JavaScript|前端快速复习(二)
Javascript模块复习
1.js基础知识
js数据类型
变量有以下数据类型:
- 值类型(基本类型):字符串(String)、数字(Number)、布尔(Boolean)、对空(Null)、未定义(Undefined)、Symbol。
- 引用数据类型:对象(Object)
堆内存和栈内存
- JS中,所有的变量都是保存在栈内存中的。
- 基本数类型:值类型的值,直接保存在栈内存中。值与值之间是独立存在,修改一个变量不会影响其他的变量。
- 引用数据类型:对象是保存到堆内存中的。每创建一个新的对象,就会在堆内存中开辟出一个新的空间,而变量保存了对象的内存地址(对象的引用)。如果两个变量保存了同一个对象的引用,当一个通过一个变量修改属性时,另一个也会受到影响。
数组方法
基本方法
四个基本方法如下:
| 方法 | 描述 | 备注 |
|---|---|---|
| push() | 向数组的最后面插入一个或多个元素,返回结果为该数组新的长度 | 会改变原数组 |
| pop() | 删除数组中的最后一个元素,返回结果为被删除的元素 | 会改变原数组 |
| unshift() | 在数组最前面插入一个或多个元素,返回结果为该数组新的长度 | 会改变原数组 |
| shift() | 删除数组中的第一个元素,返回结果为被删除的元素 | 会改变原数组 |
遍历数组
遍历数组的方法如下:
| 方法 | 描述 | 备注 |
|---|---|---|
| for循环 | 这个大家都懂 | |
| forEach() | 和 for循环类似,但需要兼容IE8以上 | forEach() 没有返回值。也就是说,它的返回值是 undefined |
| filter() | 返回结果是true的项,将组成新的数组。可以起到过滤的作用 | 不会改变原数组 |
| map() | 对原数组中的每一项进行加工 | |
| every() | 如果有一项返回false,则停止遍历 | 意思是,要求每一项都返回true,最终的结果才返回true |
| some() | 只要有一项返回true,则停止遍历 |
数组的常见方法如下:
| 方法 | 描述 | 备注 |
|---|---|---|
| slice() | 从数组中提取指定的一个或多个元素,返回结果为新的数组 | 不会改变原数组 |
| splice() | 从数组中删除指定的一个或多个元素,返回结果为新的数组 | 会改变原数组 |
| concat() | 连接两个或多个数组,返回结果为新的数组 | 不会改变原数组 |
| join() | 将数组转换为字符串,返回结果为转换后的字符串 | 不会改变原数组 |
| reverse() | 反转数组,返回结果为反转后的数组 | 会改变原数组 |
| sort() | 对数组的元素,默认按照Unicode编码,从小到大进行排序 | 会改变原数组 |
| reduce() | 迭代数组的所有项,然后构建一个最终返回的值(function,初始值) | 不改原数组 |
| reduceRight() | (function(prev, cur, index, array){ return |
后项遍历(不) |
数组的其他方法如下:
| 方法 | 描述 | 备注 |
|---|---|---|
| indexOf(value) | 从前往后索引,获取 value 在数组中的第一个下标 | |
| lastIndexOf(value) | 从后往前索引,获取 value 在数组中的最后一个下标 | |
| find(function()) | 找出第一个满足「指定条件返回true」的元素。 | |
| findIndex(function()) | 找出第一个满足「指定条件返回true」的元素的index | |
| Array.from(arrayLike) | 将伪数组转化为真数组 | |
| Array.of(value1, value2, value3) | 将一系列值转换成数组。 | |
| isArray(obj) | 用于判断一个对象是否为数组。 | |
| toString() | 把数组转换成字符串,每一项用,分割 |
|
| valueOf() | 返回数组本身 | |
| includes(searchElement, fromIndex) | 方法用来判断一个数组是否包含一个指定的值,如果是返回 true,否则false。 |
补充知识
- 数组的set集合内部无重复,(只需要将最后转化为数组即可array.from)
- reduce() 方法接收一个函数作为累加器,数组中的每个值(从左到右)开始缩减,最终计算为一个值。
String
String属性
| 属性 | 描述 |
|---|---|
| constructor | constructor 属性返回对 String 对象属性创建的函数 |
| length | 字符串的长度 |
| propotype | prototype 属性允许您向对象添加属性和方法 |
String方法
| 方法 | 描述 |
|---|---|
| charAt() | 返回指定位置的字符 |
| charCodeAt() | 返回在指定的位置的字符的 Unicode 编码 |
| concat() | 连接两个或更多字符串,并返回新字符串 |
| fromCharCode() | 将Unicode编码转换为字符 |
| indexOf() | 返回指定字符串在字符串中首次出现的位置 |
| lastIndexOf() | 与indexOf()搜索方向相反,方法可返回一个指定的字符串值最后出现的位置,在一个字符串中的指定位置从后向前搜索。 |
| match() | 查找找到一个或多个正则表达式的匹配 |
| replace() | 在字符串中查找匹配的子串, 并替换与正则表达式匹配的子串 |
| search() | 查找与正则表达式相匹配的值 |
| slice() | 提取字符串的片断,并在新的字符串中返回被提取的部分 |
| split() | 把字符串分割为字符串数组 |
| substr() | 从起始索引号提取字符串中指定数目的字符 |
| substring() | 提取字符串中两个指定的索引号之间的字符 |
| toLowerCase() | 把字符串转换为小写 |
| toUpperCase() | 把字符串转换为大写 |
| trim() | 出去字符串两边的空白 |
| valueOf() | 返回某个字符串对象的原始值 |
内置对象 Math 的常见方法
| 方法 | 描述 | 备注 |
|---|---|---|
| Math.abs() | 返回绝对值 | |
| Math.floor() | 向下取整(向小取) | |
| Math.ceil() | 向上取整(向大取) | |
| Math.round() | 四舍五入取整(正数四舍五入,负数五舍六入) | |
| Math.random() | 生成0-1之间的随机数 | 不包含0和1 |
| Math.max(x, y, z) | 返回多个数中的最大值 | |
| Math.min(x, y, z) | 返回多个数中的最小值 | |
| Math.pow(x,y) | 返回 x 的 y 次幂 | |
| Math.sqrt() | 对一个数进行开方运算 |
Math 和其他的对象不同,它不是一个构造函数,不需要创建对象。
2.原型链
原型链是面向对象的基础,是非常重要的部分。有以下几种知识:
- 创建对象有几种方法
- 原型、构造函数、实例、原型链
instanceof的原理- new 运算符
创建对象有几种方法
方式1:字面量
var obj11 = {name: 'qianguyihao'};
var obj12 = new Object(name: 'qianguyihao'); //内置对象(内置的构造函数)
上面的两种写法,效果是一样的。因为,第一种写法,obj11会指向Object。
- 第一种写法是:字面量的方式。
- 第二种写法是:内置的构造函数
方式2:通过构造函数
var M = function (name) {
this.name = name;
}
var obj3 = new M('smyhvae');
方法3:Object.create
var p = {name:'smyhvae'};
var obj3 = Object.create(p); //此方法创建的对象,是用原型链连接的
第三种方法,很少有人能说出来。这种方式里,obj3是实例,p是obj3的原型(name是p原型里的属性),构造函数是Objecet 。

原型、构造函数、实例,以及原型链
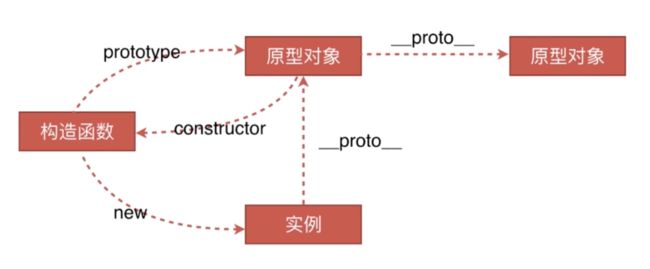
PS:任何一个函数,如果在前面加了new,那就是构造函数。
原型、构造函数、实例三者之间的关系

- 1、构造函数通过 new 生成实例
- 2、构造函数也是函数,构造函数的
prototype指向原型。(所有的函数有prototype属性,但实例没有prototype属性) - 3、原型对象中有 constructor,指向该原型的构造函数。
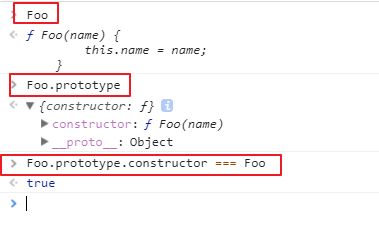
上面的三行,代码演示:
var Foo = function (name) {
this.name = name;
}
var foo = new Foo('smyhvae');
上面的代码中,Foo.prototype.constructor === Foo的结果是true:
- 4、实例的
__proto__指向原型。也就是说,foo.__proto__ === Foo.prototype。
声明:所有的引用类型(数组、对象、函数)都有__proto__这个属性。
Foo.__proto__ === Function.prototype的结果为true,说明Foo这个普通的函数,是Function构造函数的一个实例。
原型链
原型链的基本原理:任何一个实例,通过原型链,找到它上面的原型,该原型对象中的方法和属性,可以被所有的原型实例共享。
Object是原型链的顶端。
原型可以起到继承的作用。原型里的方法都可以被不同的实例共享:
//给Foo的原型添加 say 函数
Foo.prototype.say = function () {
console.log('');
}
原型链的关键:在访问一个实例的时候,如果实例本身没找到此方法或属性,就往原型上找。如果还是找不到,继续往上一级的原型上找。
instanceof的原理

instanceof的作用:用于判断实例属于哪个构造函数。
instanceof的原理:判断实例对象的__proto__属性,和构造函数的prototype属性,是否为同一个引用(是否指向同一个地址)。
注意1:虽然说,实例是由构造函数 new 出来的,但是实例的__proto__属性引用的是构造函数的prototype。也就是说,实例的__proto__属性与构造函数本身无关。
注意2:在原型链上,原型的上面可能还会有原型,以此类推往上走,继续找__proto__属性。这条链上如果能找到, instanceof 的返回结果也是 true。
比如说:
foo instance of Foo的结果为true,因为foo.__proto__ === Foo.prototype为true。foo instance of Objecet的结果也为true,因为Foo.prototype.__proto__ === Object.prototype为true。
但我们不能轻易的说:foo 一定是 由Object创建的实例。这句话是错误的。我们来看下一个问题就明白了。
例题
问题:已知A继承了B,B继承了C。怎么判断 a 是由A直接生成的实例,还是B直接生成的实例呢?还是C直接生成的实例呢?
分析:这就要用到原型的constructor属性了。
foo.__proto__.constructor === Foo的结果为true,但是foo.__proto__.constructor === Object的结果为false。
所以,用 consturctor判断就比用 instanceof判断,更为严谨。
new 运算符
当new Foo()时发生了什么:
(1)创建一个新的空对象实例。
(2)将此空对象的隐式原型指向其构造函数的显示原型。
(3)执行构造函数(传入相应的参数,如果没有参数就不用传),同时 this 指向这个新实例。
(4)如果返回值是一个新对象,那么直接返回该对象;如果无返回值或者返回一个非对象值,那么就将步骤(1)创建的对象返回。
3.继承的几种方式
继承的本质就是原型链。继承的方式有几种?每种形式的优缺点是?
方式1:借助构造函数
function Parent() {
this.name = 'Parent 的属性';
}
function Child1() {
Parent1.call(this); //【重要】此处用 call 或 apply 都行:改变 this 的指向
this.type = 'child1 的属性';
}
console.log(new Child1);
【重要】Parent1.call(this) 意思是:让Parent的构造函数在child的构造函数中执行。改变this的指向,parent的实例 --> 改为指向child的实例。导致 parent的实例的属性挂在到了child的实例上,这就实现了继承。
结果表明:child先有了 parent 实例的属性(继承得以实现),再有了child 实例的属性。
分析:这种方式,虽然改变了 this 的指向,但是,Child1 无法继承 Parent1 的原型。也就是说,如果我给 Parent1 的原型增加一个方法:这个方法是无法被 Child1 继承的。
Parent1.prototype.say = function () { };
方法2:通过原型链实现继承
/* 通过原型链实现继承*/
function Parent2() {
this.name = 'Parent 的属性';
}
function Child2() {
this.type = 'Child 的属性';
}
Child2.prototype = new Parent2(); //【重要】
console.log(new Child2());
打印结果:
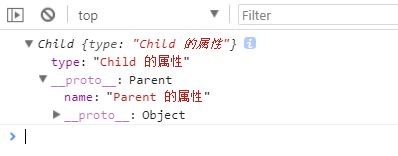
【重要】把Parent的实例赋值给了Child的prototye,从而实现继承。此时,Child构造函数、Parent的实例、Child的实例构成一个三角关系:
new Child.__proto__ === new Parent()的结果为true
**分析:**这种继承方式,Child 可以继承 Parent 的原型,
缺点:如果修改 child1实例的name属性,child2实例中的name属性也会跟着改变。
造成这种缺点的原因是:child1和child2共用原型。即:chi1d1.__proto__ === child2__proto__是严格相同。而 arr方法是在 Parent 的实例上(即 Child实例的原型)的。
方式3:组合的方式:构造函数 + 原型链
就是把上面的两种方式组合起来:
/*组合方式实现继承:构造函数、原型链 */
function Parent3() {
this.name = 'Parent 的属性';
this.arr = [1, 2, 3];
}
function Child3() {
Parent3.call(this); //【重要1】执行 parent方法,实现继承的方式Father.call(this)
this.type = 'Child 的属性';//parent3的实例属性挂载到child上
}
Child3.prototype = new Parent3(); //【重要2】第二次执行parent方法
var child = new Child3();
这种方式,能解决之前两种方式的问题:既可以继承父类原型的内容,也不会造成原型里属性的修改。
这种方式的缺点是:让父亲Parent的构造方法执行了两次。
方式4:prototype赋等
Child4.prototype=Parent4.prototype;
方式5:Object.create
Child5.prototype=Object.create(Parent5.prototype);
Child5.prototype.constructor=Child5
Object.create创建对象的方法,是用原型链对接
4.this指向问题
this指向
解析器在调用函数每次都会向函数内部传递进一个隐含的参数,这个隐含的参数就是this,this指向的是一个对象,这个对象我们称为函数执行的 上下文对象。
根据函数的调用方式的不同,this会指向不同的对象:【重要】
- 1.以函数的形式调用时,this永远都是window。比如
fun();相当于window.fun(); - 2.以方法的形式调用时,this是调用方法的那个对象
- 3.以构造函数的形式调用时,this是新创建的那个对象
- 4.使用call()和apply()调用时,this是指定的那个对象
箭头函数中this的指向:
ES6中的箭头函数并不会使用上面四条标准的绑定规则,而是会继承外层函数调用的this绑定(无论this绑定到什么)。
call()和apply()
这两个方法都是函数对象的方法,需要通过函数对象来调用。
当函数调用call()和apply()时,函数都会立即执行。
- 改变this的指向
- 实现继承。Father.call(this)
- 显示绑定:第一个参数都是this要指向的对象(函数执行时,this将指向这个对象),后续参数用来传实参。
第一个参数的传递
1、thisObj不传或者为null、undefined时,函数中的this会指向window对象(非严格模式)。
2、传递一个别的函数名时,函数中的this将指向这个函数的引用。
3、传递的值为数字、布尔值、字符串时,this会指向这些基本类型的包装对象Number、Boolean、String。
4、传递一个对象时,函数中的this则指向传递的这个对象。
call()和apply()的区别
call()和apply()方法都可以将实参在对象之后依次传递,但是apply()方法需要将实参封装到一个数组中统一传递(即使只有实参只有一个,也要放到数组中)。
如果是通过call的参数进行传参,是这样的:
persion1.say.call(persion2, "实验小学", "六年级");
如果是通过apply的参数进行传参,是这样的:
persion1.say.apply(persion2, ["实验小学", "六年级"]);
bind()
- 都能改变this的指向
- call()/apply()是立即调用函数
- bind()是将函数返回,因此后面还需要加
()才能调用。
bind 方法不会立即执行,而是返回一个改变了上下文 this 后的函数。而原函数 func 中的 this 并没有被改变,依旧指向全局对象 window。
使用方法:
function func(a, b, c) {
console.log(a, b, c);
}
var func1 = func.bind(null,'zoexyf');
func('A', 'B', 'C'); // A B C
func1('A', 'B', 'C'); // zoexyf A B
func1('B', 'C'); // zoexyf B C
func.call(null, 'zoexyf'); // zoexyf undefined undefined
在低版本浏览器没有 bind 方法,我们也可以自己实现一个。
手写bind方法实现(重要)
if (!Function.prototype.bind) {
Function.prototype.bind = function () {
var self = this, // 保存原函数
context = [].shift.call(arguments), // 保存需要绑定的this上下文
args = [].slice.call(arguments); // 剩余的参数转为数组
return function () { // 返回一个新函数
self.apply(context,[].concat.call(args, [].slice.call(arguments)));
}
}
}
绑定优先级: new绑定 > 显式绑定 >隐式绑定 >默认绑定
5.闭包
闭包理解
闭包概念
闭包就是能够读取其他函数内部数据(变量/函数)的函数。
只有函数内部的子函数才能读取局部变量,因此可以把闭包简单理解成"定义在一个函数内部的函数"。
当一个嵌套的内部(子)函数引用了嵌套的外部(父)函数的变量或函数时, 就产生了闭包。
- 闭包是嵌套的内部函数 ,包含被引用外部变量 or 函数的对象
产生闭包的条件
1.函数嵌套
2.内部函数引用了外部函数的数据(变量/函数)。
一种情况:外部函数被调用,内部函数被声明。比如:
- 内部函数被提前声明,就会产生闭包(不用调用内部函数)
- 采用的是“函数表达式”创建的函数,此时内部函数的声明并没有提前
常见的闭包
-
- 将一个函数作为另一个函数的返回值
-
- 将函数作为实参传递给另一个函数调用。
闭包1:函数作为另一函数的返回值
function fn1() {
var a = 2
function fn2() {
a++
console.log(a)
}
return fn2
}
var f = fn1(); //执行外部函数fn1,返回的是内部函数fn2
f() // 3 //执行fn2
f() // 4 //再次执行fn2
当f()第二次执行的时候,a加1了,也就说明了:闭包里的数据没有消失,而是保存在了内存中。如果没有闭包,代码执行完倒数第三行后,变量a就消失了。
上面的代码中,虽然调用了内部函数两次,但是,闭包对象只创建了一个。
也就是说,要看闭包对象创建了一个,就看:外部函数执行了几次(与内部函数执行几次无关)。
闭包2. 函数作为实参传给另一函数调用
function showDelay(msg, time) {
setTimeout(function() { alert(msg) }, time)
}
showDelay('atguigu', 2000)
上面的代码中,闭包是里面的funciton,因为它是嵌套的子函数,而且引用了外部函数的变量msg。
闭包的作用
- 作用1. 使用函数内部的变量在函数执行完后, 仍然存活在内存中(延长了局部变量的生命周期)
- 作用2. 让函数外部可以操作(读写)到函数内部的数据(变量/函数)
回答几个问题:
- 问题1. 函数执行完后, 函数内部声明的局部变量是否还存在?
答案:一般是不存在, 存在于闭包中的变量才可能存在。
闭包能够一直存在的根本原因是f(实例),因为f接收了fn1(),这个是闭包,闭包里有a。注意,此时,fn2并不存在了,但是里面的对象(即闭包)依然存在,因为用f接收了。
- 问题2. 在函数外部能直接访问函数内部的局部变量吗?
不能,但我们可以通过闭包让外部操作它。
闭包的生命周期
- 产生: 嵌套内部函数fn2被声明时就产生了(不是在调用)
- 死亡: 嵌套的内部函数成为垃圾对象时。(比如f = null,就可以让f成为垃圾对象。意思是,此时f不再引用闭包这个对象了)
闭包的应用:定义具有特定功能的js模块
- 将所有的数据和功能都封装在一个函数内部(私有的),只向外暴露一个包含n个方法的对象或函数。
- 模块的使用者, 只需要通过模块暴露的对象调用方法来实现对应的功能。
方式1:向外暴露含多个函数的对象
(1)myModule.js:(定义一个模块,向外暴露多个函数,供外界调用)
function myModule() {
//私有数据
var msg = 'Zoexyf Haha'
//操作私有数据的函数
function doSomething() {
console.log('doSomething() ' + msg.toUpperCase()); //字符串大写
}
function doOtherthing() {
console.log('doOtherthing() ' + msg.toLowerCase()) //字符串小写
}
//通过【对象字面量】的形式进行包裹,向外暴露多个函数
return {
doSomething1: doSomething,
doOtherthing2: doOtherthing
}
}
上方代码中,外界可以通过doSomething1和doOtherthing2来操作里面的数据,但不让外界看到。
(2)index.html:
<script type="text/javascript" src="myModule.js">script>
<script type="text/javascript">
var module = myModule();
module.doSomething1();
module.doOtherthing2();
script>
方式2:匿名函数直接传给window对象
同样是实现方式一种的功能,这里我们采取另外一种方式。
(1)myModule2.js:(是一个立即执行的匿名函数)
(function () {
var msg = 'Zoexyf Haha' //私有数据
//操作私有数据的函数
function doSomething() {
console.log('doSomething() ' + msg.toUpperCase())
}
function doOtherthing() {
console.log('doOtherthing() ' + msg.toLowerCase())
}
//外部函数是即使运行的匿名函数,我们可以把两个方法直接传给window对象
window.myModule = {
doSomething1: doSomething,
doOtherthing2: doOtherthing
}
})()
(2)index.html:
<script type="text/javascript" src="myModule2.js">script>
<script type="text/javascript">
myModule.doSomething1()
myModule.doOtherthing2()
script>
上方两个文件中,我们在myModule2.js里直接把两个方法直接传递给window对象了。于是,在index.html中引入这个js文件后,会立即执行里面的匿名函数。在index.html中把myModule直接拿来用即可。
匿名函数更方便
闭包的缺点及解决
缺点:函数执行完后, 函数内的局部变量没有释放,占用内存时间会变长,容易造成内存泄露。
解决:能不用闭包就不用,及时释放。比如:
f = null; // 让内部函数成为垃圾对象 -->回收闭包
总而言之,你需要它,就是优点;你不需要它,就成了缺点。
内存溢出和内存泄露
内存溢出:一种程序运行出现的错误。当程序运行需要的内存超过了剩余的内存时, 就出抛出内存溢出的错误。
内存泄漏:占用的内存没有及时释放。
注意,内存泄露的次数积累多了,就容易导致内存溢出。
常见的内存泄露:
- 1.意外的全局变量
- 2.没有及时清理的计时器或回调函数—>clearInterval()
- 3.闭包—>f = null //让内部函数成为垃圾对象–>回收闭包
缓存:存在内存中数据一只没有被清掉
作用域未释放(闭包)
无效的 DOM 引用
没必要的全局变量
定时器未清除(React中的合成事件,还有原生事件的绑定区别)
事件监听为清空
内存泄漏优化
6.Promise
Promise 是异步编程的一种解决方案,比传统的异步解决方案【回调函数】和【事件】更合理、更强大。现已被 ES6 纳入进规范中。
eg:
function callback() {
console.log('Done');
}
console.log('before setTimeout()');
setTimeout(callback, 1000); // 1秒钟后调用callback函数
console.log('after setTimeout()');
before setTimeout()
after setTimeout()
(等待1秒后)
Done
API
Promise 的常用 API 如下:
Promise.resolve(value)
类方法,该方法返回一个以 value 值解析后的 Promise 对象 1、如果这个值是个 thenable(即带有 then 方法),返回的 Promise 对象会“跟随”这个 thenable 的对象,采用它的最终状态(指 resolved/rejected/pending/settled)
2、如果传入的 value 本身就是 Promise 对象,则该对象作为 Promise.resolve 方法的返回值返回。
3、其他情况以该值为成功状态返回一个 Promise 对象。
上面是 resolve 方法的解释,传入不同类型的 value 值,返回结果也有区别。这个 API 比较重要,建议大家通过练习一些小例子,并且配合上面的解释来熟悉它。如下几个小例子:
//如果传入的 value 本身就是 Promise 对象,则该对象作为 Promise.resolve 方法的返回值返回。
function fn(resolve){
setTimeout(function(){
resolve(123);
},3000);
}
let p0 = new Promise(fn);
let p1 = Promise.resolve(p0);
// 返回为true,返回的 Promise 即是 入参的 Promise 对象。
console.log(p0 === p1);
复制代码
传入 thenable 对象,返回 Promise 对象跟随 thenable 对象的最终状态。
ES6 Promises 里提到了 Thenable 这个概念,简单来说它就是一个非常类似 Promise 的东西。最简单的例子就是 jQuery.ajax,它的返回值就是 thenable 对象。但是要谨记,并不是只要实现了 then 方法就一定能作为 Promise 对象来使用。
//如果传入的 value 本身就是 thenable 对象,返回的 promise 对象会跟随 thenable 对象的状态。
let promise = Promise.resolve($.ajax('/test/test.json'));// => promise对象
promise.then(function(value){
console.log(value);
});
复制代码
返回一个状态已变成 resolved 的 Promise 对象。
let p1 = Promise.resolve(123);
//打印p1 可以看到p1是一个状态置为resolved的Promise对象
console.log(p1)
复制代码
Promise.reject
类方法,且与 resolve 唯一的不同是,返回的 promise 对象的状态为 rejected。
Promise.prototype.then
实例方法,为 Promise 注册回调函数,函数形式:fn(vlaue){},value 是上一个任务的返回结果,then 中的函数一定要 return 一个结果或者一个新的 Promise 对象,才可以让之后的then 回调接收。
Promise.prototype.catch
实例方法,捕获异常,函数形式:fn(err){}, err 是 catch 注册 之前的回调抛出的异常信息。
Promise.race
类方法,多个 Promise 任务同时执行,返回最先执行结束的 Promise 任务的结果,不管这个 Promise 结果是成功还是失败。 。
Promise.all
类方法,多个 Promise 任务同时执行。
如果全部成功执行,则以数组的方式返回所有 Promise 任务的执行结果。 如果有一个 Promise 任务 rejected,则只返回 rejected 任务的结果。
async/await
基本理解
async 函数,就是 Generator 函数的语法糖,它建⽴在Promises上,并且与所有现有的基于Promise的API兼容。
-
Async—声明⼀个异步函数(async function someName(){…})
-
⾃动将常规函数转换成Promise,返回值也是⼀个Promise对象
-
只有async函数内部的异步操作执⾏完,才会执⾏then⽅法指定的回调函数
-
异步函数内部可以使⽤await
await,配套async使用
-
Await—暂停异步的功能执⾏(var result = await someAsyncCall()
-
放置在Promise调⽤之前,await强制其他代码等待,直到Promise完成并返回结果
-
只能与Promise⼀起使⽤,不适⽤与回调
-
只能在async函数内部使⽤
对比Promise的优势
-
代码读起来更加同步,Promise虽然摆脱了回调地狱,但是then的链式调⽤也会带来额外的阅读负担
-
Promise传递中间值⾮常麻烦,⽽async/await⼏乎是同步的写法,⾮常优雅
-
错误处理友好,async/await可以⽤成熟的try/catch,Promise的错误捕获⾮常冗余
-
调试友好,Promise的调试很差,由于没有代码块,你不能在⼀个返回表达式的箭头函数中设置断点,如果你在⼀ 个.then代码块中使⽤调试器的步进(step-over)功能,调试器并不会进⼊后续的.then代码块,因为调试器只能跟踪 同步代码的『每⼀步』。
7.JavaScript执行机制
https://blog.csdn.net/ZD717822023/article/details/97491152
写的很好可以看一下
8.JavaScript垃圾回收
基本原理
JS 的垃圾回收机制的基本原理是:
-
找出那些不再继续使用的变量,然后释放其占用的内存,垃圾收集器会按照固定的时间间隔周期性地执行这一操作。
-
V8 的垃圾回收策略主要基于分代式垃圾回收机制,在 V8 中,将内存分为新生代和老生代,新生代的对象为存活时间较短的对象,老生代的对象为存活事件较长或常驻内存的对象。
-
V8 堆的整体大小等于新生代所用内存空间加上老生代的内存空间,而只能在启动时指定,意味着运行时无法自动扩充,如果超过了极限值,就会引起进程出错。
涉及到的算法
Scavenge 算法
-
在分代的基础上,新生代的对象主要通过 Scavenge 算法进行垃圾回收,在 Scavenge 具体实现中,主要采用了一种复制的方式的方法—— Cheney 算法。
-
Cheney 算法将堆内存一分为二,一个处于使用状态的空间叫 From 空间,一个处于闲置状态的空间称为 To 空间。分配对象时,先是在 From 空间中进行分配。
-
当开始进行垃圾回收时,会检查 From 空间中的存活对象,将其复制到 To 空间中,而非存活对象占用的空间将会被释放。完成复制后,From 空间和 To 空间的角色发生对换。
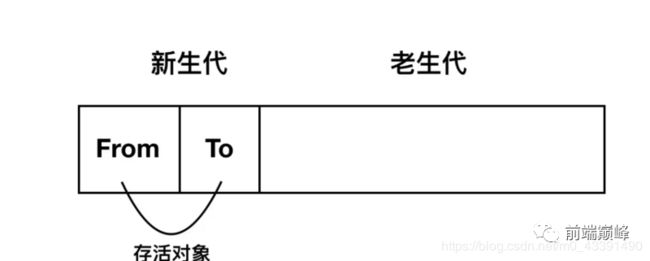
-
当一个对象经过多次复制后依然存活,他将会被认为是生命周期较长的对象,随后会被移动到老生代中,采用新的算法进行管理。
-
还有一种情况是,如果复制一个对象到 To 空间时,To 空间占用超过了 25%,则这个对象会被直接晋升到老生代空间中。
标记/清除算法
-
对于老生代中的对象,主要采用标记-清除和标记-整理算法。标记-清除 和前文提到的标记一样,与 Scavenge 算法相比,标记清除不会将内存空间划为两半,标记清除在标记阶段会标记活着的对象,而在内存回收阶段,它会清除没有被标记的对象。
-
而标记整理是为了解决标记清除后留下的内存碎片问题。
增量标记算法
-
Incremental Marking,前面的三种算法,都需要将正在执行的 JavaScript 应用逻辑暂停下来,待垃圾回收完毕后再恢复。这种行为叫作“全停顿”(stop-the-world)。
-
在 V8 新生代的分代回收中,只收集新生代,而新生代通常配置较小,且存活对象较少,所以全停顿的影响不大,而老生代就相反了。
-
为了降低全部老生代全堆垃圾回收带来的停顿时间,V8 将标记过程分为一个个的子标记过程,同时让垃圾回收标记和JS应用逻辑交替进行,直到标记阶段完成。
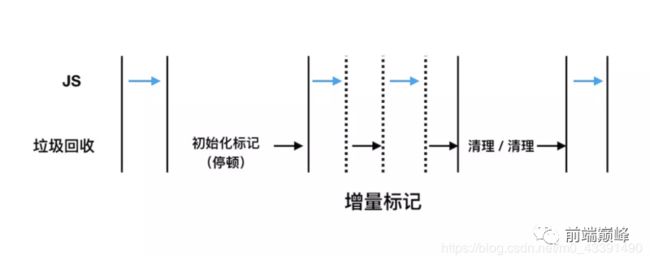
-
经过增量标记改进后,垃圾回收的最大停顿时间可以减少到原来的 1/6 左右。
的空间叫 From 空间,一个处于闲置状态的空间称为 To 空间。分配对象时,先是在 From 空间中进行分配。
-
当开始进行垃圾回收时,会检查 From 空间中的存活对象,将其复制到 To 空间中,而非存活对象占用的空间将会被释放。完成复制后,From 空间和 To 空间的角色发生对换。
[外链图片转存中…(img-JIapgFTw-1583825612393)]
-
当一个对象经过多次复制后依然存活,他将会被认为是生命周期较长的对象,随后会被移动到老生代中,采用新的算法进行管理。
-
还有一种情况是,如果复制一个对象到 To 空间时,To 空间占用超过了 25%,则这个对象会被直接晋升到老生代空间中。
标记/清除算法
-
对于老生代中的对象,主要采用标记-清除和标记-整理算法。标记-清除 和前文提到的标记一样,与 Scavenge 算法相比,标记清除不会将内存空间划为两半,标记清除在标记阶段会标记活着的对象,而在内存回收阶段,它会清除没有被标记的对象。
-
而标记整理是为了解决标记清除后留下的内存碎片问题。
增量标记算法
-
Incremental Marking,前面的三种算法,都需要将正在执行的 JavaScript 应用逻辑暂停下来,待垃圾回收完毕后再恢复。这种行为叫作“全停顿”(stop-the-world)。
-
在 V8 新生代的分代回收中,只收集新生代,而新生代通常配置较小,且存活对象较少,所以全停顿的影响不大,而老生代就相反了。
-
为了降低全部老生代全堆垃圾回收带来的停顿时间,V8 将标记过程分为一个个的子标记过程,同时让垃圾回收标记和JS应用逻辑交替进行,直到标记阶段完成。
[外链图片转存中…(img-ZVffyPNZ-1583825612394)]
-
经过增量标记改进后,垃圾回收的最大停顿时间可以减少到原来的 1/6 左右。