OpenStack运维中资源调度的错误排查
回望二十一世纪已过去的十六个年头,云计算可谓赚足了风头,而作为云计算IaaS(基础设施即服务)模式的新贵,OpenStack打出生起(2010年7月份NASA和Rackspace公司将其开源)便立马集众方IT大佬如IBM、Red Hat、HP、Inter等宠爱于一身,一时间IT界众多门派、各路草莽纷纷出钱出力以促进OpenStack的茁壮成长,而OpenStack不负众望,以其开源免费、可扩展、高兼容等优良品德立名IT界,迅速坐稳开源云市场占用率头把交椅。
本文将基于OpenStack最新release的liberty版本,分析OpenStack的虚拟机资源调度服务nova-scheduler的调度流程,并逐步说明OpenStack管理员在进行资源调度的错误排查过程中的尴尬境遇,然后提出一个OpenStack资源调度错误排查的改进方案,最后,本文会为大家展示IBM PRS(Platform Resource Scheduler)基于此方案的实现版本。
OpenStack虚拟机的资源调度
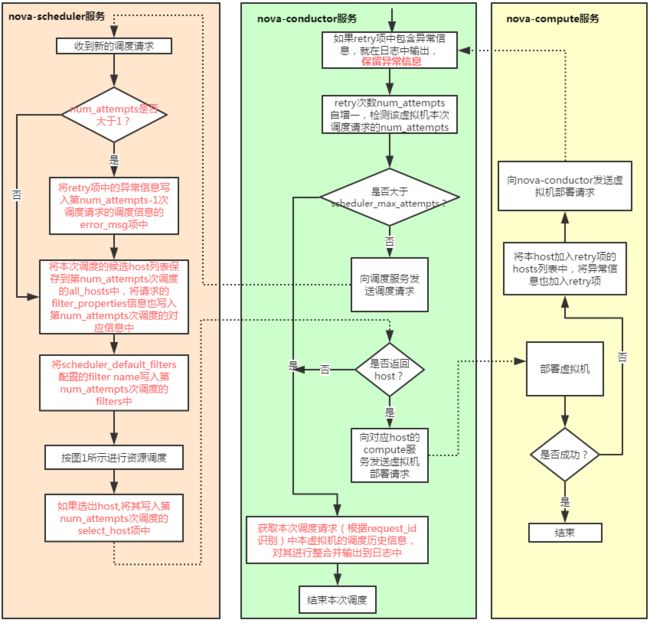
OpenStack对虚拟机的资源调度由nova模块的nova-scheduler服务实现,根据调度策略的不同,有两个插件:基于filter的调度和基于随机策略的调度,其中基于随机策略的调度仅对正在服务的host随机选择,不进行任何资源审查,在实际生产环境中基本上不会用到,所以本文仅就OpenStack的默认的调度策略:基于filter的调度进行分析。如图1所示,该策略主要通过三步完成虚拟机的资源调度返回候选host:
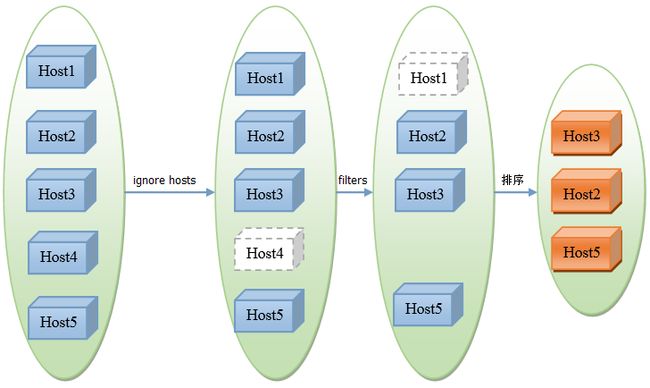
Step 1:获取所有host的信息,如果调度请求中要求忽略一些host(ignore hosts),就将这些host从本次的候选host中删除掉(一种特殊的情况是如果调度请求中要求虚拟机只能调度到一些host或者节点上,则只保留这些host作为候选host,不会对这些host做进一步额外的资源审查即step 2便直接返回)。
Step 2:将第一步中返回的host列表依次迭代地通过scheduler_default_filters配置的所有filter的host_passes处理函数,该函数会过滤掉不满足相应filter条件的host。
Step 3:对第二步返回的host列表根据scheduler_weight_classes配置的weigher对候选host进行排序。
至此调度服务完成对虚拟机的资源调度,nova-conductor服务将会向调度服务选出的host所对应的nova-compute服务发出虚拟机部署请求。由于OpenStack调度服务固有的race condition,当虚拟机在compute节点部署失败时,相应nova-compute服务将会向nova-conductor服务发送重新部署对应虚拟机的请求,用户可以通过scheduler_max_attempts配置最多可以容忍compute部署失败的次数,该reschedule机制如图2所示: 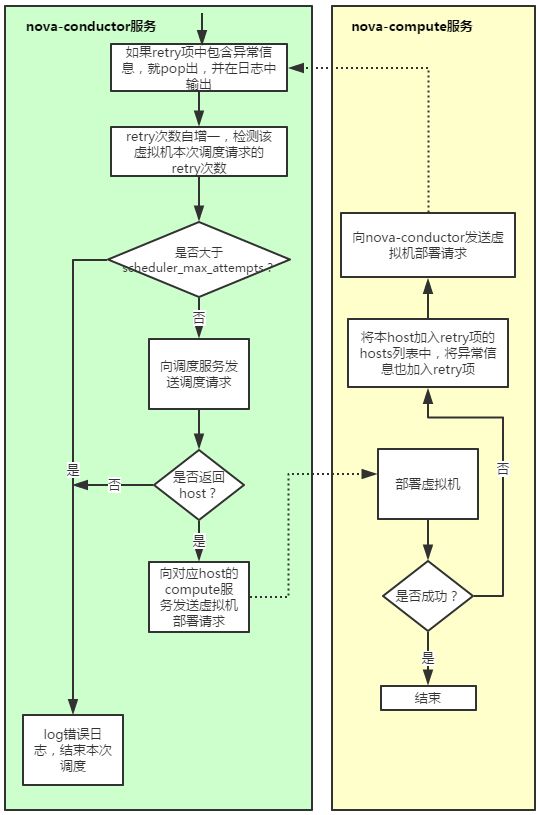
由上可知,当我们在部署一个虚拟机的时候,本质上有两类型的错误可能导致部署失败:第一是调度服务发现没有host可以满足虚拟机的资源需求,第二是虚拟机在调度服务选出的目标host上部署时因为某种原因部署失败(如卷请求超时或者网卡创建失败等等)。我们在虚拟机部署失败的错误排查时,需要从这两类错误类型逐一排查。怎么查呢?当然是看日志(其实也可以首先通过nova show命令查看fault项,但基本上通过这个信息是看不出错误所在的),从图2可以看出,我们应该从nova-conductor的日志开始,然后根据对应错误信息决定下一步该看nova-scheduler的日志还是对应nova-compute的日志。下面举一个最简单的由第一种错误导致虚拟机部署失败的错误排查的例子来说明一下OpenStack原生资源调度的错误排查是如何让管理员望而生畏的。
step 1:发起部署虚拟机的请求(通过选择一个资源需求量极大的flavor确保系统中没有host可以满足)。

step 2:等虚拟器显示ERROR状态时,查看nova-conductor的日志,如下所示,nova-conductor展示完整的事故现场,理直气壮地说:看,都怪nova-scheduler,它就没有选出来一个满足要求的host。
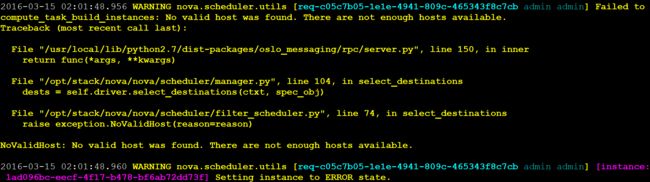
step 3:好吧,看一下nova-scheduler怎么说,如下所示,你看得出来它说啥了没? ![]()
step 4:唉,它不愿意明说,我们只能分析了。友情提示:通过阅读代码,nova-scheduler的日志其实是告诉我们RetryFilter和AvaiabilityZoneFilter没有过滤掉任何host,都是RamFilter干的,这家伙一下子将全部的两个host都给pass掉了。
至此,你也许觉得,貌似也没啥难度的嘛,稍微有点经验的管理员是可以从上面这条信息读出问题所在的,那我把虚拟机请求的内存降低点不就OK了(当然土豪们也可以任性地为host加内存)。OK,那我们降低内存需求再来一遍:
step 1:选择内存需求较低的flavor重新部署。
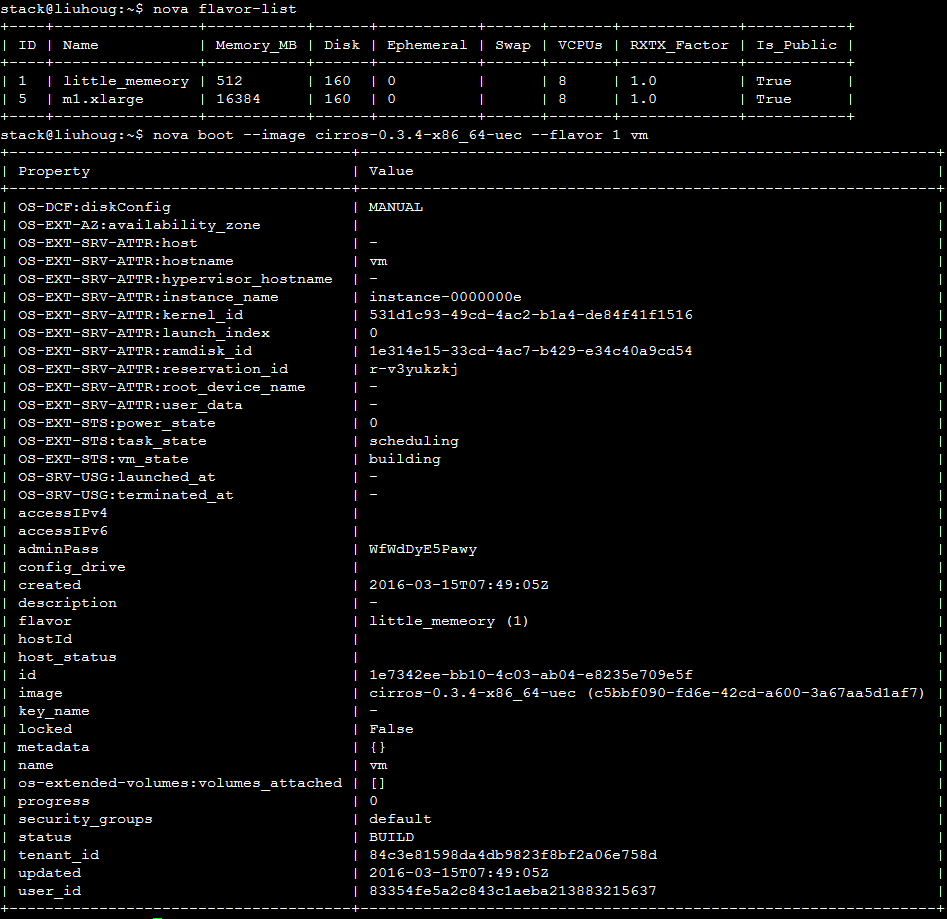
step 2:虚拟机还是会变成ERROR的,去看看nova-conductor的日志吧(其实不用看了,nova-conductor依旧会扔下那句老话将责任推给nova-scheduler)。
step 3:看一下nova-scheduler怎么说。咦!好熟悉的样子,但貌似跟刚才不完全一样。
![]()
step 4:有了上一轮的经验,可以看出这段话的意思是:RamFilter没有过滤任何host,这次都是DiskFilter干的。
如果你还是很有耐性地说,噢,那我降低点Disk的请求(当然,土豪朋友们继加内存之后,可以继续扩充一下硬盘容量)。作者可以负责任地说,就作者做实验的环境来说,按这个思路走下去,一会儿你还得继续降CPU的请求。别忘了,作者的实验环境仅仅有两个compute节点,而且举的这个例子都是只有某一个filter一下子就pass掉所有的host。假设在一个有一千台compute节点的环境中,nova-scheduler出现下面这样子的日志时,你会怎么办?
![]()
这段日志告诉我们系统中有800台host是满足虚拟机对AvailabilityZone的请求,而这800台host中有300台满足虚拟机对内存的请求,300台host中有100台满足虚拟机对硬盘的请求,但是很不幸,这100台host都不满足虚拟机对CPU的请求。还有,满足某一请求的那些host具体是哪些,劳烦你通过nova hypervisor-show命令一个一个的排查去(因此出于以人为本的精神,作者强烈要求OpenStack管理员手册至少应该提出,遇到这种情况时,建议管理员暂时离开一会儿,去冲杯咖啡,看看窗外的美景,告诉自己这世界其实还有很多美好的东西)。事实上,我不得不告诉你这还不是最复杂的错误排查情景,生活中永远只有比较级没有最高级,比如,由于造成某一个虚拟机部署失败的是前文提到的第二种错误,从而触发多次reschedule,而在某次reschedule时,nova-scheduer服务终于宣布再也选不出满足需求的host了,这时,管理员想要进行错误排查既要从nova-conductor中逐行寻找相关的compute错误,还得继续从nova-schedule中寻找为啥不能部署到其他host的原因(想想都觉得头疼)。
OpenStack资源调度错误排查的改进
从上文所述的错误排查情景中可以看出,当资源调度失败时(由图2可以看出,当调度服务无法选出目标host或者reschedule次数已经超过预设的最大次数时,nova-conductor便宣布该虚拟机的本次调度失败),造成资源调度错误排查困难的主要原因有三:
第一:候选hosts迭代通过filters过滤,当某一个filters发现已经没有host提供给下一个filter继续过滤时,则停止本次调度,从而导致管理员无法获知还没出力的filter是否也会pass掉一些host(如上面的例子中,通过了RamFilter并不代表也能通过其他的filter);
第二:filter过滤掉一部分host时,日志中只能看到过滤掉多少个host,无法获知具体过滤掉的是哪些host;
第三:当出现reschedule时,相关的错误日志太分散,不能给管理员一个一目了然的错误总结。
基于此,可以设想,解决了这三个问题的错误排查信息应该是这样子的:对虚拟机的资源调度请求的每次reschedule的具体信息(包括错误信息、每个filter的资源需求、所选的目标host等)在日志中同时集中地输出。这就需要缓存每次调度时的调度相关的原始信息,如当时参与调度的所有host信息、系统配置的所有filter以及filter_properties参数(该参数包含了本次请求的所有信息),而且如果该次调度的失败是由于选出的host对应的compute服务在进行部署时的异常导致的,还需要将对应的host名字和compute返回的异常信息缓存。所以只要有如下结构的虚拟机资源调度的历史信息,便可以输出一个可以极大解放管理员的调度排错日志,至于以怎么样的一种表达方式来告诉管理员what happened,你可以选择自己认为能让管理员明白的任何一种方式来组织。
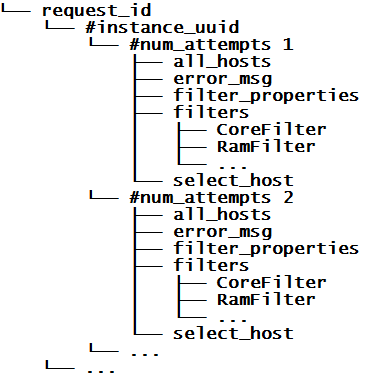
我们并不需要从零写一个nova-conductor或者nova-scheduler来改进错误排查日志,事实上,只需要稍微修改下nova-conductor和nova-scheduler的部分逻辑即可,添加或者修改的逻辑如图3红色字体所示:
FilterScheduler._schedule方法便可完成调度历史信息的缓存,至于nova-scheduler将调度历史信息缓存在哪里,就可以根据实际需求自作取舍:
直接通过nova-scheduler的FilterScheduler的一个新的属性缓存,然后只要SchedulerManager暴露一个RPC接口给nova-conductor就可以传输这些信息。但引入缓存,OpenStack就只能start一个nova-scheduler进程了,而且重启nova-scheduler会丢失已有缓存,但这个方案实现起来比较容易,可以适应规模较小的环境,而且基本上重启nova-scheduler恰好丢失了即将要用到的调度历史信息的几率也比较小(即使丢了,只是相关虚拟机的调度失败时,不能输出完整的错误排查信息,并不会影响虚拟机的正常操作);
将其写到一个公共持久化层,如将其存入etcd中,如此nova-conductor就可以直接从etcd中获取这些信息。该方案避开了方案1的短板,但是需要引入一个额外的持久化层,所幸现在有好多优秀易部署的开源软件(作者用的最多的就是etcd)可以完成这项工作,并不会带来太多的开销。
实际上,当一个虚拟机涉及调度的操作(目前包括boot/live-migration/migrate/resize/unshelve/evacuate/rebuild操作)结束(成功或者失败)时,调度历史信息就应该废弃掉,从而避免垃圾数据的积累。对于操作失败的case,nova-conductor在获取对应历史信息用来输出错误排查日志的时候可以顺便将其删掉;而对于操作成功的case,nova-compute服务并不会回调nova-conductor的接口,即nova-conductor是无法在虚拟机部署成功时立即删掉这些历史信息的,所以最直接的方法是在nova-compute服务相应操作的结尾调用nova-conductor一个新的RPC接口专门用来清理对应虚拟机的调度历史信息,可是这样子对compute服务的代码改动过于分散,不利于代码维护。如果有兴趣,可以利用OpenStack的消息通知机制来进行垃圾数据处理(OpenStack中对每个虚拟机的操作都会发出相应的通知信息,如compute服务在开始创建虚拟机时发出事件类型为compute.instance.create.end的信息,而在成功创建出虚拟机的时候会发出事件类型为compute.instance.create.end的信息,信息的payload字段包含相应虚拟机的具体信息),当监听到诸如compute.instance.create.end这样的虚拟机操作结束的通知信息,便可调用nova-conductor的新RPC接口清理对应虚拟机的调度历史信息,这种方案可以参考OpenStack ceilometer项目频繁使用的oslo_messaging的notification监听机制即可完成。
IBM PRS的资源调度的错误排查
PRS(Platform Resource Scheduler)是IBM Platform Computing公司基于OpenStack的商业化资源调度引擎,该产品集成了IBM Platform Computing公司的集群管理软件EGO(Enterprise Grid Orchestrator),可实现灵活的基于policy的资源调度管理服务,且百分百地兼容开源版本的OpenStack;同时PRS还提供可定制化的动态资源管理服务和虚拟机的HA服务等提升OpenStack用户体验的增强服务。其中,PRS的资源调度的错误排查与上述错误排查的改进方案比较相似。
为了减少代码维护,PRS没有对nova-conductor做改动,所有关于错误排查的改动都在nova-scheduler中进行,调度历史信息如上述第一种方式在内存中存储,当nova-scheduler选不出目的host时将历史信息整合输出到nova-scheduler的日志中并将历史信息删除,另外,PRS引入一个新的nova服务nova-ibm-notification用来监听PRS关注的通知信息并将其通过RPC调用的方式转发给PRS引入的增强服务(们),其中nova-scheduler收到涉及调度操作成功的信息时,便将对应调度历史信息删除。
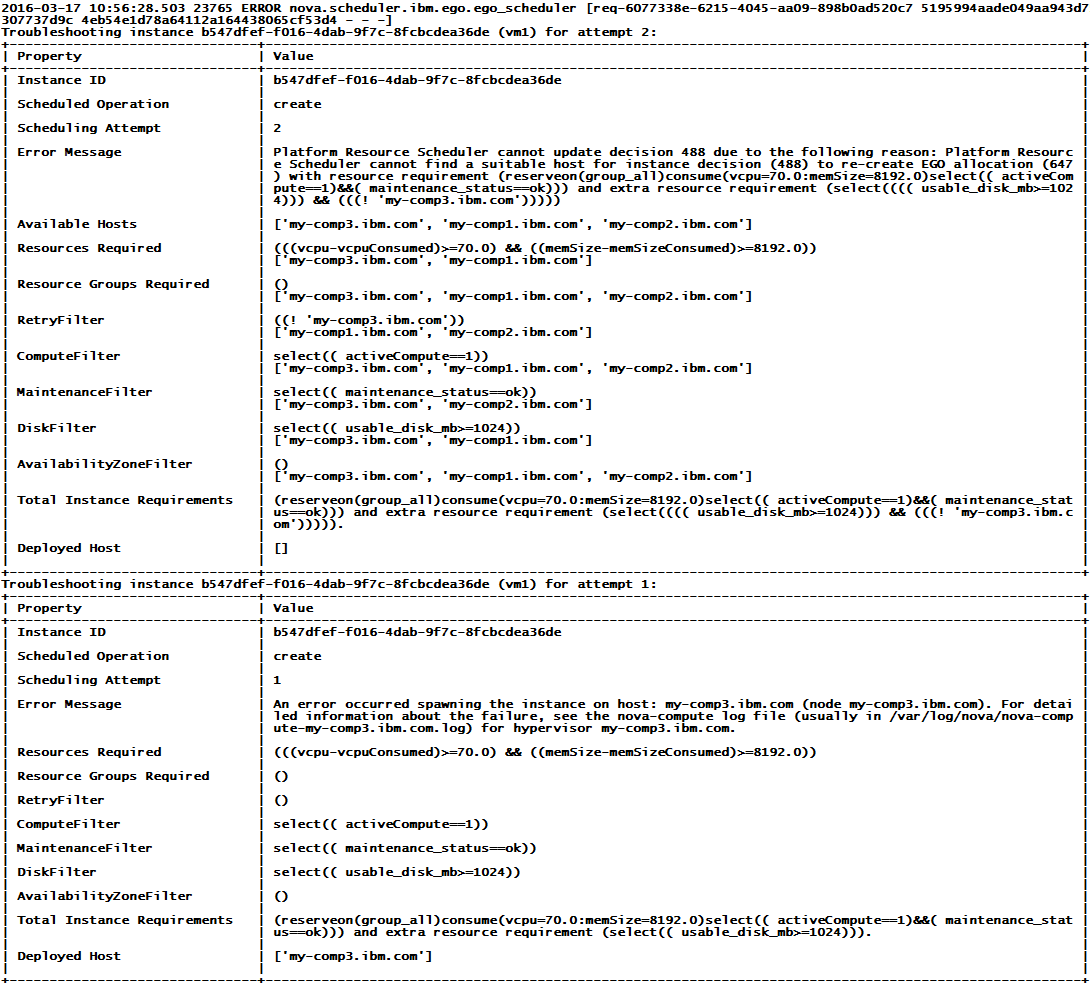
如下所示便是PRS的nova-scheduler日志中显示的用来做错误排查的报告,这份排错报告通过prettytable库(是的,OpenStack中CLI输出的那些表也是用这个库的函数显示的)组织成表的格式输出,从这份表中管理员可以很清晰地看出:系统为虚拟机vm1的创建进行了两次资源调度,第一次调度的时候系统为它选出my-comp3.ibm.com部署vm1,但是my-comp3.ibm.com在部署vm1的时候由于某种原因导致部署失败(这时候管理员可以查看该host上的nova-compute的日志上的详细信息进一步排查);当my-comp3.ibm.com在部署vm1失败时,OpenStack的reschedule机制会再次尝试为vm1选择目的host,但是可以看出RetryFilter(只有my-comp1.ibm.com和my-comp2.ibm.com满足需求),MaintenanceFilter(只有my-comp3.ibm.com和my-comp2.ibm.com满足需求)和DiskFilter(只有my-comp3.ibm.com和my-comp1.ibm.com满足需求)的资源需求发生了冲突,从而系统无法继续选出可以满足vm1部署需求的host。这时,管理员根据这样的信息可以做出抉择:如果想继续成功部署具有同样资源需求的vm1,可以根据my-comp3.ibm.com上的nova-compute日志中的错误信息修复错误,或者停止对my-comp1.ibm.com的维护恢复对它的使用(这个便是PRS利用调度历史信息告诉管理员what happened的方式,你的表达方式是什么样子的呢?)。
结束语
OpenStack已经发展成一个强大的生态系统,是来自世界不同公司、不同个体的共同结晶。OpenStack不设门槛,任何有着开放、共享的互联网精神的同学都可以参与其中,OpenStack期待你的加入。
作者简介:
刘侯刚([email protected]),2013年7月从西安交通大学毕业加入IBM Platform Computing系统科技部云计算部门,担任云计算开发部工程师,主要参与OpenStack相关的研发工作,涉及nova、ceilometer、heat等项目。
责编:魏伟,欢迎投稿 [email protected]
CSDN OpenStack技术交流群已经建立,欢迎加入,搜索微信号“k15751091376”,由管理员拉入。