Social GAN源代码阅读报告
目录
数据处理部分:trajectories.py及数据加载部分:loader.py
网络模型部分:models.py
数据处理部分:trajectories.py及数据加载部分:loader.py
Social GAN源码是基于pytorch框架来写的,trajectories.py是文件的数据处理部分。首先,我们需要知道pytorch的数据加载到模型的操作顺序。
- 创建一个Dataset对象,Dataset是一个代表着数据集的抽象类,所有关于数据集的类都可以定义成其子类,只需要重写__gititem__函数和__len__函数即可。
- 创建一个DataLoader对象,由于定义好的数据集不能都存放在内存中,否则内存会爆表,所以需要定义一个迭代器,每一步生成一个batch,这就是DataLoader的作用,其能够为我们自动生成一个多线程的迭代器,只要传入几个参数即可,例如batchsize的大小,数据是否打乱等。
- 循环调用DataLoader对象,将数据一批一批的加载到模型进行训练。
知道了pytorch数据加载的操作顺序,理解trajectories.py就很简单了。该文件主要对数据集进行了一定的处理,其重点在于TrajectoryDataset类的实现,该类继承至torch.utils.data中的Dataset类,其主要完成的工作就是上述操作顺序的第1步,准备数据集。其主要对原始的数据集进行预处理,原始的数据集共有4列,分为为frame id,ped id,x,y,我们要对这些数据进行处理,生成我们想要的数据。TrajectoryDataset类的__init__函数的大致思路如下:
其主要对每个序列sequence进行处理,每个sequence的长度为seq_len=obs_len+pred_len,其主要是取出完整出现在这个序列seq_len个帧中的人的数据,并且每个序列中的完整出现的人的数量必须要大于其参数min_ped,程序默认是1。举个例子,假设一个序列一共20帧,obs_len=8,pred_len=12,对于这个序列而言,完整出现在这个序列的人数为1,那么我们不需要这个人的数据,舍弃。因为完整出现在这个序列的人才一个,没有办法找到人与人之间的交互,对行人轨迹预测意义不大。而如果完整出现在个序列中的人数为3,那么这3个人的数据我们将都会保存,因为这里面可以考虑到人与人之间的交互关系。__init__函数最终得到下列数据:
self.obs_traj #shape[num_ped,2,obs_len]
self.pred_traj #shape[num_ped,2,pred_len]
self.obs_traj_rel #shape[num_ped,2,obs_len]
self.pred_traj_rel #shape[num_ped,2,pred_len]
self.loss_mask #shape[num_ped,seq_len]
self.non_linear_ped #shape[num_ped]
self.seq_start_end 其中,nun_ped为在数据集当中一共有多少满足的人,self.obs_traj即这nun_ped个人在obs_len个坐标数据。self.obs_traj_rel是每一帧相对于上一帧的位置变化。self.loss_mask源代码中似乎没有什么太大作用,self.non_linear_ped表示这个人的轨迹是否线性,其是通过调用trajectories.py文件中的poly_fit函数返回是否线性的标志位,该函数的大致意思通过对预测轨迹进行最小二乘拟合,当拟合的残差大于一定阈值,认为轨迹不线性。主要注意的是,TrajectoryDataset类中的所有pred_traj都不是预测轨迹,而是预测轨迹的真值,因为这是从数据集中读到的数据。self.seq_start_end其是一个元组列表,其长度表示一共有多少满足条件的序列。其比较不好理解,所以举个例子,假设在所给数据集中一共有5个序列满足完整出现的人数大于min_ped,且这5个序列分别有2,3,2,4,3个人完整出现,那么self.seq_start_end的长度为5,self.seq_start_end等于[(0,2),(2,5),(5,7),(7,11),(11,14)],也就是说num_ped=14,self.seq_start_end的主要作用是为了以后一个一个序列的分析的方便,即由要分析的序列,即可根据它的值得到对应在这个序列中有哪几个人以及这几个人的所有相关数据。需要注意的是,因为这是在pytorch中调用接口,所以相关数据需要转换成tensor。
另外,正如上文所说,由于TrajectoryDataset继承至Dataset类,所以其需要重写__getitem__和__len__函数,__getitem__函数的作用就是有索引得到数据集在__init__函数处后的一个数据,其返回一个列表,在本例中,就是一个序列的数据。__len__函数的作用就是得到处理后的数据的长度,在本例中,就是所有满足条件的序列的长度。
总结来说,TrajectoryDataset为我们准备好了所有的数据集,但是我们要怎么一批一批的加载数据呢?这就到了pytorch加载模型的操作顺序的第2步了,即创建DataLoader对象,DataLoader是pytorch中数据读取的重要接口类。DataLoader有很多参数:
class DataLoader(object):
def __init__(self, dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None, multiprocessing_context=None)这是DataLoader类的一些参数,这里只讲解几个,主要是在源代码中用到的几个:
- dataset:传入的数据集,在本例中,就是TrajectoryDataset准备好的数据集
- batch_size:每个batch中有多少样本
- shuffle:是否将数据打乱
- num_workers:处理数据加载的进程数
- collate_fn:将一个列表中的样本组成一个mini-batch的函数
那么我们就来看看数据加载部分loader.py源代码。
loader.py里面只定义了data_loader一个函数,该函数内部首先创建了一个TrajectoryDataset类对象dset,它就是要传入DataLoader的参数,对应于dataset。注意,我们可以修改TrajectoryDataset中的参数min_ped来控制一个序列中完整出现的人数。当你想考虑较多人之间的交互,可以改大min_ped值,该值默认为1。
data_loader函数紧接着创建了一个DataLoader类对象loader,该函对象的dataset参数即为刚刚创建的dset,的atch_size默认为64,我们可以控制shuffle为true或者false来选择让数据是否打乱。其中,对于自定义数据加载来说,最重要的是要重写collate_fn,在本例中,其在trajectories.py文件中新建了seq_collate函数,并将其赋值给collate_fn,seq_collate将batch_size的数据重新打包,将这些数据打包成我们要需要的数据格式,以便送入网络进行训练。也就是说,传入seq_collate的是batch_size个数据,每个数据对应一个序列。注意这里的数据并不是TrajectoryDataset中准备的全部数据,而是仅仅batch_size个数据,seq_collate将这batch_size数据合并打包组成一个mini-batch。这个函数内部只是对TrajectoryDataset类中准备的数据再次进行了一定的加工处理,例如将维度进行了交换,[N,2,seq_len]→[seq_len,N,2],其主要是为了和LSTM网络的输入格式保持一致。
所以说,如果我们调用一次data_loader函数,就将得到很多批batch_size大小的数据。当我们对DataLoader对象实例loader进行for循环时,每次循环将得到一批batch_size大小的数据,然后加载到模型进行训练。这也就是pytorch数据加载到模型的操作顺序中的第3步。
总结来说,通常给定的数据集与我们模型网络要求的输入格式是不一样的,这个时候我们需要自定义数据格式。我们可以创建一个类继承至Dataset,在里面将数据集准备好,同时要重写__getitem__函数与__len__函数。接下来,我们创建该类的一个对象,并将它传给DataLoader类的参数dataset。同时,我们要在重写一个函数负责将batch_size个数据打包成我们想要的网络模型的输入格式,形成一个mini-batch,以供网络进行训练。
好了,数据处理部分与数据加载部分已经讲解完毕,下面讲解一下网络模型部分,此部分需要结合论文来看。
网络模型部分:models.py
想要了解这部分内容,需要首先了解一下torch.nn.Module,在pytorch中,nn.Module是所有神经网络单元的基类。pytorch在nn.Module中实现了__call__方法,而在__call__方法中调用了forward函数。__call__方法的主要作用是是类对象具有类似函数的功能,可以在类对象中进行传参,而__call__方法中又调用了forward函数。pytorch中的nn.Module类都包含了__init__方法与__call__方法。
- __init__:类的初始化函数,类似C++中的构造函数
- __call__:使得类对象具有类似函数的功能
举个例子,假设A是一个class,a是A的一个类对象,当我们执行a=A(),这会调用__init__方法构造类的对象;而当我们执行a(),其会调用__call__方法,而在__call__方法内部又会调用forward函数,注意,这是通过类对象调用的,所以说使得类对象具有类似函数的功能。
关于nn.Module及__init__、__call__、forward可以参见下面两个网址:
https://blog.csdn.net/dss_dssssd/article/details/82977170
https://blog.csdn.net/xxboy61/article/details/88101192
好了,接下来让我们来详解网络模型部分吧!
models.py共包含2个函数以及6个类,其中SocialPooling类为作者早期研究Social LSTM中用到的池化层,在Social GAN没有用到,所以我们不需关注这个类。需要说明的是,在这些类当中,__init__主要是初始化网络结构,而forward函数则是真正有数据在里面流动进行训练或者评估。
先来看两个函数,make_mlp主要是构造多层的全连接网络,并且根据需求决定激活函数的类型,其参数dim_list是全连接网络各层维度的列表.get_noise函数主要是生成特定的噪声。
接下来我们来看encoder类部分,由其__init__方法可以看出,其网络结构主要包括一个全连接层和一个LSTM网络。研究其forward函数,首先,最原始的输入是这一批输数据所有人的观测数据中的相对位置变化坐标,即当前帧相对于上一帧每个人的坐标变化,其经过一个2*16的全连接层,全连接层的输入的shape:[obs_len*batch,2],输出:[obs_len*batch,16],然后需要经过维度变换变成3维的以符合LSTM网络中输入input的格式要求,LSTM的输入input的shape为[seq_len,batch,input_size],然后再把h_0和c_0输入LSTM,输出隐藏状态h_t记为final_h。其中,LSTM网络需要设置一些参数,如input_size:输入数据的特征数量;hidden_size:隐藏状态的特征数;num_layers:循环网络有几层LSTM以及其他一些参数。以下为LSTM的参数设置以及输入输出的格式,其中num_directions在程序中是1,其表示LSTM是双向的还是单向的,1表示单向,2表示双向。
LSTM的参数共有7个,这里只讲前面3个,也是必须要设置的3个参数,后面四个参数是可选的。
Parameters:
input_size:输入数据的特征数量,即输入数据的维度
hidden_size:隐藏状态h的特征数量
num_layers:循环网络中LSTM的层数
Inputs:input,(h_0,c_0)
input:shape[seq_len,batch,input_size] 包含输入序列特征的张量
h_0:shape[num_layers*num_directions,batch,hidden_size] 包含batch中每个元素初始隐藏状态的张量
c_0:shape[num_layers*num_directions,batch,hidden_size] 包含batch中每个元素初始细胞状态的张量
Outputs:output,(h_n,c_n)
output:shape[seq_len,batch,num_directions*hidden_size] 输出最后一层seq_len个时刻,每个时刻隐藏状态的集合,即h_1,h_2,...,h_n
h_n:shape[num_layers*num_directions,batch,hidden_size] 包含t=seq_len这个时候batch中每个元素隐藏状态的张量
c_n:shape[num_layers*num_directions,batch,hidden_size] 包含t=seq_len这个时候batch中每个元素细胞状态的张量需要特别注意的是,也是我一开始对LSTM一直比较困惑的地方。单层LSTM并不是说里面只有一个cell,而是这一单层LSTM中包括了seq_len个cell,每个cell按顺序分别输出隐藏状态h和细胞状态c。就是说如下图,该图并不是说LSTM有5层,该图LSTM只有一层。但是它的seq_len有5个,所以有5个cell,每个cell对应输出隐藏状态h和细胞状态c。
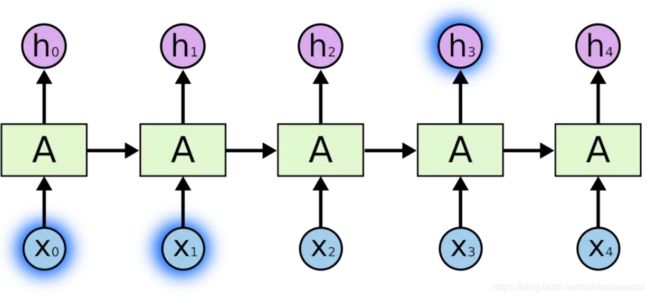 LSTM
LSTM
encoder部分的结构抽象图如下图所示。图中的batch表示这一批数据中所有的人的数量。也就是说其主要干了两件事,首先将原始数据2维的坐标变化数据提升至16维,再送入LSTM网络产生final_h,以供后续使用。另外,源代码中有一个地方与论文中描述的不太一样,论文中在2*16的全连接层之后接了Relu激活函数,但是在源代码中并没有体现。
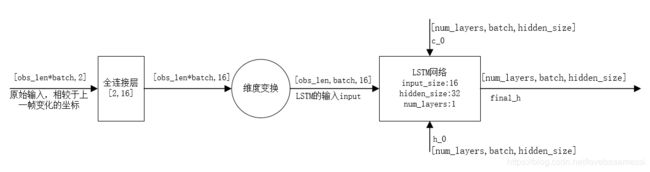 encoder网络结构抽象图
encoder网络结构抽象图
接下来来看池化层,即PoolHiddenNet类,其__init__方法中分别定义了2*16以及48*512*8两个全连接层,注意48*512*8这个全连接层带relu激活函数。我们主要看forward函数,forward函数的第一个参数h_states就是上面encoder的输出final_h,其维度为[num_layers,batch,hidden_size],在程序中即[1,batch,32],batch即batch_size个sequence序列中的总人数,每一批数据其个数一般是不相等的。forward函数内部对DataLoader加载的batch_size个sequence序列逐次处理。在对每一个序列进行处理时,对每一个序列处理的示意图如下图所示。
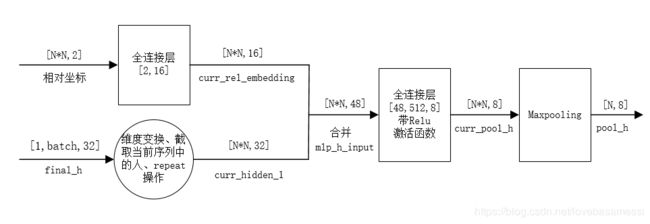 Pooling Module网络结构抽象图
Pooling Module网络结构抽象图
上图是Pooling Module每个序列的处理示意图.在forward函数中,其计算人的相对位置比较巧妙,其主要通过两次repeat操作将一个序列中的N个人的位置信息重复N次,这两次repeat是不同的repeat,假设一个序列中一共3个人,则第一次repeat得到[P1,P2,P3,P1,P2,P3,P1,P2,P3],第二次repeat得到[P1,P1,P1,P2,P2,P2,P3,P3,P3],两个矩阵相减即可得到N*N行的矩阵,每一行代表相对坐标。以3人为例,得到的是P1->P1,P2-P1,P3->P1,P1->P2,P2->P2,P3->P2,P1->P3,P2->P3,P3->P3(Pm->Pn表示第m个人相对于第n个人的相对位置坐标)。通过将这[N*N,2]数据输入至2*16的全连接层得到shape为[N*N,16]的curr_rel_embedding。另一方面,针对输入的final_h,其包括了一批数据所有人的隐藏状态,而不仅仅是一个序列的人的隐藏状态,所以需要对其提取每个序列的人的隐藏状态,同时进行维度变换以及repeat操作,仍以3人在一个序列为例,得到[H1,H2,H3,H1,H2,H3,H1,H2,H3],其为curr_hidden_1,维度为[N*N,32],通过将curr_rel_embedding和curr_hidden_1合并,形成mlp_h_input输入至48*512*8的全连接层,然后在对其进行Maxpooling,得到一个序列的pool_h,shape为[N,8],通过对这批数据所有序列都进行相应的处理,将所有的pool_h合并成新的pool_h,shape为[batch,8],每一行对应一个人,即论文中所说的a pooled tensor Pi for each person。如果仔细研究论文中的figure2和论文中的figure3,你会发现作者以不同的填充图案以表征不同的tensor。在figure3中,实心的绿色表示经2*16全连接层MLP输出的curr_rel_embedding,其与encoder部分LSTM的输出斜条纹表示的curr_hidden_1进行合并(斜条纹正好与figure2的LSTM的输出是对应的),输入至48*512*8的全连接层,然后进行Maxpooling,然后得到了为每个人生成了一个特征张量Pi,其由砖块填充图案表示。是不是发现一切都对应上了,哈哈哈。
好了,接下来我先不急着看decoder部分,我们先来看TrajectoryGenerator类。如下图,其为该类的抽象图。该类的__init__方法分别定义了Encoder类、Decoder类、以及池化层类的实例。同时根据在输入decoder部分的LSTM之前是否需要经过一个全连接层定义了一个带relu激活函数的全连接层。如果元组类型的参数noise_dim的第一个元素不为0或者有池化层或者encoder部分LSTM的hidden_size与decoder部分的LSTM的hidden_size不一致时,说明需要全连接层,这样可以保证最后的decoder_h符合LSTM的格式。
 TrajectoryGnerator抽象图
TrajectoryGnerator抽象图
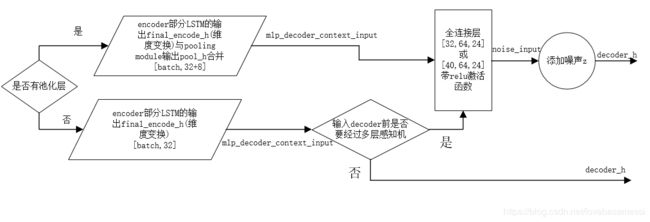
来看其forward函数,首先得到encoder部分LSTM的隐藏状态输出final_encoder_h,即encoder网络结构抽象图中的final_h。然后根据是否有池化层进行以下操作:
- 有池化层,将上一步的final_encoder_h等数据送入池化层,得到pool_h,并将final_encoder_h与pool_h进行拼接,得到mlp_decoder_context_input
- 没有池化层,直接将上一步得到的final_encoder_h经过维度变换作为mlp_decoder_context_input
如果需要经过全连接层,则还需要将得到的mlp_decoder_context_input经过全连接层,如果有池化层,其必然是要经过全连接层的,且全连接层的输入层维度为40,而如果不需要池化层,则全连接层的输入层维度为32。经过全连接层之后,将得到的noise_input与一个噪声z进行合并,得到decoder_h,这个噪声分为全局噪声还是非全局噪声,如果是全局噪声,则每个人的噪声都一样,否则每个人的噪声都不一样。如果不经过全连接层,则decoder_h=noise_input=mlp_decoder_context_input。然后将最后一个观测帧中人的位置以及位置变化以及有decoder_h与decoder_c组成的元组等参数送入Decoder类的实例对象中作为其参数,经过decoder之后,得到预测的每一帧相对于上一帧的位置变化数据。
好了,接下来来看decoder部分吧。其__init__方法中定义了一个LSTM网络结构,一个2*16的全连接层,一个32*2的全连接层,并且根据是否每生成一次预测数据都池化一次又定义了池化层与全连接层。因为池化过后都是要经过TrajectoryGnerator抽象图中的全连接层的。decoder网络结构抽象图抽象图如下图所示。
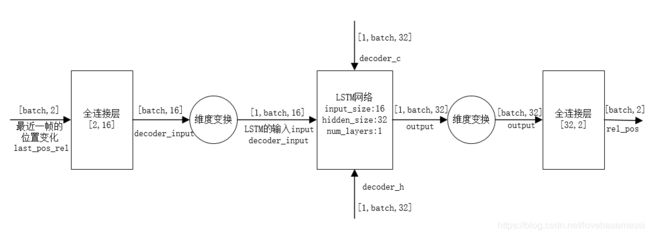 decoder网络结构抽象图
decoder网络结构抽象图
如上图所看到的的,首先,对要预测的帧数进行循环,每次循环预测出一帧。其先将最近一帧的位置变化输入到2*16的全连接层,得到[batch,16]的decoder_input,再维度变换为LSTM的input的格式,然后decoder_h即为TrajectoryGnerator抽象图中的decoder_h,decoder_h和decoder_c都是在TrajectoryGnerator的forward函数里面生成的。得到的output经过维度变换再输入至32*2的全连接层,得到[batch,2]的相对于当前帧的位置变化。这样for循环后,pre_len个坐标变化就得到了,根据每一帧的坐标变化,自然就可以得到预测轨迹了。另外decoder里有一个pool_every_timestep选项,也就是每预测出一帧的坐标变化后是否要重新池化。就是说把Pooling Module网络结构抽象图中由encoder部分LSTM产生的输入final_h更新为decoder部分LSTM最新输出的隐藏状态作为Pooling Module的新输入去替换final_h,然后池化后再经过TrajectoryGnerator抽象图中的全连接层,不过注意的是,除了第一次添加噪声z之外,后续每一步的池化都不需要再追加噪声z了。所以,如果pre_len=12,其会池化12次,只有第一次需要z,后续不在追加噪声z。
接下来,就是最后一个类TrajectoryDiscriminator了,这个类比较简单。其主要就是对轨迹进行打分,以判断轨迹是真实的轨迹还是预测的轨迹。其主要是copy了一份上文encoder部分的网络,然后得到final_h,另外又搭建了一个全连接层,该全连接层输出网络生成的分数。另外这个类里面有一个d_type选项,其默认是local,如果是local的话,其会直接把final_h做维度变化作为全连接层的输入。如果是global的话,final_h需要先作为一个池化层的输入,经过池化以后再输入至全连接层生成得分。程序默认d_type为local,也就是独立的处理每一条轨迹,为每一条轨迹打分。global的话我猜大致是直接为这一批轨迹打分,这一批轨迹的分数都是一样的,即他们要么全被当做真实轨迹要么全被当做预测轨迹。
OK,全文结束!!!!!!!