【面试必读】求你们不要再问我Java中的锁及优化了?
本文90%内容整理自掘金:https://juejin.im/post/5c8a00e56fb9a049a42feb54#heading-27
一、Java线程阻塞的代价
Java的线程是映射到操作系统原生线程之上的。如果要阻塞或唤醒一个线程就需要操作系统介入,需要在户态与核心态之间切换,这种切换会消耗大量的系统资源。
因为用户态与内核态都有各自专用的内存空间,专用的寄存器等,用户态切换至内核态需要传递给许多变量、参数给内核,内核也需要保护好用户态在切换时的一些寄存器值、变量等(保护现场),以便内核态调用结束后切换回用户态继续工作。
二、Java中锁的分类
1、自旋锁
自旋锁原理非常简单,如果持有锁的线程能在很短时间内释放锁资源,那么那些等待竞争锁的线程就不需要做内核态和用户态之间的切换进入阻塞挂起状态,它们只需要等一等(自旋),等持有锁的线程释放锁后即可立即获取锁,这样就避免用户线程和内核的切换的消耗。
但是线程自旋是需要消耗cup的,说白了就是让cup在做无用功,如果一直获取不到锁,那线程也不能一直占用cup自旋做无用功,所以需要设定一个自旋等待的最大时间。
如果持有锁的线程执行的时间超过自旋等待的最大时间仍没有释放锁,就会导致其它争用锁的线程在最大等待时间内还是获取不到锁,这时争用线程会停止自旋进入阻塞状态。
适用场景: 自旋锁尽可能的减少线程的阻塞,这对于锁的竞争不激烈,且占用锁时间非常短的代码块来说性能能大幅度的提升,因为自旋的消耗会小于线程切换的消耗!
2、偏向锁
Java偏向锁(Biased Locking)是Java6引入的一项多线程优化。
偏向锁,顾名思义,它会偏向于第一个访问锁的线程,如果在运行过程中,同步锁只有一个线程访问,不存在多线程争用的情况,则线程是不需要触发同步的,这种情况下,就会给线程加一个偏向锁。
如果在运行过程中,遇到了其他线程抢占锁,则持有偏向锁的线程会被挂起,JVM会消除它身上的偏向锁,将锁恢复到标准的轻量级锁。
适用场景: 始终只有一个线程在执行同步块,在它没有执行完释放锁之前,没有其它线程去执行同步块,即在锁无竞争的情况下使用。
一旦有了竞争就升级为轻量级锁,升级为轻量级锁的时候需要撤销偏向锁,而撤销偏向锁的时候会进入安全点,安全点会导致stop the world,导致性能下降,这种情况下应当禁用(使用偏向锁导致的停顿,时间非常短暂,但是争用严重的情况下,停顿次数也会非常多)。
插入话题:
要查看安全点停顿,可以打开安全点日志,通过设置JVM参数:
- -XX:+PrintGCApplicationStoppedTime //会打出系统停止的时间
- -XX:+PrintSafepointStatistics //打印出详细信息
- -XX:PrintSafepointStatisticsCount=1
注意:安全点日志不能一直打开。安全点日志默认会输出到stdout,这导致两个问题:
- 影响stdout日志的整洁性
- stdout所重定向的文件如果不在/dev/shm,可能被锁。
对于一些很短的停顿,比如取消偏向锁,打印的消耗比停顿本身还大。安全点日志是在安全点内打印的,本身加大了安全点的停顿时间。
所以安全日志应该只在问题排查时打开。如果在生产系统上要打开,再再增加下面四个参数:
- -XX:+UnlockDiagnosticVMOptions
- -XX: -DisplayVMOutput
- -XX:+LogVMOutput
- -XX:LogFile=/dev/shm/vm.log
日志打印效果:
此日志分三部分:
第一部分是时间戳,VM Operation的类型
第二部分是线程概况,被中括号括起来
- total: 安全点里的总线程数
- initially_running: 安全点开始时正在运行状态的线程数
- wait_to_block*: 在VM Operation开始前需要等待其暂停的线程数
第三部分是到达安全点时的各个阶段以及执行操作所花的时间,其中最重要的是“vmop”
- spin: 等待线程响应safepoint号召的时间;
- block: 暂停所有线程所用的时间;
- sync: 等于 spin+block,这是从开始到进入安全点所耗的时间,可用于判断进入安全点耗时;
- cleanup: 清理所用时间;
- vmop: 真正执行VM Operation的时间。
可见,那些很多但又很短的安全点,全都是RevokeBias, 高并发的应用会禁用掉偏向锁。
3、轻量级锁
轻量级锁是由偏向锁升级来的,偏向锁运行在一个线程进入同步块的情况下,当第二个线程加入锁争用的时候,偏向锁就会升级为轻量级锁;
4、重量级锁
使用
synchronized关键字来实现,synchronized的作用相信大家都已经非常熟悉了
- 作用于方法时,锁住的是对象的实例(this);
synchronized作用于一个对象实例时,锁住的是所有以该对象为锁的代码块。
- 当作用于静态方法时,锁住的是Class实例
由于Class的相关数据存储在永久代(jdk1.8则是metaspace),而永久代是全局共享的,因此静态方法锁相当于类的一个全局锁,会锁所有调用该方法的线程;
实现图:
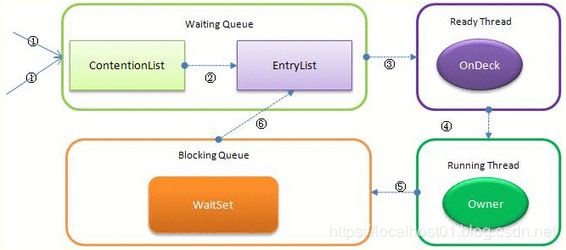
它的底层有多个队列,当多个线程一起访问某个对象监视器的时候,对象监视器会将这些线程存储在不同的容器中。
- Contention List:竞争队列,所有请求锁的线程首先被放在这个竞争队列中;
- Entry List:Contention List中那些有资格成为候选资源的线程被移动到Entry List中;
- Wait Set:哪些调用wait方法被阻塞的线程被放置在这里;
- OnDeck:任意时刻,最多只有一个线程正在竞争锁资源,该线程被成为OnDeck;
- Owner:当前已经获取到所资源的线程被称为Owner;
- !Owner:当前释放锁的线程。
JVM每次从队列的尾部取出一个数据用于锁竞争候选者(OnDeck),但是并发情况下,
ContentionList会被大量的并发线程进行CAS访问,为了降低对尾部元素的竞争,JVM会将一部分线程移动到EntryList中作为候选竞争线程。
Owner线程会在
unlock时,将ContentionList中的部分线程迁移到EntryList中,并指定EntryList中的某个线程为OnDeck线程(一般是最先进去的那个线程)。Owner线程并不直接把锁传递给OnDeck线程,而是把锁竞争的权利交给OnDeck,OnDeck需要重新竞争锁。这样虽然牺牲了一些公平性,但是能极大的提升系统的吞吐量,在JVM中,也把这种选择行为称之为“竞争切换”。
OnDeck线程获取到锁资源后会变为
Owner线程,而没有得到锁资源的仍然停留在EntryList中。如果Owner线程被wait方法阻塞,则转移到WaitSet队列中,直到某个时刻通过notify或者notifyAll唤醒,会重新进去EntryList中。
处于ContentionList、EntryList、WaitSet中的线程都处于阻塞状态,该阻塞是由操作系统来完成的(Linux内核下采用pthread_mutex_lock内核函数实现的)。
synchronized是非公平锁。 synchronized在线程进入ContentionList时,等待的线程会先
尝试自旋获取锁,如果获取不到就进入ContentionList,这明显对于已经进入队列的线程是不公平的,还有一个不公平的事情就是自旋获取锁的线程还可能直接抢占OnDeck线程的锁资源。
自旋的具体流程:
- 检测Mark Word(不知道这是啥的请自行科普)里面是不是当前线程的ID。如果是,表示当前线程处于偏向锁,即自己拥有锁,流程结束。
- 如果不是,尝试获取偏向锁。如果成功,当前线程获得偏向锁,流程结束。
- 如果失败,则说明发生锁竞争,撤销偏向锁,进而升级为轻量级锁;
- 当前线程开始竞争锁,如果成功,当前线程获得锁;
- 如果失败,表示其他线程持有锁,当前线程便尝试使用自旋来获取锁;
- 如果自旋成功则依然处于轻量级状态,并获取到锁,流程结束。
- 如果自旋失败,则升级为重量级锁,进入ContentionList。
5、总结
偏向锁是在无锁争用的情况下使用的,也就是同步块在当前线程执行过程中,没有其它线程来执行该同步块,一旦有了第二个线程的争用,偏向锁就会升级为轻量级锁,如果轻量级锁自旋到达阈值后,没有获取到锁,就会升级为重量级锁;
三、锁优化
以上介绍的锁均不是我们代码中能够控制的,但是借鉴上面的思想,我们可以优化我们自己线程的加锁操作;
1、减少锁的时间
不需要同步执行的代码,能不放在同步块里面就不放在同步块内,让锁尽快释放;
锁方法不如锁方法内的需要同步的代码块
2、减少锁的粒度
它的思想是将物理上的一个锁,拆成逻辑上的多个锁,增加并行度,从而降低锁竞争(空间来换时间)。
Java中很多数据结构都是采用这种方法提高并发操作的效率:
- JDK1.7中ConcurrentHashMap底层的分段加锁机制(Segment)
Segment继承自ReenTrantLock,所以每个Segment就是个可重入锁。所以数组中有多少个Segment就允许同一时刻多少个线程存放数据,这样增加了并发能力。- LongAdder、JDK1.8中ConcurrentHashMap
LongAdder 实现思路也类似JDK1.8中的ConcurrentHashMap,LongAdder有一个根据当前并发状况动态改变的Cell数组,Cell对象里面有一个long类型的value用来存储值;
开始没有并发争用的时候或者是cells数组正在初始化的时候,会使用cas来将值累加到成员变量的base上。在并发争用的情况下,LongAdder会初始化Cell数组,在Cell数组中选定一个Cell加锁,数组有多少个cell,就允许同时有多少线程进行修改,最后将数组中每个Cell中的value相加,在加上base的值,就是最终的值;cell数组还能根据当前线程争用情况进行扩容,初始长度为2,每次扩容会增长一倍,直到扩容到大于等于cpu数量就不再扩容,这也就是为什么LongAdder比cas和AtomicInteger效率要高的原因,后面两者都是volatile+cas实现的,他们的竞争维度是1,LongAdder的竞争维度为“Cell个数+1”为什么要+1?因为它还有一个base,如果竞争不到锁还会尝试将数值加到base上;- LinkedBlockingQueue
LinkedBlockingQueue也体现了这样的思想,在队列头入队,在队列尾出队,入队和出队使用不同的锁,相对于LinkedBlockingArray只有一个锁效率要高;
注意: 拆锁的粒度不能无限拆,最多可以将一个锁拆为当前cup数量个锁即可;
3、锁粗化
大部分情况下我们是要让锁的粒度最小化,锁的粗化则是要增大锁的粒度。
在以下场景下需要粗化锁的粒度: 假如有一个循环,循环内的操作需要加锁,我们应该把锁放到循环外面,否则每次进出循环,都进出一次临界区,效率是非常差的;
4、使用读写锁
ReentrantReadWriteLock 是一个读写锁,读操作加读锁,可以并发读,写操作使用写锁,只能单线程写。类似于数据库的共享锁和排他锁。
5、读写分离
CopyOnWriteArrayList 、CopyOnWriteArraySet等
CopyOnWrite容器 即写时复制的容器。通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。
这样做的好处是我们可以对CopyOnWrite容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器。
CopyOnWrite容器用于读多写少的并发场景,因为,读的时候没有锁,但是对其进行更改的时候是会加锁的,否则会导致多个线程同时复制出多个副本,各自修改各自的;
6、使用CAS
如果需要同步的操作执行速度非常快,并且线程竞争并不激烈,这时候使用 CAS 效率会更高,因为加锁会导致线程的上下文切换,如果上下文切换的耗时比同步操作本身更耗时,且线程对资源的竞争不激烈,使用 volatile + cas 操作会是非常高效的选择。
即使用valatile来保证可见性,利用cas来保证原子性,这里的cas并非依靠代码来compare and swap来实现。通过代码无法实现原子性,CAS操作大多都是靠CPU原语来实现,比如intel x86的cmpxchg指令就是CAS原语(compare and exchange)。
关于
volatile关键字与线程安全,可移步:https://localhost01.blog.csdn.net/article/details/78172827
7、消除缓存行的伪共享
除了我们在代码中使用的同步锁和JVM自己内置的同步锁外,还有一种隐藏的锁就是
缓存行,它也被称为性能杀手。
在多核cup的处理器中,每个cup都有自己独占的一级缓存、二级缓存,甚至还有一个共享的三级缓存。为了提高性能,cpu读写数据是以缓存行作为最小单元读写的。32位的cpu缓存行为32字节,64位cup的缓存行为64字节,但这就导致了一些问题。
例如多个不需要同步的变量因为存储在连续的32字节或64字节里面,当需要其中的一个变量时,就将它们作为一个缓存行一起加载到 某个cup-1 私有的缓存中(虽然只需要一个变量,但是cpu读取会以缓存行为最小单位,将其相邻的变量一起读入)。
被读入cpu缓存的变量相当于是对主内存变量的一个拷贝,也相当于变相的将在同一个缓存行中的几个变量加了一把锁。这个缓存行中任何一个变量一旦发生了变化,当 cup-2 需要读取这个缓存行时,就需要先将 cup-1 中被改变了的整个缓存行更新回主存(即使其它变量没有更改),然后 cup-2 才能够读取,而 cup-2 可能需要更改这个缓存行的变量与 cpu-1 已经更改的缓存行中的变量是不一样的,所以这相当于给几个毫不相关的变量加了一把同步锁。
为了防止伪共享,不同jdk版本实现方式是不一样的:
- 在jdk1.7之前:会将需要独占缓存行的变量前后添加一组long类型的变量,依靠这些无意义的数组的填充做到一个变量自己独占一个缓存行;
- 在jdk1.7:因为jvm会将这些没有用到的变量优化掉,所以采用继承一个声明了好多long变量的类的方式来实现;
- 在jdk1.8:通过添加sun.misc.Contended注解来解决这个问题,若要使该注解有效必须在jvm中添加以下参数:
-XX:-RestrictContended
sun.misc.Contended注解会在变量前面添加128字节的padding将当前变量与其他变量进行隔离。
关于什么是缓存行,jdk是如何避免缓存行的,网上有非常多的解释,在这里就不再深入讲解了。