数据库基本知识
数据库事务的四大特性为:
1. 原子性 Atomicity
原子性是指事务包含的所有操作要么全部成功,要么全部失败回滚
事务是用户定义的一个数据库操作序列,这些操作要么全做,要么全不做,是一个不可分割的工作单位。
2. 一致性 Consistency
一致性是指事务必须使数据库从一个一致性状态变换到另一个一致性状态,也就是说一个事务执行之前和执行之后都必须处于一致性状态。
3. 隔离性 Isolation
当多个用户并发访问数据库时,比如操作同一张表时,数据库为每一个用户开启的事务,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离。
4. 持续性 Durability
持久性是指一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作。
数据库范式:
参考:https://blog.csdn.net/SevenGirl2017/article/details/77678233
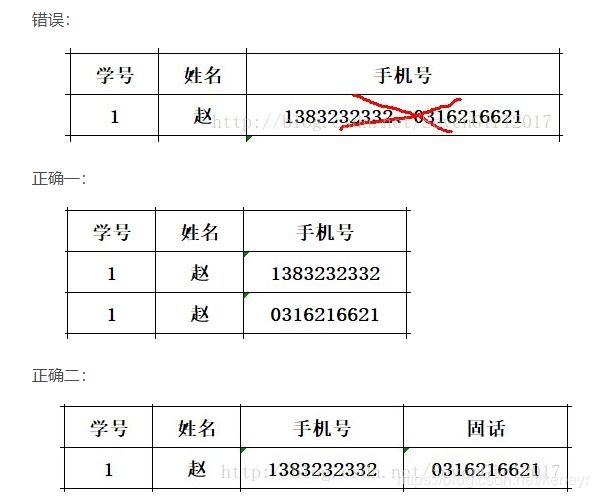
1NF: 每个关系r的属性值为不可分的原子值
当赵同学有两个手机号时,他不能将两个手机号存储在一个属性框中,需要分开存放,如下表所示。
2NF:满足1NF,非主属性完全函数依赖于候选键(左部不可约)
若一张表的数据包括:“学号、姓名、课程号、授课老师”中,设“学号、课程号”为主键,其中,一门课程可以有多个老师进行授课。会存在如下关系:
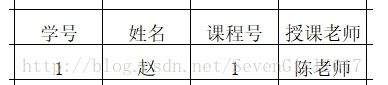
(学号、课程号)→姓名
学号→姓名
---------为局部依赖,即候选键的一部分可以推出非主属性系名
可分解为两个表,达到完全依赖:“学号、姓名”与“学号、课程号、授课老师”

3NF:满足2NF,消除非主属性对候选键的传递依赖
若一张表的数据包括:“学号、系名、系主任”,其中“学号”为主键,存在如下关系
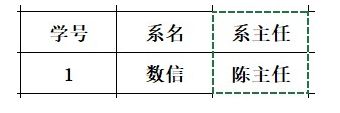
学号→系名→系主任
学号→系主任
---------为传递依赖
同样可分解为两张表:“学号、系名”和“系名、系主任”
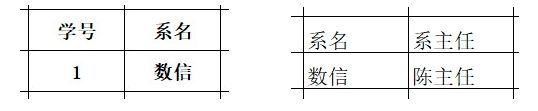
对于第三范式,我们反过来理解也是可以的,在表1(学号、系名),表2(系名、系主任)中,学号和系名都是各自表中的主键,所以系名依赖于学号,系主任依赖于系名。当三个数据放置在一张表中时,学号是可以推出系主任的。你可以理解为通过看学生张小二的学号,是可以推理出他的系主任是谁的。
BCNF:满足3NF,消除每一属性对候选键的传递依赖
若一张表的数据包括:“书号、书名、作者”其中,书号是唯一的,书名允许相同,一个书号对应一本书。一本书的作者可以多个,但是同一个作者所参与编著的书名应该是不同,希望没有说晕,看图看图。
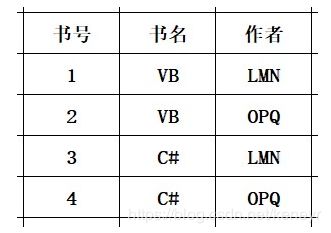
存在关系:
书号→书名
(书名、作者)→书号
其中,每一个属性都为主属性,但是上述关系存在传递依赖,不能是BCNF。即:
(书名、作者)→书号→书名
(书名、作者)→书名
我们可以通过分解为两张表,实现BCNF。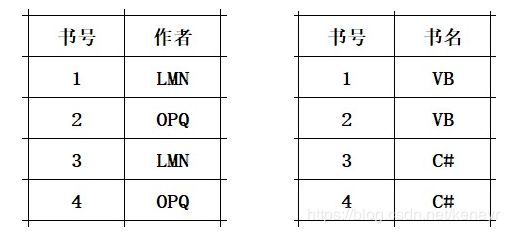
4NF:满足BCNF,消除非平凡且非FD的多值依赖(MVD)
非形式说:只要两个独立的1:N联系出现在一个关系中,那么就可能出现多只依赖。举例说明。
一个表中存在三个数据:“课程、学生、先修课”。假设2017级的计算机专业学生想要学习JAVA课程,那么他们需要先学习VB、C#、BS三门课,才可以选择进行JAVA课程。存在关系:
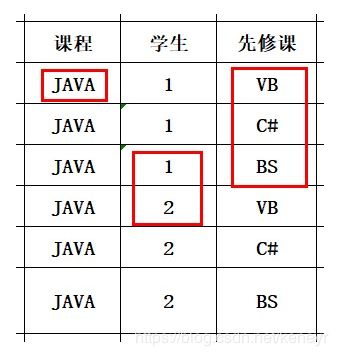
课程→学生
课程→先修课
两个均是1:N的关系,当出现在一张表的时候,会出现大量的冗余。所以就我们需要分解它,减少冗余。(Ps:该例子主要是为了说明概念帮助理解,具体应用中不会只是这样的简单粗暴的。)
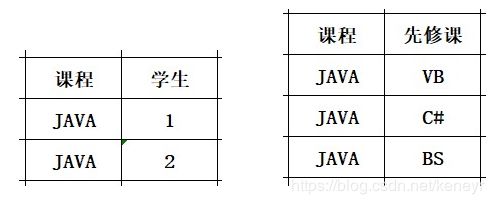
(基本概念补充):
R-关系模式
关系模型:用二维表的形式表示实体和实体间联系的数据模型
关系模型中,字段称为属性,字段值称为属性值,记录类型称为关系模型
关系模式名是R,记录称为元祖,元祖的集合称为关系或者实例 一般用大写字母A,B,C表示单个属性
关系中属性的个数称为元数(竖),元组的个数称为基数(横)
r-关系
U-属性集
FD-函数依赖
X→Y:"X函数决定Y","Y函数依赖于X"。
A⊆B A包含于B,A小,B大,B→A
元组:二维表中的行
属性:二维表中的列
超键:能唯一标识元组的属性集
候选键:不含多余属性的超建
主键:用户选作元组标识的候选键
外键:对于当前模式而言,是另一模式下的主键。
主属性:构成候选键的属性
局部依赖与完全依赖:对于FD W→A,如果存在X包含于W,有X→A成立,那么称W→A是局部依赖,否则成W→A是完全依赖。
五个基本的关系代数操作
并、差、笛卡尔积、选择、投影
笛卡尔积:
笛卡尔乘积是指在数学中,两个集合X和Y的笛卡尓积(Cartesian product),又称直积,表示为X × Y,第一个对象是X的成员而第二个对象是Y的所有可能有序对的其中一个成员。结果的属性个数等于x+y,结果的元组个数等于x*y.
举个例子,假设集合R={a, b},集合S={0, 1, 2},则两个集合的笛卡尔积为{(a, 0), (a, 1), (a, 2), (b, 0), (b, 1), (b, 2)}。在这个例子中,元组即为(a, 0), (a, 1), (a, 2), (b, 0), (b, 1), (b, 2),共六个。而属性为a,b,0,1,2,共5个,即为r+s。
参考博客:https://blog.csdn.net/weienjun/article/details/80869478
数据库语言四大类
DDL(Data Definition Language):数据库定义语言。定义关系模式、删除关系、修改关系模式。关系、属性。CREATE、ALTER、DROP等命令。
DML(Data Manipulation Language):数据库操纵语言。插入元组、删除元组、修改元组。元组。SELECT、UPDATE、INSERT、DELETE等命令。
DCL(Data Control Language):数据库控制语言。用来授权或回收访问数据库的某种特权,并控制数据库操纵事务发生的时间及效果。
GRANT、revoke
TCL(Transaction Control Language):事务控制语言
commit / rollback work
SQL支持的备份类型有四种:
1、完全数据库备份
2、差异备份或称增量备份
3、事务日志备份
4、数据库文件和文件组备份
数据库存储方式
外模式。外模式又称子模式或用户模式,对应于用户级。它是某个或某几个用户所看到的数据库的数据视图,是与某一应用有关的数据的逻辑表示。外模式是从模式导出的一个子集,包含模式中允许特定用户使用的那部分数据。用户可以通过外模式描述语言来描述、定义对应于用户的数据记录(外模式),也可以利用数据操纵语言(Data Manipulation Language,DML)对这些数据记录进行操作。外模式反映了数据库的用户观。
概念模式。模式又称概念模式或逻辑模式,对应于概念级。它是由数据库设计者综合所有用户的数据,按照统一的观点构造的全局逻辑结构,是对数据库中全部数据的逻辑结构和特征的总体描述,是所有用户的公共数据视图(全局视图)。它是由数据库管理系统提供的数据模式描述语言(Data Description Language,DDL)来描述、定义的,体现、反映了数据库系统的整体观。
内模式。内模式又称存储模式,对应于物理级,它是数据库中全体数据的内部表示或底层描述,是数据库最低一级的逻辑描述,它描述了数据在存储介质上的存储方式和物理结构,对应着实际存储在外存储介质上的数据库。内模式由内模式描述语言来描述、定义,它是数据库的存储观。 在一个数据库系统中,只有唯一的数据库, 因而作为定义 、描述数据库存储结构的内模式和定义、描述数据库逻辑结构的模式,也是唯一的,但建立在数据库系统之上的应用则是非常广泛、多样的,所以对应的外模式不是唯一的,也不可能是唯一的。
四类数据完整性
实体完整性(Entity Integrity)。实体完整性指表中行的完整性。主要用于保证操作的数据(记录)非空、唯一且不重复。即实体完整性要求每个关系(表)有且仅有一个主键,每一个主键值必须唯一,而且不允许为“空”(NULL)或重复。
实体完整性规则要求。若属性A是基本关系R的主属性,则属性A不能取空值,即主属性不可为空值。其中的空值(NULL)不是0,也不是空隔或空字符串,而是没有值。实际上,空值是指暂时“没有存放的值”、“不知道”或“无意义”的值。由于主键是实体数据(记录)的惟一标识,若主属性取空值,关系中就会存在不可标识(区分)的实体数据(记录),这与实体的定义矛盾,而对于非主属性可以取空值(NULL),因此,将此规则称为实体完整性规则。如学籍关系(表)中主属性“学号”(列)中不能有空值,否则无法操作调用学籍表中的数据(记录)。
域完整性(Domain Integrity)是指数据库表中的列必须满足某种特定的数据类型或约束。其中约束又包括取值范围、精度等规定。表中的CHECK、FOREIGN KEY 约束和DEFAULT、 NOT NULL定义都属于域完整性的范畴。
参照完整性(Referential Integrity)属于表间规则。对于永久关系的相关表,在更新、插入或删除记录时,如果只改其一,就会影响数据的完整性。如删除父表的某记录后,子表的相应记录未删除,致使这些记录称为孤立记录。对于更新、插入或删除表间数据的完整性,统称为参照完整性。通常,在客观现实中的实体之间存在一定联系,在关系模型中实体及实体间的联系都是以关系进行描述,因此,操作时就可能存在着关系与关系间的关联和引用。
在关系数据库中,关系之间的联系是通过公共属性实现的。这个公共属性经常是一个表的主键,同时是另一个表的外键。参照完整性体现在两个方面:实现了表与表之间的联系,外键的取值必须是另一个表的主键的有效值,或是“空”值。
参照完整性规则(Referential Integrity)要求:若属性组F是关系模式R1的主键,同时F也是关系模式R2的外键,则在R2的关系中,F的取值只允许两种可能:空值或等于R1关系中某个主键值。
R1称为“被参照关系”模式,R2称为“参照关系”模式。
注意:在实际应用中,外键不一定与对应的主键同名。外键常用下划曲线标出。
用户定义完整性(User-defined Integrity)是对数据表中字段属性的约束,用户定义完整性规则(User-defined integrity)也称域完整性规则。包括字段的值域、字段的类型和字段的有效规则(如小数位数)等约束,是由确定关系结构时所定义的字段的属性决定的。如,百分制成绩的取值范围在0~100之间等。
数据库设计阶段
按照规范的设计方法,一个完整的数据库设计一般分为以下六个阶段:
⑴ 需求分析:分析用户的需求,包括数据、功能和性能需求;
⑵ 概念结构设计:主要采用E-R模型进行设计,包括画E-R图;
⑶ 逻辑结构设计:通过将E-R图转换成表,实现从E-R模型到关系模型的转换;
⑷ 数据库物理设计:主要是为所设计的数据库选择合适的存储结构和存取路径;
⑸ 数据库的实施:包括编程、测试和试运行;
⑹ 数据库运行与维护:系统的运行与数据库的日常维护。
视图的作用
视图的作用:
* 简单性。看到的就是需要的。视图不仅可以简化用户对数据的理解,也可以简化他们的操作。那些被经常使用的查询可以被定义为视图,从而使得用户不必为以后的操作每次指定全部的条件。
* 安全性。通过视图用户只能查询和修改他们所能见到的数据。数据库中的其它数据则既看不见也取不到。数据库授权命令可以使每个用户对数据库的检索限制到特定的数据库对象上,但不能授权到数据库特定行和特定的列上。通过视图,用户可以被限制在数据的不同子集上:
使用权限可被限制在另一视图的一个子集上,或是一些视图和基表合并后的子集上。
* 逻辑数据独立性。视图可帮助用户屏蔽真实表结构变化带来的影响。
视图是一个虚拟表,其内容是查询定义。同真实的表一样,视图包含一系列带有名称的列和行数据。但是,视图并不在数据库中以存储的数据值集形式存在。行和列数据来自由定义视图的查询所引用的表,并且在引用视图时动态生成。对其中所引用的基础表来说,视图的作用类似于筛选。定义视图的筛选可以来自当前或其它数据库的一个或多个表,或者其它视图。分布式查询也可用于定义使用多个异类源数据的视图
其他
等值连接是从关系R和S的广义笛卡尔积中选取A和B“属性值”相等的元组,所以只要两个关系里面的有元组属性值相等就可以进行。 而自然连接是要求R和S中有一个或者多个相同的属性组
数据库的查询通配符:
1 、 LIKE'Mc%' 将搜索以字母 Mc 开头的所有字符串(如 McBadden )。
2 、 LIKE'%inger' 将搜索以字母 inger 结尾的所有字符串(如 Ringer 、 Stringer )。
3 、 LIKE'%en%' 将搜索在任何位置包含字母 en 的所有字符串(如 Bennet 、 Green 、 McBadden )。
4 、 LIKE'_heryl' 将搜索以字母 heryl 结尾的所有六个字母的名称(如 Cheryl 、 Sheryl )。
5 、 LIKE'[CK]ars[eo]n' 将搜索下列字符串: Carsen 、 Karsen 、 Carson 和 Karson (如 Carson )。
6 、 LIKE'[M-Z]inger' 将搜索以字符串 inger 结尾、以从 M 到 Z 的任何单个字母开头的所有名称(如 Ringer )。
7 、 LIKE'M[^c]%' 将搜索以字母 M 开头,并且第二个字母不是 c 的所有名称(如 MacFeather )。
题目:
根据下面给的表和 SQL 语句,问执行 SQL 语句更新多少条数据?sql 语句:
update Books set NumberOfCopies = NumberOfCopies + 1 where AuthorID in select AuthorID from Books group by AuthorID having sum(NumberOfCopies) <= 8
表中数据:
BookID Tittle Category NumberOfCopies AuthorID
1 SQL Server 2008 MS 3 1
2 SharePoint 2007 MS 2 2
3 SharePoint 2010 MS 4 2
5 DB2 IBM 10 3
7 SQL Server 2012 MS 6 1
解析:
- update Books
- set NumberOfCopies = NumberOfCopies + 1
- where AuthorID in
- select AuthorID
- from Books
- group by AuthorID
- having sum(NumberOfCopies) <= 8
4-7行为子查询,首先将数据按AuthorID 分组,然后分组之后按 sum(NumberOfCopies) <= 8 过滤,最后将取出过滤结果中的AuthorID 。
那么:分组结果为:
1 SQL Server 2008 MS 3 1
7 SQL Server 2012 MS 6 1
2 SharePoint 2007 MS 2 2
3 SharePoint 2010 MS 4 2
5 DB2 IBM 10 3
过滤结果为:
2 SharePoint 2007 MS 2 2
3 SharePoint 2010 MS 4 2
子查询的结果为:
2
综上,可以将原sql语句改写成如下内容:
- update Books
- set NumberOfCopies = NumberOfCopies + 1
- where AuthorID in (2)
所以,更新结果为:
2 SharePoint 2007 MS 3 2
3 SharePoint 2010 MS 5 2
有 2 个表,表 1 为邮轮订单表: CruiseOrder ,表 2 为用户表: B2CUser
CruiseOrder:
OrderSerialId B2CUserld OrderPersons OrderAmount
Dc00001 1 2 4000
Dc00002 2 3 6000
Dc00003 3 4 8000
B2CUser:
B2CUserId B2CUserName
1 赵先生
2 钱女士
3 孙先生
小明写了两个 SQL 语句:
SELECT OrderSerialId,B2CUserName,OrderPersons,OrderAmount FROM CruiseOrder co
LEFT JOIN B2CUser bu ON co.B2CUserId=bu.B2CUserId and bu.B2CUserName=’赵先生’
SELECT OrderSerialId,B2CUserName,OrderPersons,OrderAmount FROM CruiseOrder co
LEFT JOIN B2CUser bu ON co.B2CUserId=bu.B2CUserId WHERE bu.B2CUserName=’赵先生’请问两个语句执行结果一样还是不一样:
解析:
A left join B是以A表的记录为基础的,A可以看成左表,B可以看成右表,left join是以左表为准的。换句话说,左表(A)的记录将会全部表示出来,而右表(B)只会显示符合搜索条件的记录(例子中为: A.aID = B.bID)。B表记录不足的地方均为NULL。
第1步:首先咱们先看看,两个sql语句共同的sql语句(SELECT OrderSerialId,b2cusername,orderpersons,OrderAmount FROM cruiseorder co LEFT JOIN b2cuser bu on bu.B2cuserid = co.b2cuserid )执行的结果,结果集记为RESULT(方便后面):
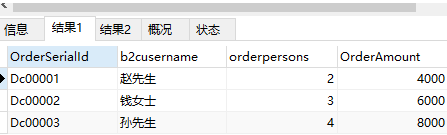
第2步:第一个sql语句没有where语句,只有on条件语句,这个就是用上面补充说明的那个结论。记录不足的部分变为NULL
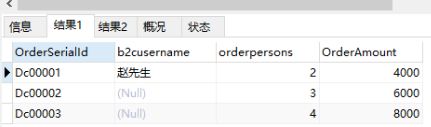
第3部:.第二个sql语句用的是where bu.b2cusername='赵先生',这里是用第1步的结果集RESULT之后,设置的where条件,所以只会筛选一条

一条SQL语句中,group by子句应位于什么位置
在where子句关键字之前在where子句之后在from关键字之前在order by子句之后解析:
select的执行顺序为:from where group having order by limit
关系模式R(a,b,c,d,)中关系代数表达式σ3<'4'(R)等价于SQL语句?
解析:
σ表示关系代数选择操作 ;
σ3<'4'(R) 代表:从R中选择第三列的属性值小于4的行;
Select * from R where c<'4'符合数据库设计第三范式(3NF)的数据表设计是( )
学生{id, name, age},学科{course's name, course's id},分数{id, course's id, score}学生{id, name, age},分数{id, course's name, score}分数{student's name,
score, course's name}学科{id, name},分数{student's name, id, score}解析:A
关于主键,描述错误的是()
一个表可以有多个主键主键是可以为空的建立主键的同时也会建立一个唯一性索引主键就是唯一索引解析:
一个表的主键只能有一个,(同时一个主键可以由多个字段组成)主键不可以为null
唯一索引可以有多个,并且唯一索引可以多个数据为null
主键可作为其他表的外键
所以答案是ABD,只有C是正确的
现有表book,主键bookid设为标识列。若执行语句:select * into book2 from book, 以下说法正确的是?
若数据库中已存在表book2, 则会提示错误。
若数据库中已存在表book2, 则语句执行成功,并且表book2中的bookid自动设为标识。
若数据库中不存在表book2, 则语句执行成功,并且表book2中的bookid自动设为主键。
若数据库中不存在表book2, 则语句执行成功,并且表book2中的bookid自动设为标识。
解析:
select into from 和 insert into select都是用来复制表,两者的主要区别为: select into from 要求目标表不存在,因为在插入时会自动创建。insert into select from 要求目标表存在,答案选AD
关于索引下面哪些描述是正确的:( )
索引是为了提高查询效率的,通过建立索引查询效率会得到提高
索引对数据插入的效率有一定的影响
唯一索引是一种特殊的索引,表中的行的物理顺序与索引顺序一致,且不允许两行数据在索引列上有相同的值
每个表都必须具有一个主键索引
对于数据重复度高,值范围有限的列如果建索引建议使用位图索引
可以在多个列上建立联合索引
解析:BEF
若事务 T 对数据对象 A 加上 S 锁,则( )。
事务T可以读A和修改A,其它事务只能再对A加S锁,而不能加X 锁。事务T可以读A但不能修改A,其它事务能对A加S锁和X锁。事务T可以读A但不能修改A,其它事务只能再对A加S锁,而不能加X 锁。事务T可以读A和修改A,其它事务能对A加S锁和X锁。解析:
基本的封锁类型有两种:排它锁和共享锁。
排它锁也称为独占或写锁。一旦事务T对数据对象A加上排它锁,则只允许T读取和修改A,其它任何事务既不能读取或修改A,也不能再对A加任何类型的锁,直到T释放A上的锁为止。
共享锁又称读锁。如果事务T对数据对象A加上共享锁,其它事务只能再对A加S锁,不能加X锁,直到事务T释放A上的S锁为止。
所以答案是C
运动会比赛信息的数据库,有如下三个表:
运动员ATHLETE(运动员编号 Ano,姓名Aname,性别Asex,所属系名 Adep), 项目 ITEM (项目编号Ino,名称Iname,比赛地点Ilocation), 成绩SCORE (运动员编号Ano,项目编号Ino,积分Score)。
写出目前总积分最高的系名及其积分,SQL语句实现正确的是:( )
SELECT Adep,SUM(Score)FROM ATHLETE,SCORE
WHERE ATHLETE.Ano=SCORE.Ano GROUP BY Adep HAVING SUM(Score)>=ANY
(SELECT SUM(Score) FROM ATHLETE,SCORE
WHERE ATHLETE.Ano=SCORE.Ano GROUP BY Adep)SELECT Adep,SUM(Score)FROM ATHLETE,SCORE
WHERE ATHLETE.Ano=SCORE.Ano GROUP BY Adep HAVING SUM(Score)>=SOME
(SELECT SUM(Score) FROM ATHLETE,SCORE WHERE ATHLETE.Ano=SCORE.Ano GROUP BY Adep)SELECT Adep,SUM(Score)FROM ATHLETE,SCORE WHERE ATHLETE.Ano=SCORE.Ano GROUP BY Adep HAVING SUM(Score) IN
(SELECT SUM(Score) FROM ATHLETE,SCORE WHERE ATHLETE.Ano=SCORE.Ano GROUP BY Adep)SELECT Adep,SUM(Score)FROM ATHLETE,SCORE WHERE ATHLETE.Ano=SCORE.Ano GROUP BY Adep HAVING SUM(Score)>=ALL
(SELECT SUM(Score) FROM ATHLETE,SCORE WHERE ATHLETE.Ano=SCORE.Ano GROUP BY Adep)解析:D。any是任意一个,all是所有
表结构如下:
CREATE TABLE `score` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`sno` int(11) NOT NULL,
`cno` tinyint(4) NOT NULL,
`score` tinyint(4) DEFAULT NULL,
PRIMARY KEY (`id`)
) ;
以下查询语句结果一定相等的是()
A.SELECT sum(score) / count(*) FROM score WHERE cno = 2;
B.SELECT sum(score) / count(id) FROM score WHERE cno = 2;
C.SELECT sum(score) / count(sno) FROM score WHERE cno = 2;
D.SELECT sum(score) / count(score) FROM score WHERE cno = 2;
E.SELECT sum(score) / count(1) FROM score WHERE cno = 2;
F.SELECT avg(score) FROM score WHERE cno = 2;
解析:DF
1、count(*)包括了所有的列,相当于行数,在统计结果的时候,不会忽略列值为NULL。
2、count(1)包括了忽略所有列,用1代表代码行,在统计结果的时候,不会忽略列值为NULL。
3、count(列名)只包括列名那一列,在统计结果的时候,会忽略列值为空。
题目:
已知成绩关系如图 2 所示。
执行 SQL 语句:
SELECT COUNT ( DISTINCT 学号)
FROM 成绩
WHERE 分数> 60
查 询结果中包含的元组数目是 ( )。

解析:
COUNT 和 DISTINCT 经常被合起来使用,目的是找出表格中有多少笔不同的资料 ,这里选出大于60分里的,共有多少项,其中DISTINCT表示多项重复的按一项计算。
所以有2个。
如下哪个不是数据库处理一个查询的步骤?
distributionoptimizationevaluationparsing and transiation解析:C。
1. 客户端发送一条查询给服务器;
2. 服务器先会检查查询缓存query ***,如果命中了缓存,则立即返回存储在缓存中的结果。否则进入下一阶段;
3. 服务器端进行SQL解析parsing、预处理transition,再由优化器optimization生成对应的执行计划;
4. 根据优化器生成的执行计划,调用存储引擎的API来执行分布distribution查询;
5. 将结果返回给客户端。
数据库以及线程发生死锁的原理是什么?
资源分配不当进程运行推进的顺序不合适系统资源不足进程过多解析:
产生死锁的原因主要是:
(1) 因为系统资源不足。
(2) 进程运行推进的顺序不合适。
(3) 资源分配不当等。
产生死锁的四个必要条件:
(1)互斥条件:一个资源每次只能被一个进程使用。
(2)请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
(3)不可剥夺条件:进程已获得的资源,在末使用完之前,不能强行剥夺。
(4)循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
四种处理死锁的策略:
1. 鸵鸟策略(忽略死锁);
2. 检测死锁并恢复;
3. 仔细对资源进行分配,动态地避免死锁;
4. 通过破坏引起死锁的四个必要条件之一,防止死锁的产生。
避免死锁:
死锁的预防是通过破坏产生条件来阻止死锁的产生,但这种方法破坏了系统的并行性和并发性。
死锁产生的前三个条件是死锁产生的必要条件,也就是说要产生死锁必须具备的条件,而不是存在这3个条件就一定产生死锁,那么只要在逻辑上回避了第四个条件就可以避免死锁。
避免死锁采用的是允许前三个条件存在,但通过合理的资源分配算法来确保永远不会形成环形等待的封闭进程链,从而避免死锁。该方法支持多个进程的并行执行,为了避免死锁,系统动态的确定是否分配一个资源给请求的进程。
预防死锁:具体的做法是破坏产生死锁的四个必要条件之一。
银行家算法:该算法需要检查申请者对各类资源的最大需求量,如果现存的各类资源可以满足当前它对各类资源的最大需求量时,就满足当前的申请。换言之,仅当申请者可以在一定时间内无条件归还它所申请的全部资源时,才能把资源分配给它。这种算法的主要问题是,要求每个进程必须先知道资源的最大需求量,而且在系统的运行过程中,考察每个进程对各类资源的申请需花费较多的时间。另外,这一算法本身也有些保守,因为它总是考虑最坏可能的情况。
学校数据库中有学生和宿舍两个关系:
学生(学号,姓名)和 宿舍(楼名,房间号,床位号,学号)
假设有的学生不住宿,床位也可能空闲。如果要列出所有学生住宿和宿舍分配的情况,包括没有住宿的学生和空闲的床位,则应执行( )
全外联接左外联接右外联接自然联接解析:A
(首先外连接会将两个表的字段合并在一起)
1、全外连接:将二者按照所有的记录列出,对应学生表来说,宿舍信息为空,对应宿舍表来说,学生信息为空
2、外连接:将二者按照学生表的所有记录列出,没有对应学生的宿舍信息为空
3、右连接:将二者按照宿舍表的所有记录列出,没有住宿的学生信息为空
4、这个就不用讲了
本博题目来自牛客~