spark2.3+hadoop2.8.2+java1.8+scala2.11.12完全分布式搭建过程
软硬件环境
lunix机器三台及以上,window机器一台安装xshell来控制所有lunix机器
机器之间在同一个局域网,通过xshell可以互相ping通
可创建新用户并赋给管理员权限并在用户下搭建环境
直接在root用户下搭建环境
所有配置均在一台机器改配置文件,然后发送给其他机器节点
集群之间必须做免密通信
cd /etc/profile 最终 配置文件
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_172
export HADOOP_HOME=/usr/local/hadoop-2.8.2
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib/tools.jar
export PATH=${JAVA_HOME}/bin:$PATH
export PATH=${HADOOP_HOME}/bin:$PATH
export SPARK_HOME=/usr/local/spark-2.3.0-bin-hadoop2.7
export PATH=${SPARK_HOME}/bin:$PATH
export SCALA_HOME=/usr/local/scala-2.11.12
export PATH=${SCALA_HOME}/bin:$PATH
1.1、检查一下系统中的jdk版本
java -version
检测jdk安装
rpm -qa | grep java
卸载openjdk
yum remove *openjdk*
之后再次输入rpm -qa | grep java 查看卸载情况:
安装自己的jdk
1.2修改计算机别名
vi /etc/hosts 计算机别名
添加
192.168.1.101 master
192.168.1.102 slaves1
192.168.1.103 slaves2
给主机取别名
通过xshell 输入 vim /etc/hosts 然后点击 i 实现快捷键插入功能
#主节点
192.168.1.101 master
#从节点
192.168.1.102 slaves1
#从节点
192.168.1.103 slaves2
保存退出 先点击esc退出插入模式然后在最下方输入 :wq 回车保存退出 刷新文件 source /etc/hosts
1.3修改计算机从节点名
进入目录cd /usr/local/ hadoop-2.8.2/etc/hadoop
vi slaves
slaves1
slaves2
启动服务初始化
hdfs namenode -format
1.3.1查看端口号
netstat –ntulp
1.3.2查看端口号占用
netstat -anp |grep 8888
进入服务目录
cd /usr/local/hadoop-2.8.2/sbin
启动服务
sh start-all.sh sh stop-all.sh
1.4安装集群 cd /usr/local/ 下
解压
tar -zxvf jdk1.8.0_172.tgz
tar -zxvf scala-2.11.12.tgz
tar -zxvf hadoop-2.8.2.tgz
tar -zxvf spark-2.3.0-bin-hadoop2.7.tgz
复制/etc/hosts
scp /etc/hosts slaves1:/etc/
scp /etc/hosts slaves2:/etc/
复制java
scp -r /usr/lib/jvm/jdk1.8.0_172 node02: /usr/lib/jvm/
scp -r /usr/lib/jvm/jdk1.8.0_172 node03: /usr/lib/jvm/
1.5Hadoop配置
cd /usr/local/hadoop-2.8.2/etc/hadoop
改文件hadoop-env.sh
# 添加Java绝对路径,相对路径启动不了
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_172
改文件yarn-site.xml
改文件core-site.xml
改文件 hdfs-site.xml
改文件mapred-site.xml
复制 hadoop
scp -r /usr/local/hadoop-2.8.2 node02:/usr/local/
scp -r /usr/local/hadoop-2.8.2 node03:/usr/local/
复制 scala
scp -r /usr/local/ scala-2.11.12 node02:/usr/local/
scp -r /usr/local/ scala-2.11.12 node03:/usr/local/
spark配置
cd /usr/local/spark-2.3.1-bin-without-hadoop/conf
slaves.template 改成slaves
vi slaves
删除 localhost添加从节点
slaves1
slaves2
配置spark-env.sh
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_172
export SCALA_HOME=/usr/local/scala-2.11.12
export HADOOP_HOME=/usr/local/hadoop-2.8.2
export SPARK_HOME=/usr/local/spark-2.3.1-bin-without-hadoop
#hadoop集群的配置文件的目录
export HADOOP_CONF_DIR=/usr/local/hadoop-2.8.2/etc/hadoop
#spark集群的Master节点的ip地址
export SPARK_MASTER_IP=192.168.1.103
#export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop-2.8.2/bin/hadoop classpath)
#export SPARK_MASTER_WEBUI_PORT=8080
#每个worker节点能够最大分配给exectors的内存大小
export SPARK_WORKER_MEMORY=2g
#每个worker节点所占有的CPU核数目
export SPARK_WORKER_CORES=2
#每台机器上开启的worker节点的数目
export SPARK_WORKER_INSTANCES=1
export SPARK_LOCAL_IP=192.168.1.103
复制 spark
scp -r /usr/local/ spark-2.3.0-bin-hadoop2.7.tgz node02:/usr/local/
scp -r /usr/local/ spark-2.3.0-bin-hadoop2.7.tgz node03:/usr/local/
复制/etc/profile (记得要刷新环境变量)
scp /usr/local/spark-2.3.1-bin-without-hadoop/conf/spark-env.sh node02:/usr/local/spark-2.3.1-bin-without-hadoop/conf/
scp /usr/local/spark-2.3.1-bin-without-hadoop/conf/spark-env.sh node03:/usr/local/spark-2.3.1-bin-without-hadoop/conf/
scp /usr/local/spark-2.3.1-bin-without-hadoop/conf/slaves node02:/usr/local/spark-2.3.1-bin-without-hadoop/conf/
scp /usr/local/spark-2.3.1-bin-without-hadoop/conf/slaves node03:/usr/local/spark-2.3.1-bin-without-hadoop/conf/
启动程序
启动hadoop hdfs系统就可以
cd /usr/local/spark-2.3.1-bin-without-hadoop/sbin
sh start-dfs.sh
启动spark
cd /usr/local/spark-2.3.1-bin-without-hadoop/sbin
sh start-all.sh
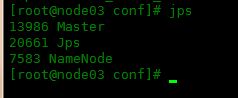
主节点显示
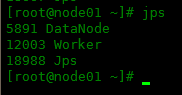
从节点显示
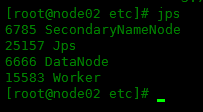
从节点显示
hadoop控制台
http://192.168.1.103:50090
spark控制台
http://192.168.1.103:8080
创建输入目录
hadoop fs -mkdir /hdfsin
上传文件
hadoop fs -put wordcount.txt /hdfsin
运行文件
hadoop jar hadoop-mapreduce-examples-2.8.2.jar wordcount /hdfsin /out
错误
ava.io.IOException:
File system image contains an old layout version -60.
An upgrade to version -63 is required.
Please restart NameNode with the "-rollingUpgrade started" option if a rolling upgrade is already started; or restart NameNode with the "-upgrade" option to start a new upgrade.
解决
停掉所有服务,重启sh start-dfs.sh -upgrade 更新保存