PG数据库内核分析学习笔记_XLOG日志恢复策略
PG数据库内核分析学习笔记_XLOG日志恢复策略
在PostgreSQL中,系统在崩溃后重新启动时会调用StartupXlog入口函数.
// xlog.c
/*
* This must be called ONCE during postmaster or standalone-backend startup
*/
void
StartupXLOG(void)
{
XLogCtlInsert *Insert;
CheckPoint checkPoint;
bool wasShutdown;
bool reachedStopPoint = false;
bool haveBackupLabel = false;
bool haveTblspcMap = false;
XLogRecPtr RecPtr,
checkPointLoc,
EndOfLog;
TimeLineID EndOfLogTLI;
TimeLineID PrevTimeLineID;
XLogRecord *record;
TransactionId oldestActiveXID;
bool backupEndRequired = false;
bool backupFromStandby = false;
DBState dbstate_at_startup;
XLogReaderState *xlogreader;
XLogPageReadPrivate private;
bool fast_promoted = false;
struct stat st;
该函数首先会扫描全 局信息控制文件(global/pg_control)读取系统的控制信息.
/*
* Read control file and check XLOG status looks valid.
*
* Note: in most control paths, *ControlFile is already valid and we need
* not do ReadControlFile() here, but might as well do it to be sure.
*/
ReadControlFile();
然后扫描XLOG 0志目录的结构检测其 是否完整.
/*
* Verify that pg_wal and pg_wal/archive_status exist. In cases where
* someone has performed a copy for PITR, these directories may have been
* excluded and need to be re-created.
*/
ValidateXLOGDirectoryStructure();
进而读取到最新的日志检査点记录.
/*
* When a backup_label file is present, we want to roll forward from
* the checkpoint it identifies, rather than using pg_control.
*/
record = ReadCheckpointRecord(xlogreader, checkPointLoc, 0, true);
if (record != NULL)
接下来根据日志记录序列的偏序关系检测到系统是 否处于非正常状态下,若系统处于非正常状态,则触发恢复机制进行恢复。恢复完成后重新建立检 査点并初始化XlogCtl控制信息,然后启动事务提交日志以及相关辅助日志模块。
日志中岀现以下三种情况需要进行恢复操作
1) 日志文件中扫描到backup_label文件。
if (read_backup_label(&checkPointLoc, &backupEndRequired,
&backupFromStandby))
....
/*
* When a backup_label file is present, we want to roll forward from
* the checkpoint it identifies, rather than using pg_control.
*/
record = ReadCheckpointRecord(xlogreader, checkPointLoc, 0, true);
if (record != NULL)
2) 根据ControlFile记录的最新检査点读取不到日志记录。
3) 根据ControlFile记录的检査点与通过该记录找到的检査点日志中的Redo位置不一致。
在PostgreSQL系统中,日志建立的策略是采用改进的非静止检查点的Redo日志,恢复则是找 到最近的合法检査点然后做Redo操作。
恢复操作的具体步骤如下:
1) 首先更新控制信息到ControlFile中。
2) 初始化日志恢复时所用的资源管理器。
3) 从检査点日志记录的REDO位置开始往后读取日志记录。
4) 根据日志记录的资源管理器号选择对应的RMGR,然后利用该RMGR做日志记录中所记录 的操作过程(REDO操作)。
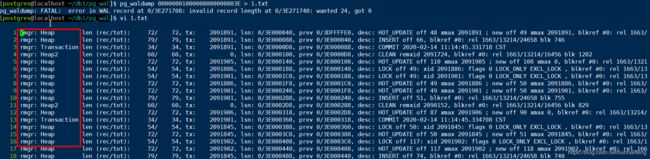
. 5)重复步骤3和4的过程,直至读取不到日志记录。
在上述恢复流程中,第4步的REDO操作会针对不同的日志类型做不同的恢复操作,下面介绍 几种典型日志的恢复操作:
1) Database类型的日志操作。这种类型日志中没有备份块,可能的操作有Create/Drop。对于 Create操作,首先强制刷新所有缓冲区,然后将日志中记录的源DB目录拷贝到新DB目录即可。对于Drop操作,直接删除该数据库对应的缓冲区即可。
2) Heap类型的Redo操作。首先根据日志序列号(LSN)以及日志记录找出是否有备份块, 如果有则恢复备份块到Page中,并置页面为“脏”。然后根据日志标志位选择对应的操作,典型的 有INSERT/DELETE/UPDATE操作。对于这几种操作,首先判断该日志记录是否有备份块,如果有 则说明已恢复,直接返回即可;如果没有则需要读取日志重建HeapTuple。
3) B-Tree类型的Redo操作。Btree是一种较复杂的索引结构,涉及的操作有叶子节点的插入 操作,以及针对不同的位置(例如根节点、叶子节点、左右子树)节点的分割操作等,所以恢复 时根据标志信息确定做哪种类型的Redo操作。
4) Xlog类型的Redo操作。因为系统崩溃是不确定的,所以对于Xlog 日志的操作也需要有日志记录。Xlog类型的日志包括记录下一个可分配的OID,设置检査点等操作。恢复的时候比较简 单,将日志记录原信息拷贝出来即可。
当恢复过程完成后,重新建立检査点并重新初始化XlogCtl结构信息。
// xlog.c
/*
* Total shared-memory state for XLOG.
*/
typedef struct XLogCtlData
{
XLogCtlInsert Insert;
/* Protected by info_lck: */
XLogwrtRqst LogwrtRqst;
XLogRecPtr RedoRecPtr; /* a recent copy of Insert->RedoRecPtr */
uint32 ckptXidEpoch; /* nextXID & epoch of latest checkpoint */
TransactionId ckptXid;
XLogRecPtr asyncXactLSN; /* LSN of newest async commit/abort */
XLogRecPtr replicationSlotMinLSN; /* oldest LSN needed by any slot */
XLogSegNo lastRemovedSegNo; /* latest removed/recycled XLOG segment */
/* Fake LSN counter, for unlogged relations. Protected by ulsn_lck. */
XLogRecPtr unloggedLSN;
slock_t ulsn_lck;
/* Time and LSN of last xlog segment switch. Protected by WALWriteLock. */
pg_time_t lastSegSwitchTime;
XLogRecPtr lastSegSwitchLSN;
/*
* Protected by info_lck and WALWriteLock (you must hold either lock to
* read it, but both to update)
*/
XLogwrtResult LogwrtResult;
/*
* Latest initialized page in the cache (last byte position + 1).
*
* To change the identity of a buffer (and InitializedUpTo), you need to
* hold WALBufMappingLock. To change the identity of a buffer that's
* still dirty, the old page needs to be written out first, and for that
* you need WALWriteLock, and you need to ensure that there are no
* in-progress insertions to the page by calling
* WaitXLogInsertionsToFinish().
*/
XLogRecPtr InitializedUpTo;
/*
* These values do not change after startup, although the pointed-to pages
* and xlblocks values certainly do. xlblock values are protected by
* WALBufMappingLock.
*/
char *pages; /* buffers for unwritten XLOG pages */
XLogRecPtr *xlblocks; /* 1st byte ptr-s + XLOG_BLCKSZ */
int XLogCacheBlck; /* highest allocated xlog buffer index */
/*
* Shared copy of ThisTimeLineID. Does not change after end-of-recovery.
* If we created a new timeline when the system was started up,
* PrevTimeLineID is the old timeline's ID that we forked off from.
* Otherwise it's equal to ThisTimeLineID.
*/
TimeLineID ThisTimeLineID;
TimeLineID PrevTimeLineID;
/*
* archiveCleanupCommand is read from recovery.conf but needs to be in
* shared memory so that the checkpointer process can access it.
*/
char archiveCleanupCommand[MAXPGPATH];
/*
* SharedRecoveryInProgress indicates if we're still in crash or archive
* recovery. Protected by info_lck.
*/
bool SharedRecoveryInProgress;
/*
* SharedHotStandbyActive indicates if we're still in crash or archive
* recovery. Protected by info_lck.
*/
bool SharedHotStandbyActive;
/*
* WalWriterSleeping indicates whether the WAL writer is currently in
* low-power mode (and hence should be nudged if an async commit occurs).
* Protected by info_lck.
*/
bool WalWriterSleeping;
/*
* recoveryWakeupLatch is used to wake up the startup process to continue
* WAL replay, if it is waiting for WAL to arrive or failover trigger file
* to appear.
*/
Latch recoveryWakeupLatch;
/*
* During recovery, we keep a copy of the latest checkpoint record here.
* lastCheckPointRecPtr points to start of checkpoint record and
* lastCheckPointEndPtr points to end+1 of checkpoint record. Used by the
* checkpointer when it wants to create a restartpoint.
*
* Protected by info_lck.
*/
XLogRecPtr lastCheckPointRecPtr;
XLogRecPtr lastCheckPointEndPtr;
CheckPoint lastCheckPoint;
/*
* lastReplayedEndRecPtr points to end+1 of the last record successfully
* replayed. When we're currently replaying a record, ie. in a redo
* function, replayEndRecPtr points to the end+1 of the record being
* replayed, otherwise it's equal to lastReplayedEndRecPtr.
*/
XLogRecPtr lastReplayedEndRecPtr;
TimeLineID lastReplayedTLI;
XLogRecPtr replayEndRecPtr;
TimeLineID replayEndTLI;
/* timestamp of last COMMIT/ABORT record replayed (or being replayed) */
TimestampTz recoveryLastXTime;
/*
* timestamp of when we started replaying the current chunk of WAL data,
* only relevant for replication or archive recovery
*/
TimestampTz currentChunkStartTime;
/* Are we requested to pause recovery? */
bool recoveryPause;
/*
* lastFpwDisableRecPtr points to the start of the last replayed
* XLOG_FPW_CHANGE record that instructs full_page_writes is disabled.
*/
XLogRecPtr lastFpwDisableRecPtr;
slock_t info_lck; /* locks shared variables shown above */
} XLogCtlData;
然后继续调用StartupCLOG函数, StartupSUBTRANS函数和StartupMultiXact函数.
// clog.c
/*
* This must be called ONCE during postmaster or standalone-backend startup,
* after StartupXLOG has initialized ShmemVariableCache->nextXid.
*/
void
StartupCLOG(void)
{
TransactionId xid = ShmemVariableCache->nextXid;
int pageno = TransactionIdToPage(xid);
LWLockAcquire(CLogControlLock, LW_EXCLUSIVE);
/*
* Initialize our idea of the latest page number.
*/
ClogCtl->shared->latest_page_number = pageno;
LWLockRelease(CLogControlLock);
}
// subtrans.c
/*
* This must be called ONCE during postmaster or standalone-backend startup,
* after StartupXLOG has initialized ShmemVariableCache->nextXid.
*
* oldestActiveXID is the oldest XID of any prepared transaction, or nextXid
* if there are none.
*/
void
StartupSUBTRANS(TransactionId oldestActiveXID)
{
int startPage;
int endPage;
/*
* Since we don't expect pg_subtrans to be valid across crashes, we
* initialize the currently-active page(s) to zeroes during startup.
* Whenever we advance into a new page, ExtendSUBTRANS will likewise zero
* the new page without regard to whatever was previously on disk.
*/
LWLockAcquire(SubtransControlLock, LW_EXCLUSIVE);
startPage = TransactionIdToPage(oldestActiveXID);
endPage = TransactionIdToPage(ShmemVariableCache->nextXid);
while (startPage != endPage)
{
(void) ZeroSUBTRANSPage(startPage);
startPage++;
/* must account for wraparound */
if (startPage > TransactionIdToPage(MaxTransactionId))
startPage = 0;
}
(void) ZeroSUBTRANSPage(startPage);
LWLockRelease(SubtransControlLock);
}
// multixact.c
/*
* This must be called ONCE during postmaster or standalone-backend startup.
*
* StartupXLOG has already established nextMXact/nextOffset by calling
* MultiXactSetNextMXact and/or MultiXactAdvanceNextMXact, and the oldestMulti
* info from pg_control and/or MultiXactAdvanceOldest, but we haven't yet
* replayed WAL.
*/
void
StartupMultiXact(void)
{
MultiXactId multi = MultiXactState->nextMXact;
MultiXactOffset offset = MultiXactState->nextOffset;
int pageno;
/*
* Initialize offset's idea of the latest page number.
*/
pageno = MultiXactIdToOffsetPage(multi);
MultiXactOffsetCtl->shared->latest_page_number = pageno;
/*
* Initialize member's idea of the latest page number.
*/
pageno = MXOffsetToMemberPage(offset);
MultiXactMemberCtl->shared->latest_page_number = pageno;
}
完成事务提交日志及其他辅助日志模块的启动。如果根据系统日志检测到系统不需要恢复操作,那么将跳过恢复操作,然后完成事务提交 日志等相关模块的初始化。