基于深度学习的肺部CT影像识别——采用U-net、3D CNN、cGAN实现肺结节的检测(三)
文章目录
- 引言
- CT-GAN图像数据增强
- 算法原理
- 网络结构
- 实现过程
- 实验结果
- 参考
引言
深度学习网络模型需要海量的数据集训练,否则无法体现深度学习应有的优势。因此医学图像数据增强是至关重要的,基于生成对抗网络充分利用数据本身来进行数据生成,从而在一定程度上解决正样本不足的问题,提升肺结节的检测精度。
CT-GAN图像数据增强
基于条件生成网络的肺结节图像生成算法CT-GAN。该网络能学习图像到图像的映射关系,通过篡改原始的CT图像数据,在指定位置添加肺结节,得到近似真实的医学图像数据,从而扩充正样本数据。
算法原理
原始GAN模型是通过随机噪声来生成数据,没有引入约束信息特征,因此生成数据的效果并不理想。本章研究基于条件生成对抗网络(cGAN) [ 1 ] \color{#0000FF}{[1] } [1]的肺结节图像生成算法CT-GAN [ 2 ] \color{#0000FF}{[2] } [2],加入了图像到图像之间的映射关系作为约束信息特征。该算法通过训练能够篡改原始的CT图像数据,在指定位置添加肺结节,得到近似真实的医学图像数据,从而扩充正样本数据。
为了注入结节,算法的预处理和后处理步骤是必要的,整个CT-GAN的处理流程如下图所示。

读取DICOM和标注文件,定位到目标结节,按照16×16×16大小处理得到掩膜(mask)。将掩膜数据输入到训练好的网络,在指定位置注入结节。然后对注入的结节进行缩放、修补等后处理操作,使其更接近真实结节。最后写入DICOM文件,得到新数据。
网络结构
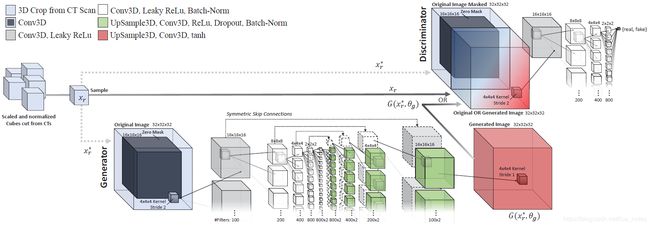
生成器部分输入原图大小为323,使用43大小、步幅为2的卷积核对图像处理,依次通过五个卷积核数量翻倍的卷积层,逐层提取特征。同时采用对称跳层连接结构,在对称结构中加入Dropout和Batch-Norm,可以保留更多的图像细节,协助反卷积层完成图像的恢复工作,并且减少梯度消失,加快模型训练。判别器部分将生成的图像或真实图像作为输入,同样使用43大小、步幅为2的卷积核进行卷积。依次通过四次卷积运算,最后得到判别器的输出概率。
实现过程
根据Mirsky 的开源项目 [ 3 ] \color{#0000FF}{[3] } [3]说明进行复现,首先打开config.py文件设置数据和模型的读写路径。由于CT-GAN不仅可以注入结节,也可以去除结节,所以需要根据提示设置成injector模式,选择前缀为1A、2A的文件进行修改、运行,根据Mirsky在GitHub上的指南操作即可,这里不再赘述。
需要注意的是在读取原始CT图像数据时,代码中有这样一条语句:
J.append([os.path.join(self.src_dir, sample.filename), coord, config['cube_shape'],
self.coordSystem])
这是在读取病例的结节信息,用LUNA16数据集时,由于原始数据是mhd和raw格式的,所以需要修改为:
J.append([os.path.join(self.src_dir, sample.seriesuid + '.mhd'), coord,
config['cube_shape'], self.coordSystem])
这里一定要是 “.mhd”,并且把对应的raw文件放到同一目录下。虽然不会报错,但是无法处理生成数据。笔者一开始是写的’.raw’,在这里卡了很久。
同样地,由于笔记本硬件条件限制,不能用到全部的数据,所以我通过pandas.read_csv()函数参数设置了忽略多少csv文件中标注的结节,以此来减少数据量。
self.coords = pd.read_csv(coords_csv_path, skipfooter=960) if coords_csv_path is not None else pd.read_csv(config['unhealthy_coords'])
# skipfooter设置忽略几个结节
此外,为了将训练过程可视化,笔者在trainer.py中补充了绘制Loss和Acc的曲线图。运行完1A、2A前缀文件代码可以得到处理好的结节样本数据文件、injector模型。
最后,通过3A文件使用训练好的模型设置注入结节坐标(image (voxel) 坐标系),或者通过GUI.py在GUI界面中注入结节,能即时观察结节注入情况,并且可以注入任意数量的结节。注入结节完成最终得到该病例的DCOM格式文件,和一个注入结节的坐标信息的CSV文件。
实验结果
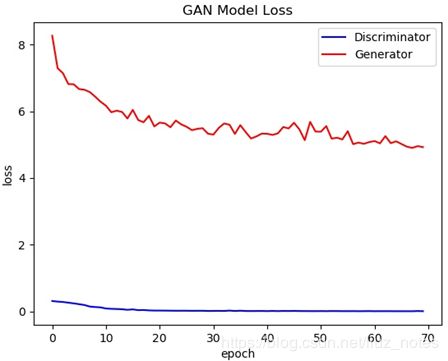



使用CT-GAN扩充训练集后,U-net分割模型和3D CNN分类模型的准确度略有提升。CT-GAN产生的新形态的结节样本增加了样本数据的多样性,在一定程度上提高了检测模型的泛化能力。模型对于尺寸较大孤立实性结节生成的效果较好,而对于尺寸较小的结节,生成的细节还有待改进。
参考
[1] Mirza M, Osindero S. Conditional Generative Adversarial Nets[EB/OL]. arXiv:1411.1784, 2014. https://arxiv.org/abs/1411.1784.
[2] Mirsky Y, Mahler T, Shelef I, et al. CT-GAN: Malicious tampering of 3D medical imagery using deep learning[C]//28th {USENIX} Security Symposium ({USENIX} Security 19). 2019:461-478.
[3] https://github.com/ymirsky/CT-GAN