计算机视觉实践 - 街景字符编码识别/关于Task1的一些笔记
计算机视觉实践 - 街景字符编码识别 关于Task1的一些笔记
- Task 1 赛题理解
- 学习情况
- 字符识别论文笔记
- ResNet18
- CRNN
- Baseline
- 自己的理解
- 遇到的问题
- Reference
最近参加了DataWhale的计算机视觉入门比赛,认识了很多大佬。虽然之前有过基于深度学习的一些实操经验,但对其中的原理还是不怎么懂,更别提模型的创新了。希望这次比赛过后,在理论和代码能力方面都能有所提高。
Task 1 赛题理解
- 赛题名称:零基础入门CV之街道字符识别
- 赛题目标:通过这道赛题可以引导大家走入计算机视觉的世界,主要针对竞赛选手上手视觉赛题,提高对数据建模能力。
- 赛题任务:赛题以计算机视觉中字符识别为背景,要求选手预测街道字符编码,这是一个典型的字符识别问题。
为了简化赛题难度,赛题数据采用公开数据集SVHN,因此大家可以选择很多相应的paper作为思路参考。
学习情况
-
查阅相关论文,阅读顺序打算是从定长字符识别到不定长字符识别,最后专业的解题思路是先检测再识别。这也是官方给出的不同阶段的解题思路。
这两天先看了CRNN和Baseline中的ResNet18的论文,等等奉上笔记。 -
试着跑了一下Baseline,还是有一些问题。
字符识别论文笔记
ResNet18
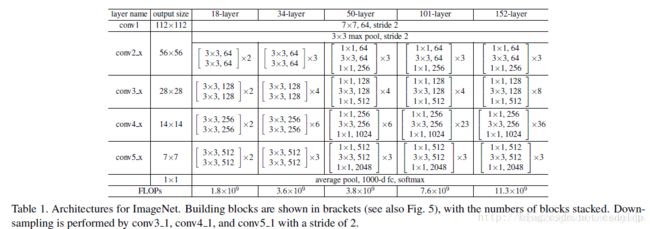
先来看一下Baseline中的检测框架

如上图所示,这个表示的是ResNet系列的结构,因为除了ResNet18, 还有Res34,Res50,Res101,Res152这些网络。
每个网络都包括三个主要部分:输入部分、输出部分和中间卷积部分(中间卷积部分包括如图所示的Stage1到Stage4共计四个stage)。
-
网络输入部分
所有的ResNet网络输入部分是一个size=7x7, stride=2的大卷积核,以及一个size=3x3, stride=2的最大池化组成,通过这一步,一个224x224的输入图像就会变56x56大小的特征图,极大减少了存储所需大小。 -
网络中间卷积部分
中间卷积部分通过3*3卷积的堆叠来实现信息的提取。上图中每个矩阵后乘的数字,就是后面的列[2, 2, 2, 2]和[3, 4, 6, 3]等则代表了bolck的重复堆叠次数。 -
残差块实现
输入数据分成两条路,一条路经过两个3*3卷积,另一条路直接短接,二者相加经过relu输出。 -
网络输出部分
网络输出部分很简单,通过全局自适应平滑池化,把所有的特征图拉成1*1,对于res18来说,就是1x512x7x7 的输入数据拉成 1x512x1x1,然后接全连接层输出,输出节点个数与预测类别个数一致。
以上参照的是一位知乎大佬的文章,他在后面还写了如何改造得到自己的ResNet,放在Reference里了。
CRNN
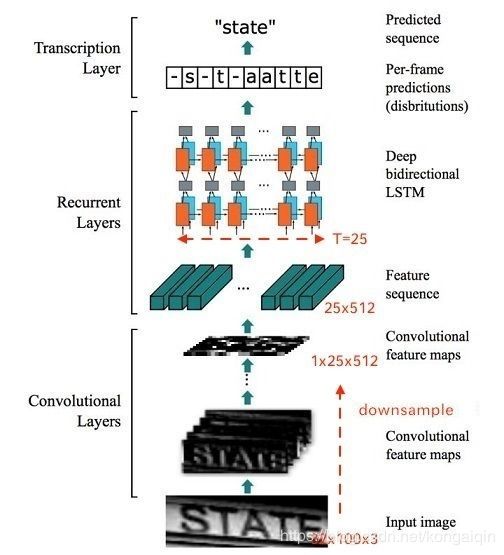
CRNN网络结构可以分为三个部分:特征提取、序列建模、转录
-
特征提取(Convolutional Layers)
这里的卷积层就是一个普通的CNN网络,用于提取输入图像的Convolutional feature maps,即将大小为(32,100,3)的图像转换为 (1,25,100)大小的卷积特征矩阵。 -
序列建模(Recurrent Layers)
这里的循环网络层是一个深层双向LSTM网络,在卷积特征的基础上继续提取文字序列特征。
RNN循环神经网络还没有好好看过,这边使用RNN的好处记一下笔记:1. 让网络可以结合上下文进行识别 2. 反传时将残差传给输入层。 -
转录(Transcription Layer)
将RNN输出做softmax后,为字符输出。
CRNN有几个优点:
- 它可以对整个文本进行识别,不定长
- 这个网络不在乎文字大小
- 可以自己添加词库(我的理解是,准确率就能提高不少
- 生成的模型小,准确率提高
这边要注意的是,CRNN没有全连接层,因为它就是要将特征提取后进行对比,我的理解是,如果有全连接层,就会把一些特征归一化(去掉了),会影响后面找出可能字符的过程。
Baseline
自己的理解
- 先将所需的库导入
import os, sys, glob, shutil, json
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
import cv2
from PIL import Image
import numpy as np
from tqdm import tqdm, tqdm_notebook
%pylab inline
import torch
torch.manual_seed(0) # 让每次得到的随机数是固定的
torch.backends.cudnn.deterministic = False # 每次返回的卷积算法将是不确定的
torch.backends.cudnn.benchmark = True # 可以在 PyTorch 中对模型里的卷积层进行预先的优化
import torchvision.models as models
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.autograd import Variable
from torch.utils.data.dataset import Dataset
- 定义读取数据集
class SVHNDataset(Dataset): # 这个类,可以让使用mini batch的时候进行多线程并行处理,加快准备数据集的速度
def __init__(self, img_path, img_label, transform=None):
```
TODO:
初始化文件路径+label,这边就是初始化该类的一些基本参数。
```
self.img_path = img_path
self.img_label = img_label
if transform is not None:
self.transform = transform
else:
self.transform = None
def __getitem__(self, index):
```
TODO:
从文件中读取数据,RGB图像
预处理 transform()
返回数据对:图像和标签
```
img = Image.open(self.img_path[index]).convert('RGB')
if self.transform is not None:
img = self.transform(img)
lbl = np.array(self.img_label[index], dtype=np.int)
lbl = list(lbl) + (5 - len(lbl)) * [10]
return img, torch.from_numpy(np.array(lbl[:5]))
def __len__(self):
return len(self.img_path)
Dataset类是Pytorch中所有数据集加载类中应该继承的父类。这好像是pytorch独有的,解决视觉问题的基础是定义一个数据集,keras和tenseflow里面就没有。__getitem__和 __len__这两个私有成员函数必须被加载,不然会报错。
__getitem__:编写支持数据集索引的函数,接收一个index,返回图像和标签,这个index通常是一个list,里面包含了图像数据的路径和标签信息。
__len__:表示返回数据集的大小
关于RGB:对于彩色图像,不管其图像格式是PNG,还是BMP,或者JPG,在PIL中,使用Image模块的open()函数打开后,返回的图像对象的模式都是RGB。而对于灰度图像,不管其图像格式是PNG,还是BMP,或者JPG,打开后,其模式为L。
3. 定义读取数据
train_path = glob.glob('input/mchar_train/*.png')
train_path.sort()
train_json = json.load(open('input/mchar_train.json'))
train_label = [train_json[x]['label'] for x in train_json]
print(len(train_path), len(train_label))
train_loader = torch.utils.data.DataLoader(
SVHNDataset(train_path, train_label,
transforms.Compose([
transforms.Resize((64, 128)),
transforms.RandomCrop((60, 120)),
transforms.ColorJitter(0.3, 0.3, 0.2),
transforms.RandomRotation(10),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])),
batch_size=8, # 实现数据分批次读取
shuffle=True, # 随机挑选数据进行读取,洗牌操作,打乱内部顺序
num_workers=5, # 并行加载数据,利用多核处理器加快载入数据的效率
)
val_path = glob.glob('input/mchar_val/*.png')
val_path.sort()
val_json = json.load(open('input/mchar_val.json'))
val_label = [val_json[x]['label'] for x in val_json]
print(len(val_path), len(val_label))
val_loader = torch.utils.data.DataLoader(
SVHNDataset(val_path, val_label,
transforms.Compose([
transforms.Resize((60, 120)),
# transforms.ColorJitter(0.3, 0.3, 0.2),
# transforms.RandomRotation(5),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])),
batch_size=8,
shuffle=False, # 注意!由于是测试集,所以不用进行洗牌操作
num_workers=3,
)
transform.Compose就是一类预处理操作,数据扩增方法。
Dataset 和Dataloader的区别就是,Dataset提供的是单个样本的索引,Dataloader则是可以封装成一个batch进行读取
4. 定义分类模型
class SVHN_Model1(nn.Module):
def __init__(self):
super(SVHN_Model1, self).__init__()
model_conv = models.resnet18(pretrained=True) # 与训练模型
model_conv.avgpool = nn.AdaptiveAvgPool2d(1) # 这边把最后的池化层做了一些改动
model_conv = nn.Sequential(*list(model_conv.children())[:-1])
self.cnn = model_conv
# 多分类的5个分支,全连接层
self.fc1 = nn.Linear(512, 11) # 11类是因为加了一个填充X
self.fc2 = nn.Linear(512, 11)
self.fc3 = nn.Linear(512, 11)
self.fc4 = nn.Linear(512, 11)
self.fc5 = nn.Linear(512, 11)
def forward(self, img):
feat = self.cnn(img)
# print(feat.shape)
feat = feat.view(feat.shape[0], -1)
c1 = self.fc1(feat)
c2 = self.fc2(feat)
c3 = self.fc3(feat)
c4 = self.fc4(feat)
c5 = self.fc5(feat)
return c1, c2, c3, c4, c5
Pytorch当中只需定义模型和前向传播,pytorch会自动进行反向传播
5. 训练与验证
def train(train_loader, model, criterion, optimizer, epoch):
# 切换模型为训练模式
model.train()
train_loss = []
for i, (input, target) in enumerate(train_loader): # 迭代器,枚举数据并从下标0开始
if use_cuda:
input = input.cuda()
target = target.cuda()
c0, c1, c2, c3, c4 = model(input)
loss = criterion(c0, target[:, 0]) + \
criterion(c1, target[:, 1]) + \
criterion(c2, target[:, 2]) + \
criterion(c3, target[:, 3]) + \
criterion(c4, target[:, 4])
# 这边用了个定长字符识别的模型,所以计算loss的时候,是把5个字符的outputs和labels放入loss函数当中进行计算,交叉熵损失
# loss /= 6
optimizer.zero_grad() # 梯度清零,就是把loss关于权重的导数变为0
loss.backward() # 反向传播
optimizer.step() # 利用计算的得到的梯度对参数进行更新
train_loss.append(loss.item())
return np.mean(train_loss)
def validate(val_loader, model, criterion):
# 切换模型为预测模型
model.eval()
val_loss = []
# 不记录模型梯度信息
with torch.no_grad():
for i, (input, target) in enumerate(val_loader):
if use_cuda:
input = input.cuda()
target = target.cuda()
c0, c1, c2, c3, c4 = model(input)
loss = criterion(c0, target[:, 0]) + \
criterion(c1, target[:, 1]) + \
criterion(c2, target[:, 2]) + \
criterion(c3, target[:, 3]) + \
criterion(c4, target[:, 4])
# loss /= 6
val_loss.append(loss.item())
return np.mean(val_loss)
def predict(test_loader, model, tta=10):
model.eval()
test_pred_tta = None
# TTA 次数
for _ in range(tta):
test_pred = []
with torch.no_grad():
for i, (input, target) in enumerate(test_loader):
if use_cuda:
input = input.cuda()
c0, c1, c2, c3, c4 = model(input)
if use_cuda:
output = np.concatenate([
c0.data.cpu().numpy(),
c1.data.cpu().numpy(),
c2.data.cpu().numpy(),
c3.data.cpu().numpy(),
c4.data.cpu().numpy()], axis=1)
else:
output = np.concatenate([
c0.data.numpy(),
c1.data.numpy(),
c2.data.numpy(),
c3.data.numpy(),
c4.data.numpy()], axis=1)
test_pred.append(output)
test_pred = np.vstack(test_pred)
if test_pred_tta is None:
test_pred_tta = test_pred
else:
test_pred_tta += test_pred
return test_pred_tta
开始训练啦!!
model = SVHN_Model1()
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = torch.optim.Adam(model.parameters(), 0.001) # Adam优化器,或许可以试试SGD?
best_loss = 1000.0
print('0')
'''
use_cuda = False
if use_cuda:
model = model.cuda()
'''
for epoch in range(10): # 设置训练的迭代次数
train_loss = train(train_loader, model, criterion, optimizer, epoch)
print('001')
val_loss = validate(val_loader, model, criterion)
print('1')
val_label = [''.join(map(str, x)) for x in val_loader.dataset.img_label]
val_predict_label = predict(val_loader, model, 1)
val_predict_label = np.vstack([
val_predict_label[:, :11].argmax(1),
val_predict_label[:, 11:22].argmax(1),
val_predict_label[:, 22:33].argmax(1),
val_predict_label[:, 33:44].argmax(1),
val_predict_label[:, 44:55].argmax(1),
]).T
print('2')
val_label_pred = []
for x in val_predict_label:
val_label_pred.append(''.join(map(str, x[x!=10])))
print('3')
val_char_acc = np.mean(np.array(val_label_pred) == np.array(val_label))
print('Epoch: {0}, Train loss: {1} \t Val loss: {2}'.format(epoch, train_loss, val_loss))
print('Val Acc', val_char_acc)
# 记录下验证集精度
if val_loss < best_loss:
best_loss = val_loss
# print('Find better model in Epoch {0}, saving model.'.format(epoch))
torch.save(model.state_dict(), './model.pt')
我的小mac真的太慢了!!一个epoch大概要半小时吧:)
- 预测并生成提交文件
test_path = glob.glob('input/mchar_test_a/*.png')
test_path.sort()
test_json = json.load(open('input/test.json'))
test_label = [[1]] * len(test_path)
print(len(test_path), len(test_label))
test_loader = torch.utils.data.DataLoader(
SVHNDataset(test_path, test_label,
transforms.Compose([
transforms.Resize((70, 140)),
# transforms.RandomCrop((60, 120)),
# transforms.ColorJitter(0.3, 0.3, 0.2),
# transforms.RandomRotation(5),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])),
batch_size=8,
shuffle=False,
num_workers=5,
)
这边测试集的json文件没有提供,不知道是不是是最后比赛评分的时候才能用到。自己想测试,不知道能不能做点图片测一下。
- 加载保存最优模型
model.load_state_dict(torch.load('model.pt'))
test_predict_label = predict(test_loader, model, 1)
print(test_predict_label.shape)
test_label = [''.join(map(str, x)) for x in test_loader.dataset.img_label]
test_predict_label = np.vstack([
test_predict_label[:, :11].argmax(1),
test_predict_label[:, 11:22].argmax(1),
test_predict_label[:, 22:33].argmax(1),
test_predict_label[:, 33:44].argmax(1),
test_predict_label[:, 44:55].argmax(1),
]).T
test_label_pred = []
for x in test_predict_label:
test_label_pred.append(''.join(map(str, x[x!=10])))
import pandas as pd
df_submit = pd.read_csv('../input/test_A_sample_submit.csv')
df_submit['file_code'] = test_label_pred
df_submit.to_csv('submit.csv', index=None)
这边的test_A_sample_submit.csv不知道是不是用来保存测试样本数据的,因为好像是空白的。
遇到的问题
- 安装虚拟环境时,一开始几个包一直装不进去,terminal报错,后来群里大佬指导下,用了添加了清华镜像channel,就安装上了。但是cudatoolkit还是装不上,因为我没GPU啊!感觉自己太蠢了
- 虚拟环境安装好后,启动jupyter notebook,依然无法切换到新建的虚拟环境!应该是用一个
nb-conda这个命令安装Anaconda的插件,就可以了。可能因为网的问题,我依然没装上插件,就用了自己原来的环境。
报错如下:
Collecting package metadata (current_repodata.json): failed
CondaHTTPError: HTTP 000 CONNECTION FAILED for url https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/osx-64/current_repodata.json>
Elapsed: -
An HTTP error occurred when trying to retrieve this URL.
HTTP errors are often intermittent, and a simple retry will get you on your way.
‘https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/osx-64’
Reference
[1]: ResNet: https://zhuanlan.zhihu.com/p/54289848
[2]: CRNN: https://zhuanlan.zhihu.com/p/43534801
[3]: github: https://github.com/datawhalechina/team-learning/tree/master/03%20%E8%AE%A1%E7%AE%97%E6%9C%BA%E8%A7%86%E8%A7%89/%E8%AE%A1%E7%AE%97%E6%9C%BA%E8%A7%86%E8%A7%89%E5%AE%9E%E8%B7%B5%EF%BC%88%E8%A1%97%E6%99%AF%E5%AD%97%E7%AC%A6%E7%BC%96%E7%A0%81%E8%AF%86%E5%88%AB%EF%BC%89