffle和sort之后,reduce任务会对键值对实施聚合。*OutputCollector.collect()*方法会将reduce任务的输出写到文件系统。Reducer的输出并不排序。
3.2 MapReduce中Reducer的数量
我们接下来讨论MapReduce的Reducer数量,以及如何改变这个数量。
使用Job.setNumreduceTasks(int),用户可以设置作业的reducer数量。reducer的恰当值是:
0.97(或1.75)*节点数*每个节点容器最大值
(*表示乘以)
使用0.95,当map完成时,reducer会立即启动并开始传输map输出结果。
使用1.75,第一轮reducer完成之后(有些节点处理的比较快),第二轮reducer会启动,这样做的目的是作业的负载平衡会更好。
增加MapReduce的Reducer数量:
- 增加了框架开销
- 增加负载均衡
- 发生故障成本更低
4 MapReduce中的键值对
键值对是MapReduce作业在执行时接收的记录实体。默认情况下,RecordReader使用TextInputFormat将数据转换成键值对。
Apache Hadoop主要用于数据分析。在数据分析时,我们会应用统计学以及逻辑学的技术来描述,解释和评估数据。Hadoop可以处理结构化以及半结构化的数据。在Hadoop中,键值对并不是数据的固有属性,我们只是选择它来分析数据。
4.1 MapReduce是如何生成键值对的
下面我们来说明Hadoop MapReduce是如何生成键值对的。在MapReduce中,在将数据传递给mapper之前,数据应该首先转换成键值对,因为mapper仅理解键值对数据。
在Hadoop MapReduce中,键值对是像下面这样生成的:
- InputSplit-它是数据的逻辑表示。每个独立的Mapper所处理的数据都以InputSplit形式表示。
- RecordReader-它和InputSplit交互,将数据分片转换成键值对形式的记录,以便被mapper读取。默认情况下,RecordReader使用TextInputFormat将数据转换为键值对。RecordReader会一直和InputSplit交互,直到文件结束。
在MapReduce中,map函数对指定的键值对进行处理,并产生出一个键值对列表,而Reduce函数则按相同的key进行分组,对值列表进行处理,最后生成另外一个键值对列表。Map的输出类型应该和Reduce的输入类型匹配,就像下面这样:
- Map:(K1,V1) -> list(K2,V2)
- Reduce:{K2,list(V2,…)}->list(K3,V3)
4.2 Hadoop中哪些地方产生键值对
Hadoop中键值对的生成取决于数据集和所需要的输出。通常,键值对在4个地方指定:Map输入,Map输出,Reduce输入,Reduce输出。
- Map输入
Map输入默认接受行偏移量作为key,该行文本内容作为值。通过定制InputFormat可以修改这一规则。
- Map输出
Map基本上负责过滤数据,并且提供一个基于key对数据分组的环境。
- key-可能是域/文本/对象,在reducer阶段会根据它进行数据分组和聚合
- value-可能是域/文本、对象,将会被每个独立的reduce方法进行处理
- Reduce输入
Map的输出将作为reduce的输入,因此它会和Map输出一样
- reduce输出
取决于实际需求
4.3 MapReduce键值对例子
假设存储在HDFS中文件的内容是:Jerry is a good man.通过InputFormat,我们可以定义这个文件如何分割和读取。默认情况下,RecordReader使用TextInputFormat将这个文件转换成键值对。
- key-文件中距首行的字节偏移量
- value-行的内容,排除结束符
那么对于上面文件的内容:
- key是0
- value是Jerry is a good man.
5 总结
Mapper接收有inputSplit生成的键值对,然后生成中间键值对。我们将所有复杂逻辑,业务规则,重要代码都在mapper阶段执行。
Hadoop Reducer是MapReduce处理的第二阶段。Hadoop Reducer通过3个阶段来完成数据聚合或者分类求和计算。这3个阶段是shuffle,sort和reduce。最后,Reducer将最终输出结果存储在HDFS中。
在Hadoop中,RecordReader和InputSplit交互默认使用TextInputFormat来生成键值对。因此,key是文件内距首行的字节偏移量,而值是排除行结束符之后的内容。