requests,prettytable,简单实现采集12306火车信息
requests,prettytable,简单实现采集12306火车信息
- 获取车站信息简码
- 分析返回的json数据并且构造查询地址
- prettytable 设置输出格式
代码:
1.分析
https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.9066地址查看车站有指定的简码,查询前我们需要先获取对应信息

#获取车站信息简码
import requests
import re
class station():
def __init__(self,url,headers):
self.url=url
self.headers=headers
def get_stations(self):
response=requests.get(self.url,self.headers)
#使用正则匹配中文,简码并且生成一个字典
station=dict(re.findall(r'([\u4e00-\u9fa5]+)\|([A-Z]+)',response.text))
station=dict(zip(station.keys(),station.values()))
return station
2.查询返回结果是
https://kyfw.12306.cn/otn/leftTicket/queryA?leftTicketDTO.train_date=2018-09-20&leftTicketDTO.from_station=BJP&leftTicketDTO.to_station=SHH&purpose_codes=ADULT 的json数据

现在调用之前的车站信息,匹配用户的输入构造查询url
from info import station
url="https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.9065"
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36',
}
stations=station(url,headers)
zhan=stations.get_stations()
origin=input("请输入起始站:\n")
f =zhan[origin]
destination=input("请输入目的地:\n")
d=zhan[destination]
shenfen=input("请输入身份(普通/学生):\n")
if shenfen=="普通":
purpose_codes='ADULT'
else:
purpose_codes='0X00'
date=input("请输入乘车时间:\n")
date=str(date)
ticketurl='https://kyfw.12306.cn/otn/leftTicket/queryA?leftTicketDTO.train_date='+date+'&leftTicketDTO.from_station='+f+'&leftTicketDTO.to_station='+d+'&purpose_codes='+purpose_codes+''
print ('正在查询'+date+origin+'至'+destination+'的列车,请稍等...')
3.最终显示
PrettyTable 指定输出的栏目,通过dic的key属性查找需要的信息,使用split构造一个list通过for循环输出
import requests
from prettytable import PrettyTable
from get_trains import ticketurl
import json
from pyquery import PyQuery as pq
from get_stations import get_key
response=requests.get(ticketurl)
results=response.text
row=json.loads(results)
trains=row['data']
trainslist=PrettyTable()
trainslist.field_names = ["车次","车站","时间","历时","商务座","一等座","二等座","高级软卧","软卧","硬卧","软座","硬座","无座"]
trainslist.align["车次"]='l'
num=len(trains['result'])
for item in trains['result']:
trainsinfo=item.split('|')
trainslist.add_row([trainsinfo[3],
'\n'.join([str(get_key(trainsinfo[4])),
str(get_key(trainsinfo[7]))]),
'\n'.join([trainsinfo[8],trainsinfo[9]]),
trainsinfo[10],
trainsinfo[32] or trainsinfo[25],
trainsinfo[31],
trainsinfo[30],
trainsinfo[21],
trainsinfo[23],
trainsinfo[28],
trainsinfo[24],
trainsinfo[29],
trainsinfo[26]])
print ('查询结束,共有 %d 趟列车。'%num )
print (trainslist)
具体json中返回的数据需要去分析哪些对应,比如车次,时间,座位数等
“vByxp92FmyVPMB9V4afDAbg3goI%2F%2BrSLpFQTKLYGJR1os8jrqbPoWVHLek%2FotIip4sWch%2B%2FaOZsC%0AnXTWMf0lW%2FHTLQbBxvE0SZsP2i%2FxsWuMMVmmR5c99l%2Ba1TJhqPc80ZZF%2BqIwQIJLCDhYe0sHYDn7%0ASeHzX0DpoIzgbKryK%2FSs49Ttn7r8gYcosCmY7J1k5e4%2BxdJUwCQK738WY4Oo%2F4Nu4cRrf%2BhoDKhD%0AHiwBCMn4sKMWjlbAIMTZRTjfnnDcmUKn19zVOyg%3D|预订|24000C20870L|C2087|VNP|TJP|VNP|TJP|14:53|15:23|00:30|Y|pTXEKpV0PnflkXFeIXk6cex2Oqm%2FhitX3h6%2BQ%2B9B%2BVlJWSXxwjkRkGGmmE4%3D|20180920|3|P3|01|02|1|0|||||||无||||有|2|8||O090M0O0|O9MO|0”
此时输出结构中站点信息是简码,需要通过简码转换为对应的文字
from info import station
url="https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.9065"
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36',
}
s=station(url,headers)
s=s.get_stations()
def get_key(value):
# 生成式实现匹配value转换站点中文名
return [k for k,v in s.items() if v==value]
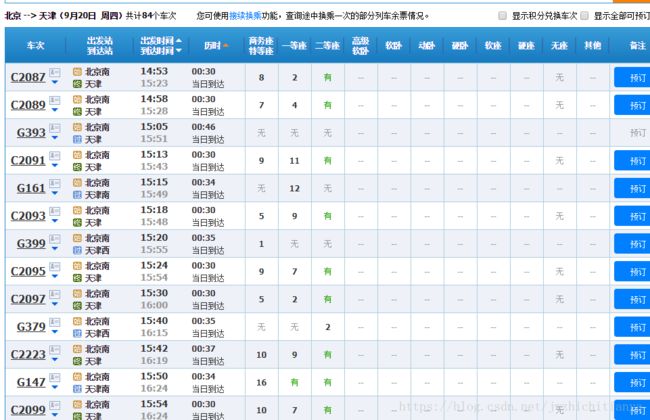

虽然实现了,但是细节上还需做更多处理,同时最终显示可以加入票价,或者使用pyqt做成gui界面的