大数据实战:基于Spark SQL统计分析函数求分组TopN
做大数据分析时,经常遇到求分组TopN的问题,如:求每一学科成绩前5的学生;求今日头条各个领域指数Top 30%的头条号等等。Spark SQL提供了四个排名相关的统计分析函数:
dense_rank() 返回分区内每一行的排名,排名是连续的。
rank() 返回分区内每一行的排名,排名可能不连续。
percent_rank() 返回相对百分比排名。
row_number() 返回每个分区的从1开始的连续行号。
排名函数使用例子
假如有一个表Affairs,共有25行数据。数据如下表:
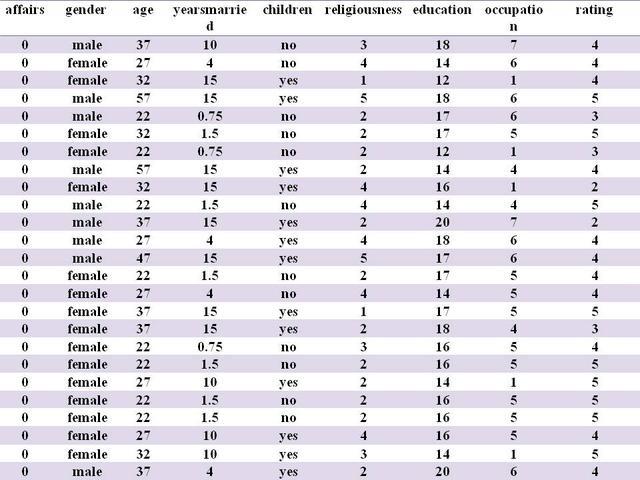
Affairs表数据
在这个表上分别使用这四个函数,通过结果可以很明显看出他们的异同。

Spark SQL 排名函数使用例子
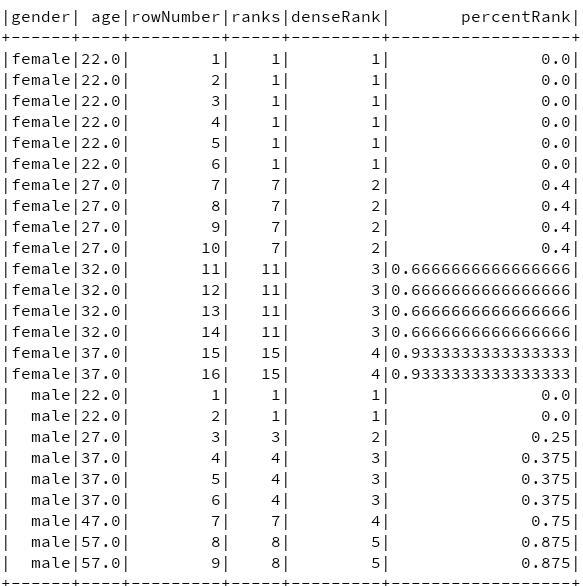
Spark SQL 排名函数执行结果
常见问题实战
1. 分别查找男女中年龄由大到小排名前3的人(排名不连续,人数可能大于3)

rank函数使用例子
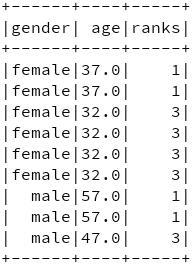
rank函数执行结果
2. 分别查找男女中年龄由大到小排名前3的人(排名连续,人数可能大于3)

dense_rank使用例子
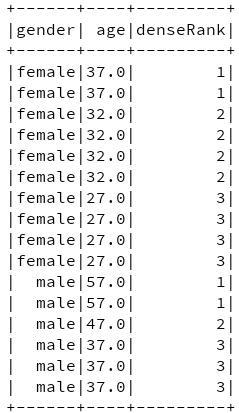
dense_rank执行结果
3. 分别查找男女中年龄最小的3个人(人数一定为3)

row_number使用例子

row_number执行结果