【译】利用uDepot获得快速NVM存储的性能
小Tao们在进行分布式全闪存文件系统的预研工作,从学术圈和工业界寻找灵感,发现这篇前沿文章,并翻译出来和大家学习分享。 “这是一篇KV存储技术方向中少见的讲述如何即高效又经济地使用快速闪存设备的文章,观点新颖,方法独特,参考和使用价值很高。” ——译者
摘要
许多应用程序需要低延迟的KV存储,为了满足这一需求,通常使用基于DRAM后端的KV存储。然而,与传统的SSD相比,最近基于新型NVM技术的存储设备提供了前所未有的性能。如果存在一个KV存储能够充分发挥这些设备本身的性能,那么将提供很多机会来加速应用程序并降低成本。然而,现有的KV存储,都是为较慢的SSD或HDD设备所构建,并不能充分利用快速NVM这类设备的性能。
本文提出了一个自底向上构建的KV存储uDepot,它可以充分发挥基于块的快速NVM设备的性能。为了避免低效,uDepot经过精心的设计,使用两级索引结构,可以根据插入存储的条目数量来动态调整其所占用的DRAM空间,并使用一种新的基于任务的IO运行时系统来最大化性能,这使得应用程序能够充分利用快速NVM设备的原始性能。作为一个嵌入式存储,就吞吐量和延迟而言,uDepot的性能几乎与快速NVM设备的原始性能相当,同时可以跨多个存储设备和核心扩展。作为一个存储Server,uDepot在YCSB基准测试下显著优于针对SSD设计的目前最先进的存储。最后,通过使用基于uDepot实现的Memcache服务,证明了基于NVM设备的数据服务,可以以更低的成本,提供与基于DRAM的数据服务相当的性能。实际上,我们使用uDepot建立了一个Memcache云服务,目前在公有云中作为一个实验性的产品提供使用。
1、引言
非易失性内存(NVM)技术的进步使得一类新的基于块的存储设备具有了前所未有的性能。这些设备被称为Fast NVMe Devices(以下简称FNDs),实现了每秒数十万IO操作(IOPS)和低延迟,并构成DRAM和传统SSD之间性能和成本折衷频谱的一个离散点。为了说明两者的不同,对比了读取4KiB数据的延迟,传统的NVMe Flash SSD的延迟是80µs,相同的操作Optane Drive[88]需要7µs,Z-SSD [48,74]需要12µs。从另一个角度看,一个常见的万兆以太网的TCP包的往返延迟是25µs-50µs,这意味着在商用数据中心使用FNDs的情况下,存储将不再成为性能瓶颈。
因此,相对于将所有数据放在内存中的数据存储[26,35,72,73,78]流行架构趋势来讲,FNDs作为一种平衡力量应运而生。具体来说,许多KV存储将所有数据存储在DRAM中[21,25,44,52,57,59,68,73],以满足应用程序的性能要求。而基于FNDs的KV存储,在成本和容量可扩展性方面为基于DRAM的系统提供了一个有吸引力的替代方案。我们期望对于传统SSD不能满足其性能要求的一些应用,现在可以使用基于FNDs的KV存储来满足其性能要求。事实上,由于在许多常见的设置中,FNDs将性能瓶颈从存储转移到了网络,所以基于FNDs的KV存储可以提供与基于DRAM的存储相当的性能。
然而,现有的KV存储不能充分发挥FNDs的潜力。首先,将所有数据放在DRAM中的KV存储,需要通过操作系统分页功能来透明地使用FNDs,这导致了很差的性能[33]。其次,将数据存放在存储设备中的KV存储[8,24,31,50],即使是那些专门针对传统SSD的存储[3,19,20,58,60,84,87,91],在设计时也考虑到了不同的需求:较慢的设备,较小的容量,以及是否不需要针对设备和核心的扩展性。正如Barroso等人[7]指出的那样,当存在耗时几微秒的IO操作时,大多数现有的系统表现不佳。
基于以上的动机,我们提出了uDepot,一个为了发挥FNDs原始性能而从头开始设计的全新KV存储。uDepot的核心部分是一个可以被应用程序作为库使用的嵌入式存储。使用这个嵌入式存储,构建了两个网络服务:一个是使用自定义的网络协议的分布式KV存储;另一个是实现了Memcache[64]协议的分布式缓存,可以作为memcached[65]的完全替代,memcached[65]是一个广泛使用的基于DRAM的缓存系统[5,70]。
在设计上,uDepot是有所侧重的:它提供了高效数据访问的流线型功能,侧重于性能优化而不是更丰富的功能(例如,范围查询)。uDepot的高效表现在几个方面:1)实现了低延迟,2)提供了每个核心的高吞吐量,3)存储性能随着设备和核心的增加而增加,4)就IO操作的数量和字节数而言,实现了较低的端到端的IO放大,最后,5)提供了一个较高的存储容量利用率。要实现以上这些目标,需要在整个系统中进行多次的优化,但其中两个方面尤其重要。首先,有效地访问FNDs。大多数现有的KV存储使用同步IO,这严重降低了性能,因为同步IO依赖于内核调度的线程来处理并发性。相反,uDepot使用异步IO,如果可能的话,直接从用户空间访问存储设备。为此,uDepot建立在TRT之上,TRT是一个使用用户空间协作调度的微秒级IO的任务运行时。其次,uDepot使用了一个高性能的DRAM索引结构,它能够匹配FNDs的性能,同时保持它的内存占用很小。(较小的内存占用会导致高效的容量利用率,因为索引相同的存储容量所需的DRAM更少。)uDepot的索引结构是可调整大小的,可以根据存储的条目数量来调整内存占用。调整索引结构大小不需要任何IO操作,并且是增量执行的,因此造成的损耗最小。
总之,本文的贡献有:
1)uDepot,一个KV存储,可以发挥FNDs的原始性能,提供低延迟,高吞吐量,良好的扩展性,以及对CPU、内存和存储设备的高效使用。
2)TRT,一个适用于微秒级IO的任务运行时系统,作为uDepot的基石。TRT为编写充分利用快速存储的应用程序提供了一个对程序员友好的框架。
3)uDepot的索引数据结构,能够满足其性能目标,同时具有较高的空间利用率,并且可以根据存储的KV条目数量来动态调整其大小。
4)一个实验评估,该评估表明uDepot与FNDs的性能是相当的,据我们所知,没有任何现有的系统可以做到这一点。实际上,uDepot的性能大大超过了针对SSD优化的存储,最高可达14.7倍,而且与基于DRAM的memcached服务的性能相当,这使得uDepot可以作为Memcache的替代品,从而大大降低了成本。使用uDepot构建的Memcache云服务已在公共云[39]中作为实验产品使用。
本文的其余部分组织如下。在第2节说明工作动机,在第3节讨论TRT,并分别在第4节和第5节提出和评估uDepot。在第6节讨论相关的工作,并在第7节进行总结。
2、背景与动机
在2010年,Ousterhout等人主张一种全内存的KV存储,他们预测“在未来5-10年内,假设DRAM技术不断进步,将有可能以低于5美元/GB的成本构建容量为1-10PB的RAM云存储”[72]。从那以后,研究人员一直在进行着一场“军备竞赛”,以最大限度地提高全内存KV存储的性能[10,21,44,52,57,68,73]。然而,与上述预测不同的是,DRAM的扩展规模正在接近物理极限[69],并且DRAM的成本也越来越高[22,40]。因此,随着容量需求的增加,内存KV存储依赖于横向扩展能力,即通过添加更多的服务器来满足所需的存储容量。自然地,这是低效的并且代价高昂,因为存储节点的其余部分(CPU、存储)仍然未得到充分利用,而且为了支持额外的节点,所需的其他资源也需要按比例增加(空间、电源供给、冷却系统)。此外,尽管内存KV存储的性能令人印象深刻,但许多这种存储都依赖于高性能或专门的网络(例如RDMA、FPGAs),无法部署在许多公共云提供商提供的普通数据中心基础设施中。

(a)当以2的幂为单位增加队列深度时,使用SPDK的perf基准工具测试两种NVMe设备(NVMe Flash SSD和Optane)的4KiB随机读取的延迟和吞吐量[86]。
(b)使用不同的IO工具(aio,spdk)和存储引擎(WiredTiger,RocksDB)测试的4KiB随机读取的总吞吐量。
图1
最近发布的快速NVMe设备(FNDs)为DRAM提供了一种经济有效的替代方案,其性能显著优于传统SSD(图1a)。具体来说,基于3D XPoint(3DXP)的Optane驱动器,可以提供一个接近0.6Mops/s的吞吐量,和7µs的读取访问延迟,这个延迟与具有80µs或更高延迟[34]的传统SSD相比,低了一个数量级。此外,三星发布了Z-SSD,这是一个利用Z-NAND[74]技术的新设备[89],和Optane设备有类似的性能特征,获得了12µs的读取访问延迟。因此,有效使用FNDs的KV存储为其DRAM对手提供了一个有吸引力的替代方案。特别是在使用商用网络的环境中(例如10 Gbit/s以太网),FNDs将系统瓶颈从存储转移到了网络,而基于DRAM的KV存储的全部性能无法通过这种网络获得。
现有的KV存储在构建时考虑了较慢的设备,从而无法提供FNDs的原始性能。作为一个令人激励的例子,考虑一个多核心多设备的系统,目标是使用20个CPU核心和24个NVMe驱动器来降低成本,并将设备的性能与两种常见的存储引擎RocksDB和WiredTiger的性能进行比较。这些引擎代表了现代KV存储设计的缩影,分别使用了LSM树和B树。我们使用Linux异步IO工具(aio)和SPDK(一个用于从用户空间直接访问设备的库)的微基准测试工具来测量设备性能。对于两个KV存储,分别加载5千万个4KiB的条目,并使用相应的微基准工具测试随机GET操作的吞吐量,同时设置适当的缓存大小,以便将请求直接下发到存储设备。一方面,即使将RocksDB和WiredTiger调到最佳状态,其性能也无法分别超过1 Mops/s和120 Kops/s。另一方面,存储设备本身可以使用异步IO获得3.89 Mops/s的性能,使用用户空间IO(SPDK)可以获得6.87 Mops/s的性能。(关于这个实验的更多细节以及uDepot如何在相同的设置中执行,可以在第5节中找到说明。)
总的来说,这些KV存储没有充分发挥设备的性能,尽管专家们可能会调整它们以提高其性能,但它们的设计存在着根本问题。首先,这些KV系统是为速度较慢的设备构建的,使用的是同步IO,而同步IO在微秒级别[7]上存在很大的问题。其次,使用了LSM树或B树,这是已知的会造成显著的IO放大。例如,在之前的实验中,RocksDB的IO放大为3倍,WiredTiger为3.5倍。再次,在DRAM中缓存数据,这需要额外的同步,但也由于内存需求而限制了可扩展性,最后,它们提供了许多额外的特性(例如事务),这可能会对性能造成影响。
uDepot遵循了不同的设计思路:它是自底向上构建的,为了发挥FNDs的原始性能(例如,通过消除IO放大),只提供KV存储的基本操作,不缓存数据,并使用基于TRT的异步IO,接下来将对TRT进行说明。
3、TRT:用于快速IO的任务运行时系统
广义上讲,有三种IO方式访问存储:同步IO、异步IO和用户空间IO。大多数现有的应用程序通过同步系统调用(如pread、pwrite)访问存储。因为已经建立了良好的网络连接[45],同步IO并不会伸缩,因为处理并发请求需要每个线程对应一个请求,这会导致上下文切换,当等待处理的请求的数量高于CPU核心的数量时,上下文切换会降低性能。因此,就网络编程来说,要想利用快速IO设备的性能就需要利用异步IO[7]。例如,Linux AIO[43]允许从单个线程批量地发送(和接收)多个IO请求(及其完成响应)。然而,仅执行异步IO本身并不足以完全获得FNDs的性能。为了构建可高效访问快速IO设备的应用程序,产生了一套新的原则。这些原则包括从数据路径中移除内核,支持对中断进行轮询,最小化(如果不能完全排除的话)跨CPU核心的通信[9,75]。虽然上述技术设计之初主要针对快速网络,但它们也适用于存储[47,94]。与作为内核工具的Linux AIO不同,SPDK[85]等用户空间IO框架通过避免上下文切换、数据复制和调度开销来实现性能最大化。另一方面,并不总是能够使用这些方法,因为它们需要直接访问设备(在许多情况下这是不安全的),而且许多环境还不支持这些方法(例如,云虚拟机)。
因此,一个高效的KV存储(或类似的应用程序)需要异步地访问网络和存储,如果情况允许,需要尽量使用用户空间IO来最大化性能。现有框架(如libevent[55])不适合此用例,因为对于事件检查来说,它们假定应用程序只检查单个事件端点(例如,epoll_wait[46]系统调用)。在对存储和网络的组合访问时,可能存在需要检查的多个事件(和事件完成)端点。例如,可能将epoll_wait用于网络套接字,将io_getevents[42]或SPDK的完成处理调用用于存储。此外,这些框架中有许多是基于回调的,由于存在所谓的“stack ripping”问题,使得回调使用起来很麻烦[1,49]。
为了使访问FNDs既高效又对程序员友好,我们开发了TRT(Task-based Run-Time),这是一个基于任务的运行时系统,其中的任务是协作调度的(即不可抢占),每个任务都有自己的堆栈。TRT会产生许多线程(通常每个核心一个线程),并在每个线程上执行一个用户空间调度器(scheduler)。调度器在自己的堆栈中执行。在调度器和任务之间切换是轻量级的,包括保存和恢复大量寄存器,而不涉及内核。在协作调度中,任务通过执行适当的调用自动切换到调度程序。一个到调度器的这种调用示例是yield,它将执行延迟到下一个任务。还有生成任务的调用和同步调用(用于等待和通知)。同步接口基于编程语言的Futures[29,30]实现。因为TRT尽量避免跨CPU核心通信,所以它为同步原语提供了两种变体:核心内部和核心之间。核心内部原语的效率更高,因为只要临界区不包含切换到调度器的命令,就不需要同步调用来防止并发访问。
基于上述原语,TRT为异步IO提供了基础设施。在典型的场景中,每个网络连接将由不同的TRT任务提供服务。为了启用不同的IO后端和工具,每个IO后端实现一个poller任务,该任务负责轮询事件并通知其他任务来处理这些事件。为了避免跨CPU核心通信,每个核心运行自己的poller实例。因此,当任务具有挂起的IO操作时,不能跨核心移动。Poller任务与任何其他任务一样由调度器调度。
TRT目前支持四种后端:Linux AIO、SPDK(包括单设备和RAID-0多设备配置)、Epoll以及正在开发中的用于RDMA和DPDK的后端。每个后端都提供了一个低级接口,允许任务发出请求和等待结果,并在此基础上构建了一个高级接口,用于编写类似于其同步实现对应的代码。例如,trt::spdk::read()调用将向SPDK设备队列发出read命令,并调用TRT调度器暂停任务执行,直到收到处理SPDK完成的poller任务的通知为止。
为了避免同步,运行在不同核心上的所有后端的poller使用不同的端点:Linux AIO poller使用不同的IO上下文,SPDK poller使用不同的设备队列,Epoll poller使用不同的控制文件描述符。
4、uDepot
uDepot支持对可变大小的key和value执行GET、PUT和DELETE操作(第4.5节)。最大的key和value大小分别是64 KiB和4 GiB,没有最小限制。uDepot直接操作设备,并执行自己的(日志结构的)空间管理(第4.1节),而不是依赖于文件系统。为了最小化IO放大,uDepot在DRAM中使用一个两级哈希表作为一种索引结构(第4.2节),允许使用单个IO操作就能实现KV操作(如果不存在哈希冲突),但是缺乏对范围查询的高效支持。通过运行时调整索引结构的大小(resizing),以适应存储的KV条目的数量,该索引结构可以管理PB级的存储,同时仍然保持高效的内存使用。重新调整大小(第4.3节)造成的性能损耗很小,因为它是增量的,不会引起额外IO。uDepot不缓存数据,使用持久化存储(第4.4节):当PUT(或DELETE)操作返回时,数据已存储在设备中(而不是在操作系统缓存中),在发生崩溃时其数据可以被恢复。uDepot支持多种IO后端(第4.6节),允许用户根据自己的配置来获得性能最大化。uDepot目前可以以三种方式使用:作为可链接到应用程序的一种嵌入式存储,作为一种网络分布式存储(第4.7节),或者作为一个实现Memcache协议的缓存系统[64](第4.8节)。
4.1 存储设备空间管理
uDepot使用一种日志结构的方法管理设备空间[67,79],即空间按顺序分配并且通过垃圾收集器(GC)处理碎片。使用这种方法有三个原因。首先,它在NAND Flash等特殊存储上取得了良好的性能。其次,即使对于DRAM等非特殊存储[80],它也比传统的分配方法更有效。第三,uDepot的一个重要用例是缓存,在协同设计GC和缓存时存在大量的优化机会[81,84]。空间分配是通过SALSA[41]的日志结构的分配器的用户空间端口实现的。设备空间被分割成片段(segments,默认大小为1 GiB),这些片段又被分割成颗粒块(grains,通常大小等于IO设备的块大小)。有两种类型的片段:用于存储KV记录的KV片段和用于冲刷(flushing)索引结构以加速启动的索引片段(第4.4节)。uDepot调用SALSA(顺序地)分配和释放颗粒块。SALSA执行GC功能并向上调用uDepot将特定的颗粒块重新定位到空闲片段[41]。SALSA的GC[76]是基于贪婪算法[12]和环形缓冲区(circular buffer,CB)[79]算法的一般变体,该变体算法利用CB的老化因子来增强贪婪策略。

图2:uDepot在DRAM中维护的索引结构(目录和表)。FNDs空间被分割成两种类型的片段:存储内存索引表的索引片段和存储KV记录的KV片段。
4.2 索引数据结构
uDepot的索引是一个全内存的两级映射目录,用于将key映射到存储中的记录位置(如图2)。该目录被实现为一个原子指针,指向一个只读的指针数组,其中的指针指向哈希表。
哈希表。每个哈希表实现了一个改进的跳房子(hopscoth)[37]算法,其中一个条目存储在一个连续位置的范围内,该范围被称为邻域(neighborhood)。实际上,跳房子算法的工作类似于线性探测,但限定探测的距离在邻域内。如果一个条目被哈希到了哈希表数组中的索引i,并且H是邻域大小(默认为32),那么该条目可以存储在从i开始的任意H个有效条目位置。在接下来的段落中,将i称为邻域索引。本文选择跳房子算法是因为其高占用率(high occupancy)、高效的缓存访问、有界的(bounded)lookup性能(即使在高占用率的情况下)和简单的并发控制[21]。
本文对原来的算法做了两个修改。首先,使用条目数量的二次幂对哈希表进行索引,类似于组相联缓存[38]:使用从key计算而来的指纹的最低有效位(LSB)来计算邻域索引。这允许在重新调整大小期间有效地重建原始指纹,而不需要完全存储指纹或执行IO来获取key并重新计算。
其次,本文没有维护每个邻域的位图,也没有维护每个邻域的所有条目的链表,而这两者是原始算法所建议使用的[37]。后者将使默认配置的内存需求增加50%(8字节的条目,邻域大小为32,每个条目4字节)。一个链表至少需要两倍的内存(假设使用8字节指针和单链表或双链表);更不用说增加的复杂性了。本文不使用位图或链表,而是直接对条目的lookup和insert操作执行线性探测。
同步。本文使用一组锁来进行并发控制。这些锁用于保护哈希表的不同区域(lock regions),其中每个区域(默认为8192个条目)严格大于邻域的大小。根据邻域所在的区域获取锁;如果一个邻域跨越两个区域,则按顺序获取第二个锁。(最后一个邻域没有环绕到哈希表的开头,因此保持了锁的顺序。)此外,为了避免跨越两个以上锁区域的insert操作,不会对超过两个区域以外的条目进行替换。因此,一个操作最多使用两个锁,并且,假设具有良好的key分布,那么锁争用可以忽略不计。
哈希表条目。每个哈希表条目由8个字节组成:
其中pba字段包含了KV对所在存储位置的颗粒块偏移量。为了能够利用大容量设备,在这个字段使用了40比特,因此能够索引PB级的存储(例如,对于4KiB的颗粒块可索引4PiB的存储)。Value为全1的pba表示一个无效的(空闲的)条目。
使用11比特表示存储在颗粒块中的KV对的大小(kv_size)。当使用4 KiB大小的颗粒块时,对于KV对的GET操作,允许发出一个最大8MiB大小的读IO。大于该值的KV对需要二次操作。一个KV大小为0的有效条目表示一个已删除的条目。

图3:如何使用key指纹来确定一个key的邻域。目录d包含4个表,图中只显示了其中的两个(ht00和ht10)。
其余13比特按如下方式使用。内存索引对一个35比特的指纹进行操作,该指纹是key的一个64比特cityhash[14]哈希的LSBs(如图3)。将指纹分为一个索引(27比特)和一个标记(8比特)。指纹索引用于索引哈希表,允许每个表最多有227个条目(默认值)。从表的位置重构指纹需要:1)条目的邻域偏移量,2)指纹标记。在每个条目上同时存储了8比特的指纹标记(key_fp_tag)和5比特的邻域偏移量,以允许每个邻域存储32个条目(neigh_off)。因此,如果一个条目在表中的位置为λ, 则它的邻域索引为λ-neigh_off,并且它的指纹是key_fp_tag:(λ-neigh_off)。
容量利用率。有效地利用存储容量不但需要能够对其寻址(pba字段),而且需要有足够的哈希表条目。使用指纹标记的LSBs(总共8比特)来索引目录,uDepot的该索引允许有28个表,每个表有227个条目,总共有235个条目。如果以增加冲突为代价,还可以通过使用最多5个LSBs(从索引目录的指纹)来进一步增加目录大小,允许使用213个表。这样可以使用最多5个邻域位,因为现有的跳房子算法的碰撞机制最终将填充哈希表中没有邻域开始的位置。如果考虑KV对的平均大小为1 KiB,那么这将允许使用最多1 PiB(235+5·210)的存储。根据预期的工作负载和可用的容量,用户可以通过配置相应的哈希表大小参数来最大化容量利用率。
操作。对于lookup操作,会生成一个key指纹。使用指纹标记的LSBs来索引目录,并为这个key找到其所在的哈希表(如果指纹标记还不够,还可以使用前面描述的指纹LSBs)。接下来,使用指纹索引对哈希表进行索引,以找到邻域(同样参见图3)。然后在邻域中执行线性探测,并返回指纹标记(key_fp_tag)匹配的条目(如果存在的话)。
对于insert操作,哈希表和邻域的定位过程与lookup操作一样。之后对邻域执行线性探测,如果没有匹配指纹标记(key_fp_tag)的现有条目,那么insert将返回第一个空闲条目,如果存在的话。然后用户可能填充这个条目。如果不存在空闲条目,那么哈希表将执行一系列的置换操作,直到在邻域内找到一个空闲条目。如果查找空闲条目失败,则返回一个错误,此时调用者通常会触发重新调整大小操作。如果存在匹配项,那么insert将其返回。调用者决定是更新现有的条目,还是从停止的地方开始继续搜索一个空闲条目。
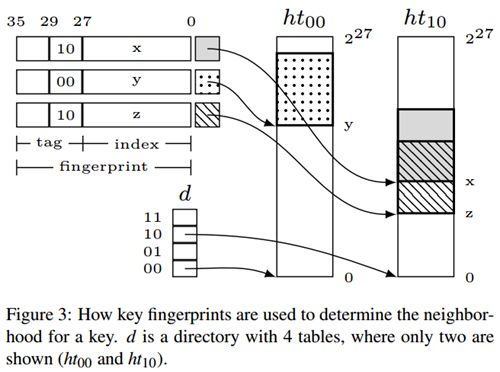
图4:从具有2个哈希表的目录(d)转换到具有4个哈希表的目录(d‘)的增量调整大小示例。在调整大小期间,插入操作将数据从ht0的锁区域(包含插入条目的邻域)复制到两个哈希表(ht00和ht10)。
4.3 调整大小操作
索引数据结构的最优大小取决于KV记录的数量。将索引数据结构的大小设置得太低会限制可以处理的记录的数量。设置得过高则可能会浪费大量内存。例如,假设KV记录平均大小为1KiB,1 PiB的数据集将需要大约8TB的内存。
uDepot通过根据工作负载动态调整索引数据结构大小来避免这个问题。重新调整大小操作速度很快,因为不需要对设备执行任何IO,并且对正常操作的干扰最小,因为是增量执行的。
目录以2的次幂扩容,因此在任意点上,索引保存n∗2m个条目,其中m是扩容(grow)操作的数量,n是每个哈希表中的条目数量。只需要指纹来确定新的位置,因此不需要IO操作来将哈希条目移动到其新位置。一种简单的方法是一次移动所有条目,但是,这会导致用户请求的严重延迟。相反,本文使用一种增量方法(如图4)。在重新调整大小阶段,新结构和旧结构都得到了维护。按照锁区域的粒度将条目从旧结构迁移到新结构。每个锁的“迁移”位表示该区域是否已经迁移。“重新调整大小”的一个原子计数器用于跟踪是否完成了总的调整大小操作,并初始化为锁的总数。
迁移是由无法找到空闲条目的插入操作触发的。第一个插入失败将触发重新调整大小操作,并设置一个新的影子(shadow)目录。随后的插入操作将它们持有的锁(一个或两个)下的所有条目迁移到新结构,设置每个锁的“迁移”位,并减少“重新调整大小”计数器(一个或两个)。在重新调整大小期间,在单独的线程中预先分配哈希表,以避免延迟。当所有条目都从旧结构迁移到新结构时(“resize”计数为零),旧结构的内存将被释放。在重新调整大小期间,根据lookup区域的“迁移”状态,lookup操作需要检查新结构或旧结构。
4.4 元数据和持久性
uDepot在三个不同的级别上维护元数据:每个设备、每个片段和每个KV记录。在设备级别,uDepot配置信息与唯一的种子以及校验和一起存储。在每个片段的头部,它的配置信息(拥有的分配器、片段几何结构等)与匹配设备元数据的时间戳和校验和一起存储。在KV记录级别(如图2),uDepot为每个KV对前面加入一个6字节的包含key大小(2字节)和value大小(4字节)的元数据,在KV对后面追加(避免不完整页问题)一个2字节的校验和,该校验和匹配片段元数据(未对数据进行计算)。设备和片段元数据分别需要128字节和64字节,它们存储在按颗粒块对齐的位置,其开销可以忽略不计。主要开销在于每个KV记录元数据,这取决于KV的平均大小;对于平均1KiB的规模,总开销为0.8%。
为了加快启动速度,会将全内存的索引表刷新到持久存储中,但不能保证它们是最新的:真正的最新持久来源是日志。刷新到存储发生在uDepot正常关闭期间,但也会定期执行用来加快恢复过程(recovery)。在初始化之后,uDepot遍历索引片段,恢复索引表,并重新构造目录。如果uDepot被正常地关闭(使用校验和和唯一会话标识符来对此检查),那么索引就是最新的。否则,uDepot从KV片段中找到的KV记录来重建索引。相同key的KV记录(新value或tombstone)使用片段版本信息来消除歧义。因为在恢复期间没有读取数据(只有key和元数据)操作,所以在崩溃后重新启动通常需要几秒钟。
4.5 KV操作
对于GET操作,会计算key的64位哈希值,并对关联的哈希表区域进行锁定。然后执行lookup(见第4.2节),这会返回零个或多个匹配的哈希条目。在lookup之后,表的区域会被解锁。如果没有找到匹配的条目,则该key不存在。否则,对于每个匹配条目,会从存储中取出相应的KV记录;或找到完整匹配的key并返回其value,或该key确实存在。
对于PUT操作,首先在非原地的(out-of-place)日志中写入KV记录。随后,使用insert(参见第4.2节)哈希表函数执行类似于GET(key哈希、锁等)的操作来确定key是否已经存在。如果key不存在,则向跳房子表插入一个新条目(如果存在空闲空间)——如果不存在空闲条目,则触发重新调整大小操作。如果一个key已经存在,将其之前条目的颗粒块失效,并使用KV记录的新位置(pba)和新记录大小原地的(in-place)更新表条目。请注意,与GET一样,在对匹配的哈希表条目执行读取IO操作时,不需要持有表区域锁。但是,与GET不同的是,如果找到了记录,PUT将重新获取锁,并重复执行lookup以检测同一key上的并发修改操作:如果检测到这样的并发修改操作存在,则第一个要更新哈希表条目的操作将获得胜出。如果PUT失败,那么将其在lookup之前写入的颗粒块失效,并返回适当的错误信息。PUT默认情况下更新现有条目,但提供一个可选参数,用户可以选择:(1)仅在key存在时执行PUT,或(2)仅在key不存在时执行PUT。
DELETE操作几乎与PUT相同,只是它写的是一个tombstone条目,而不是KV记录。Tombstone条目用于标识从日志进行恢复的已删除的条目,并在GC期间将其回收。
4.6 IO后端
默认情况下,uDepot绕过页面缓存直接(O_DIRECT)访问存储。这样可以防止不受控制的内存消耗,同时避免了由于从多核并发访问页面缓存而导致的可扩展性问题[96]。uDepot支持通过同步IO和异步IO访问存储。同步IO是由uDepot的Linux后端实现的(这样称呼是因为程序调度留给了Linux)。尽管该Linux后端性能很差,但它允许uDepot被现有的应用程序直接使用而无需做出修改。例如,我们实现了一个使用Linux后端的uDepot JNI接口。该实现很简单,因为大多数操作直接被转换为系统调用。对于异步IO和用户空间IO,uDepot使用了TRT,从而可以利用SPDK或内核LinuxAIO工具。
4.7 uDepot Server
嵌入式uDepot为用户提供了两个接口:一个接口可以操作使用任意的(连续的)用户缓冲区,另一个接口可以使用一个数据结构,用来保存从uDepot分配的缓冲区的链表。前一种接口在内部通过使用后一种接口实现,它更简单,但本质上效率低。对于许多IO后端存在的一个问题是,需要在IO缓冲区和用户提供的缓冲区之间进行数据复制。例如,执行直接IO需要对齐的缓冲区,而SPDK需要通过其运行时系统分配缓冲区。本文的服务端使用第二个接口,因此它可以直接从接收(发送)缓冲区执行IO。服务端使用TRT实现,并使用epoll后端进行联网。首先,产生一个用于接收新的网络连接的任务(译者注:简称任务A)。任务A向poller注册,并在有新的连接请求时得到通知。当有新的连接请求时,任务A将检查是否应该接收新的连接请求并在(随机选择的)TRT线程上生成新任务(译者注:简称任务B)。任务B将向本地的poller注册,以便在其连接上有传入数据时得到通知。任务B通过向存储后端(Linux AIO或SPDK)发出IO操作来处理传入的请求。发出IO请求后,任务B延迟其自身的执行,并且调度器将运行另一个任务。存储poller负责在IO完成(completion)可用时唤醒延迟执行的任务B。然后被唤醒的任务B将发送正确的应答并等待新的请求到来。
4.8 Memcache Server
uDepot还实现了Memcache协议[64],该协议广泛用于加速从较慢的数据存储(如数据库)中检索对象。Memcache的标准实现是使用DRAM[65],但是使用SSD的实现也存在[27,61]。
uDepot的Memcache实现类似于uDepot Server(第4.7节):它避免了数据复制,使用epoll后端进行联网,使用AIO或SPDK后端访问存储。Memcache相关的KV元数据(例如,过期时间、标志等)被附加在value的末尾。过期以一种惰性(lazy)的方式实现:在执行lookup时检查是否过期(对于Memcache的GET或STORE命令)。
uDepot的Memcache利用了缓存回收和空间管理GC设计空间的协同效应:实现了一个合并的缓存回收和GC过程,在IO放大方面将GC清理的开销降低到零。具体来说,在片段级别使用了基于LRU策略的GC(第4.1节):在缓存命中时,包含KV的片段被更新为最近访问的片段;当运行期间的空闲片段不足时,选择最近最少使用的片段进行清理,并将该片段在uDepot目录中的有效KV条目(过期的和未过期的)失效,此时这个片段可以自由地被重新填充,而不需要执行任何重定位IO。即使存在持续的随机更新操作情况下,该方案也可以保持稳定的性能,同时也降低了在空间管理级别(SALSA)上的过度配置程度到最低限度(提供足够的备用片段支持write-streams),从而在空间管理级别上最大化容量利用率。该方案的一个缺点是潜在地降低了缓存命中率[81,93];本文认为这是一个很好的折衷,因为缓存命中率会通过更大的缓存容量(由于减少了过度配置)来平摊。uDepot的Memcache Server是目前在公共云[39]中一个实验性的memcache云服务的基础。
4.9 实现说明
uDepot采用C++11实现。值得注意的是,uDepot的性能需要许多优化:使用本地CPU核心的slab分配器从数据路径消除堆分配,使用大内存页面(huge pages),与动态多态相比更倾向于静态,避免使用scatter-gather型IO带来的数据复制,在IO缓冲区的适当位置存放网络数据,使用批处理等等。
5、评估
本文在一台具有2个10核的Xeon CPU(配置为以最大频率2.2GHz运行)、125 GiB的 RAM和运行Linux 4.14内核的机器上进行实验(包括对KPTI[16]的支持——这是对增加了上下文切换开销的CPU安全问题的一个缓解)。该机器配置了26个NVMe驱动器:2个Intel Optanes(P4800X 375GB HHHL PCIe)和24个Intel Flash SSD(P3600 400GB 2.5in PCIe)。

(a)5千万条目的吞吐量(无扩容)(b)10亿条目的吞吐量(4次扩容)(c)操作延迟
图5 映射结构的性能结果
5.1 索引结构
首先评估索引结构分别在有和没有重新调整大小操作时的性能。使用512 MiB(226个条目)的哈希表,每个表有8192个锁。实验包括预先插入一些随机key,然后对这些key执行随机lookup。考虑两种情况:1)插入5千万(5·107)个条目,其中没有发生重新调整大小操作;2)插入10亿(109)个条目,其中发生了4次扩容操作。本实验对比了libcuckoo[53,54],这是一种目前最先进的哈希表实现,通过运行它附带的基准测试工具(universal_benchmark),为5千万和10亿条目测试分别配置了226和230的初始容量。结果如图5所示。对于5千万条目,本文的实现取得了每秒8770万次的lookup和每秒6400万次的insert,分别比libcuckoo的性能快5.8倍和6.9倍。对于10亿条目,由于存在重新调整大小操作,insert速率下降到了23.3Mops/s。为了更好地理解重新调整大小的开销,执行了另一次测试,在其中对延迟时间进行了采样。图5c显示了由此产生的中值延迟和尾部延迟。需要复制条目的insert操作的延迟出现在99.99%的百分位数中,延迟为1.17 ms。注意,这是一种更糟糕的情况,只执行insert而不执行lookup。可以通过增加锁的数量来降低这些慢速insert操作的延迟,但是以增加内存使用为代价。
5.2 嵌入式uDepot
接下来,将研究uDepot作为嵌入式存储的性能。我们的目标是评估uDepot利用FNDs的能力,并比较三种不同IO后端的性能:使用线程的同步IO(Linux-directIO)、使用Linux异步IO的TRT(trt-aio)和使用SPDK的TRT(trt-spdk)。本文对两个特性感兴趣:效率和可扩展性。首先,应用程序被限制使用一个核心和一个驱动器(第5.2.1节)。其次,应用程序使用24个驱动器和20个核心(第5.2.2节)。
本文使用了一个自定义的微基准工具来为uDepot生成负载。对微基准工具进行了标注,以对操作的执行时间进行采样,并使用这些执行时间来计算平均延迟。在接下来的实验中,使用8-32字节之间随机大小的key和4KiB大小的value。执行5千万次随机PUT,并对已插入的key执行5千万次随机GET。
5.2.1 效率(1个驱动器,1个核心)
本节使用一个核心和一个Optane驱动器来评估uDepot及其IO后端的效率。将uDepot的性能与设备的原始性能进行了比较。
将所有线程绑定在一个核心上(该核心与驱动器在同一个NUMA节点上)。对5.2节中描述的工作负载分别使用长度为1、2、4、…、128的队列深度(qd)和三个不同的IO后端。对于同步IO(Linux-directIO),产生的线程数量等于qd。对于TRT后端,产生一个线程和等于qd的任务数量。Linux-directIO和trt-aio都使用直接IO来绕过页面缓存。

(a)PUT操作(b)GET操作
图6:运行在单个核心和单个存储设备的uDepot。在不同IO后端和不同队列深度下,在4KB的均匀随机工作负载的中值延迟和吞吐量。
GET的结果如图6b所示,PUT的结果如图6a所示。Linux-directIO后端表现最差。在很大程度上,这是因为它为每个正在运行的请求使用一个线程,导致操作系统频繁地切换上下文,以允许所有这些线程在单个核心上运行。Trt-aio后端通过使用TRT的任务来执行异步IO和对多个操作执行单个系统调用来改进性能。最后,trt-spdk后端显示了(正如预期的)最佳性能,因为避免了到内核的切换。
(a)队列深度为1的中值延迟(b)队列深度为128的吞吐量
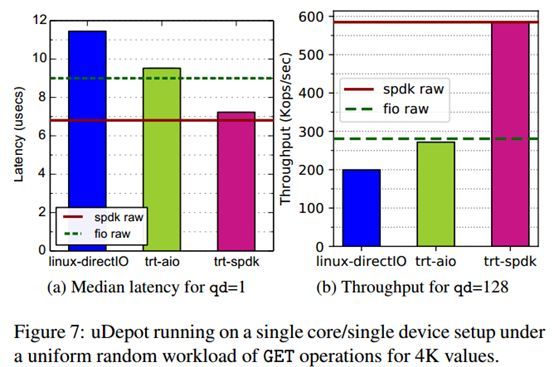
图7:运行在单个核心和单个存储设备的uDepot,在4KB的均匀随机GET操作负载下的情况。
本文考虑了在比较uDepot和设备性能过程中表现较好的GET操作。主要关注单个排队请求(qd = 1)时的延迟和较高队列深度时(qd=128)的吞吐量。图7a显示了每个后端在qd=1时的平均延迟。该图包括两行用来描述设备在类似工作负载下的原始性能,这些性能数值是使用与每个IO设施相适应的基准工具获得的。也就是说,对于一个核心和一个设备,在qd=1时对整个设备执行4KiB大小的随机读操作,设备上的数据是随机写入的(预先设定好的)。fio raw线显示了使用libaio(即Linux AIO)后端的fio[23]获得的延迟,而对于spdk raw线,则是使用了SPDK的perf实用程序[86]获得的性能。使用trt-spdk的uDepot取得了7.2µs的延迟,这非常接近直接使用SPDK取得的原始设备的延迟(6.8µs)。使用trt-aio后端获得的延迟是9.5µs,与相之应的使用fio的原始设备延迟是9µs。一个trt-aio后端的初始实现使用了io getevents()系统调用来接收IO完成,这导致了更高的延迟(接近12µs)。通过在用户空间中实现这个功能后提高了性能[17,28,77]。当使用这种技术时(fio的userspace_reap选项),fio的延迟保持不变。图7b显示了在较高队列深度(128)时每个后端取得的吞吐量。Linux-directIO达到了200kops/s,trt-aio是272kops/s,trt-spdk是585kops/s。和前面一样,fio raw线和spdk raw线分别显示了在类似工作负载(4KiB随机读取,qd=128)下的设备性能,分别通过fio和spdk的perf程序报告而来。总之,uDepot的性能与设备原始性能非常接近。
5.2.2 可扩展性(24个驱动器,20个核心)
接下来,将研究uDepot在使用多个驱动器和多个核心时的可扩展性,以及不同IO后端在这些情况下的表现。
为了最大化聚合吞吐量,在系统中使用了24个基于Flash的NVMe驱动器,以及所有的20个核心。(尽管这些驱动器不是FNDs,但使用了大量的驱动器来实现高聚合吞吐量,并检查uDepot的可扩展性。)对于在块设备(Linux-directIO和trt-aio)上操作的uDepot IO后端,本文创建了一个软件RAID-0设备,使用Linux md驱动程序将24个驱动器组合成一个驱动器。对于trt-spdk后端,使用了基于RAID-0的uDepot的SPDK后端。本文使用了5.2节中描述的工作负载,并对不同数量的并发请求进行测量。对于Linux-directIO,每个请求使用一个线程,最多1024个线程。对于TRT后端,GET请求的每个线程使用128个TRT任务,PUT请求使用32个TRT任务(之所以为不同的操作使用不同的任务数量,是因为它们在不同的队列深度处达到饱和)。我们将线程的数量从1增加到20。

(a)GET操作(b)PUT操作
图8:使用24个NVMe驱动器用于不同的并发度时,uDepot后端的GET/PUT总吞吐量。
结果如图8所示。其中还包括两行用来描述最大聚合吞吐量的性能统计,这是使用SPDK 的perf和基于libaio(LinuxAIO)后端的fio在相同驱动器上取得的性能数值。我们关注GET,因为这是最具挑战性的工作负载。Linux-directIO后端最初的吞吐量更好,因为它使用了更多的核心。例如,对于256个并发,它使用256个线程,然后使用机器的所有核心;对于TRT后端,相同的并发性使用2个线程(每个线程128个任务),然后使用机器的所有20个核心中的2个。然而,它的性能上限是1.66Mops/s。使用trt-aio后端的最大吞吐量为3.78 Mops/s,非常接近fio的性能3.89Mops/s。最后,使用trt-spdk的性能达到了6.17 Mops/s,约为原始SPDK性能的90%(6.87Mops/s)。由于服务器上的PCIe插槽有限,我们使用了普通SSD来达到比使用Optane驱动器更大的吞吐量。因为测量了吞吐量,所以这些结果可以推广到FNDs,不同之处在于FNDs实现相同的吞吐量需要更少的驱动器。此外,测量的原始SPDK性能(6.87 Mops/s)接近服务器的IO子系统能够交付的最大吞吐量6.91 Mops/s。后者是SPDK基准测试在使用未初始化的驱动器时获得的吞吐量,这些驱动器在不访问Flash的情况下返回0。服务器的PCIe带宽是30.8 GB/s(或者说对于4KiB块大小的吞吐量为7.7 Mops/s),如果考虑到PCIe和其他开销,这与本文的结果是一致的。
总的来说,两个uDepot后端(trt-aio,trt-spdk)在效率和可扩展性方面都与设备能为每个不同的IO设备提供的性能非常接近。相反,使用阻塞的系统调用(Linux-directIO)和多线程,在吞吐量和延迟方面有显著的性能限制。
5.3 uDepot Server/YCSB
在本节中,将评估uDepot Server性能和两个NoSQL存储性能的对比:Aerospike[2]和ScyllaDB[82]。尽管uDepot(在设计上)的功能比这些系统少,但选择这两个系统是因为它们是基于NVMe优化的,并且据我们所知,这是目前可以利用FNDs性能的最好的选择。
为了便于进行公平的比较,使用了YCSB[15]基准工具,并运行以下工作负载:A(update heavy:50/50)、B(read most:95/5)、C(read only)、D(read latest)和F(read-modify-write),使用了1千万条记录,默认记录大小为1KiB。(排除了workload E,因为uDepot不支持范围查询。)将所有系统配置为使用两个Optane驱动器和10个核心(这足够驱动两个Optane驱动器),并使用通过10Gbit/s以太网连接的单个客户端机器生成负载。对于uDepot,我们开发了一个YCSB驱动程序,使用uDepot的JNI接口作为客户端。由于TRT与JVM不兼容,客户端使用uDepot的Linux后端。对于Aerospike和ScyllaDB,使用它们可用的YCSB驱动程序。本文使用了YCSB版本0.14、Scylla版本2.0.2和Aerospike版本3.15.1.4。对于Scylla,将cassandracql驱动程序的核心和maxconnections参数至少设置为YCSB的客户端线程数量,并将其内存使用限制为64GiB,以减少由于内存分配而导致的YCSB在客户端高线程数上运行失败的情况。

图9:为不同的KV存储使用256个YCSB客户端线程时的总体吞吐量。
图9给出了所有工作负载下的256个客户机线程的吞吐量。uDepot使用trt-spdk后端提高了YCSB的吞吐量,相比Aerospike分别提高1.95倍(工作负载D)和2.1倍(工作负载A),相比ScyllaDB分别提高10.2倍(工作负载A)和14.7倍(工作负载B)。图10关注的是繁重的更新工作负载A(50/50),描述了所有被测试的存储在不同数量的客户端线程(最多256个)下的总吞吐量、更新和读取延迟报告。对于256个客户端线程,使用SPDK的uDepot的读/写延迟达到345µs/467µs,Aerospike为882µs/855µs,ScyllaDB为4940µs/3777µs。

图10:使用YCSB基准测试的不同的KV存储,在工作负载A(读写各占50%)和不同数量的客户端线程情况下的总体吞吐量、更新和读取延迟。
我们分析了在工作负载A下的执行情况,以了解Aerospike、ScyllaDB和uDepot之间性能差异的原因。Aerospike的限制在于它使用了多个IO线程和同步IO。实际上,由于多线程造成的争用,同步函数占用了大量的执行时间。ScyllaDB使用异步IO(通常有一个高效的IO子系统),但是它有显著的IO放大。分别测量了读取用户数据(YCSB的key和value)与从FNDs读取数据的读取IO放大倍数,结果如下:ScyllaDB为8.5倍,Aerospike为2.4倍,uDepot(TRT-aio)为1.5倍。
总的来说,uDepot对于FNDs性能的发挥明显优于Aerospike和ScyllaDB。我们注意到YCSB的效率很低,因为它使用同步IO来同步Java线程,因而并没有充分体现uDepot的性能。在下一节中,将使用一个性能更好的基准测试工具来更好地说明uDepot的高效。
5.4 uDepot Memcache
最后,本节评估了uDepot的Memcache实现的性能,并研究它是否能够提供与基于DRAM的服务相当的性能。
本文使用了memcached[65](版本1.5.4),这是使用DRAM的Memcache的标准实现,作为使用Memcache的应用程序的期望标准。MemC3[25](commit:84475d1)是最先进的一个Memcache实现。Fatcache[27](commit:512caf3)是SSD上的一个Memcache实现。
6、相关工作
Flash KV存储。两个早期的特别针对Flash的KV存储是:一个是FAWN[3],这是一个分布式的KV存储,使用了低功耗的CPU和少量的Flash构建;另一个是FlashStore[19],使用了DRAM、Flash和磁盘的多层KV存储。这些系统与uDepot类似,它们在DRAM中以哈希表的形式保存索引,并使用一种日志结构的方法。它们都使用6字节的条目:其中4字节用于对Flash寻址,2字节用于key指纹,而这些工作的后续演化[20,56]进一步减少了条目大小。uDepot将条目增加到8个字节,并启用了上述系统不支持的特性:1)uDepot存储KV条目的大小,允许它通过单个读请求同时获得key和value。也就是说,一次GET操作只需单次访问存储。2)uDepot支持在线重新调整大小,而不需要访问NVM存储。3)uDepot使用40比特而不是32比特对存储进行寻址,最多支持1PB的颗粒块。此外,uDepot可以有效地访问FNDs(通过异步IO后端),并且可以扩展到多个设备和多个核心上,而其他系统则是为速度较慢的设备构建的,不支持这些特性。有一些构建Flash KV存储或高速缓存[81,84]的工作[60,91]依赖于非标准的存储设备(如open-channel固态硬盘)。uDepot不依赖于特殊的设备,使用更丰富的存储接口来改进uDepot是未来的工作。
高性能DRAM KV存储。大量工作的目标是最大化基于DRAM的KV存储的性能,这些KV存储可以使用RDMA[21,44,68,73]、直接访问网络硬件[57]或FPGAs[10,52]。另一方面,uDepot通过TCP/IP进行操作,并将数据存储在存储设备中。然而,许多这种系统使用一个哈希表来维护它们的映射,并在可能的情况下从客户端通过单方面的RDMA操作来访问它。例如,FaRM[21]识别了cuckoo哈希的问题,并且与uDepot类似,使用了“跳房子”哈希的一种变体。FaRM和uDepot的一个基本区别是前者关心最小化对哈希表访问的RDMA操作,而uDepot不关心这一点。此外,uDepot的索引结构支持在线重新调整大小,而FaRM为每个桶(bucket)使用一个溢出链(overflow chain),这可能会因为检查该溢出链而导致性能下降。
NVM KV存储。最近的一些工作[4,71,92,95]提出了NVM KV存储。这些系统的根本不同之处在于,它们操作位于内存总线上的可字节寻址的NVM。相反,uDepot在存储设备上使用NVM,因为该技术广泛可用而且更经济。MyNVM[22]还使用NVM存储来减少RocksDB的内存占用,其中的NVM存储被引入做为二级块缓存。uDepot采取了一种不同的方法,它构建了一个KV存储,将数据完全放在NVM上。Aerospike[87]针对NVMe SSD,采用了与uDepot类似的设计,将其索引保存在DRAM中,数据保存在存储的日志中。然而,由于它的设计考虑了普通SSD,因此不能充分发挥FNDs的性能(例如,它使用同步IO)。与uDepot类似,Faster[11]是一个最新的KV存储,它维护一个可调整大小的内存哈希索引,并将其数据存储到一个日志中。与uDepot相比,Faster使用的是同时驻留在DRAM和存储器中的混合日志。
Memcache。Memcache是一个被广泛使用的服务[5,6,32,65,70]。MemC3[25]使用一个并发的cuckoo哈希表重新设计了memcached。与原始的memcached类似,不能动态地重新调整哈希表的大小,必须在服务启动时定义使用的内存量。uDepot支持哈希表的在线重新调整大小,同时也允许在服务重新启动时加快预热时间,因为数据存储在持久存储中。最近,在memcached中使用FNDs被尝试用来降低成本和扩展缓存[66]。
基于任务的异步IO。关于使用线程和事件来编写异步IO的争论由来已久[1,18,49,51,90]。uDepot建立在TRT上,使用基于任务的方法,每个任务都有自己的堆栈。对TRT的一个有用的扩展是为异步IO[36]提供一个可组合的接口。Flashgraph[97]使用异步的基于任务的IO系统来处理存储在Flash上的图形。Seastar[83]是ScyllaDB使用的运行时,它遵循与TRT相同的设计原则,但是(目前)不支持SPDK。
7、结论与未来工作
本文提出了uDepot,这是一个KV存储,充分利用了像Intel Optane这样的快速NVM存储设备的性能。实验证明了uDepot获得了它所使用的底层IO设备的可用性能,并且与现有系统相比可以更好地利用这些新设备。此外,本文还展示了uDepot可以使用这些设备来实现一个缓存服务,该服务的性能与基于DRAM实现的缓存类似,但成本要低得多。实际上,已经使用uDepot的Memcache实现作为一个实验性公有云服务[39]的基础。
uDepot有两个主要的限制,计划在未来的工作中加以解决。首先,uDepot并不(高效地)支持一些已经被证明对应用程序有用的一些操作,比如范围查询、事务、检查点、数据结构抽象等[78]。其次,有很多机会可以通过支持多租户[13]来提高效率,而uDepot目前并没有利用到这些机会。
8、致谢
感谢匿名审稿人,特别是我们的指导老师Peter Macko,感谢他们宝贵的反馈和建议,也感谢Radu Stoica对论文的初稿提供的反馈。最后,要感谢Intel让我们可以提前体验Optane测试平台。
原文地址
https://www.usenix.org/system/files/fast19-kourtis.pdf
(TaoCloud团队原创翻译)