AMD统一渲染GPU架构 历程回顾与评测
AMD统一渲染GPU架构 历程回顾与评测
前言:NVIDIA公司历经长时间酝酿的Fermi架构高端产品GTX480/GTX470发布已经结束,经历了长达一个月的忙碌,我们已经了解到了这款产品的各项特性,众多用户和开发者组成显卡圈最近也趋于平淡。如果别人问到我,了解NVIDIA和AMD两家产品的性能后,你该做些什么?我想我该回忆两家公司这些年来在统一渲染架构方面成果,更重要的是思考它们所采用的不同发展模式最终带来的结果。
今天通过这篇分析和评测文章,我希望能够回顾AMD在统一渲染架构时代的发展历程,换而言之也就是分析从Radeon HD2000到Radeon HD5000系列AMD的GPU芯片设计思路,以及这种思路带给用户最终的使用体验。这是一条由最初的失败,逐渐看到转机,并最后走出自己特色走向成功的路径。如果你能耐心读完整篇文章,相信一定会有所收获。同时感谢迪兰恒进友情送测的“收藏级别”显卡帮助我们完成这次跨越时空的评测过程。

● 7年前的狂热和选择
2007年6月3日是AMD发布其第一款桌面级统一渲染架构GPU的时间,这款产品被命名为Radeon HD 2900 XT,它代表了全新的R600架构。从名称能够看出它代表了AMD最顶级GPU产品,而它的对手正是NVIDIA公司之前发布GeForce 8800 GTX。
我们按照一款GPU芯片的设计周期推测,Radeon HD 2900 XT所代表的R600架构,大约是在2003年开始设计的。而此后流传出的信息也印证了这个猜想,R600架构的设计思路提出,正是始于2003年,此后的故事就从这个时候开始。
2002年微软发布了DirectX 9.0,在这一代图形API中,PS单元的渲染精度已达到浮点精度,传统的硬件T&L单元被取消。全新的Vertex Shader(顶点着色引擎)编程将比以前复杂得多。DirectX 9.0的先进特性使得它早就了无数经典的PC游戏,GPU也从这个时候开始走上飞速发展的道路。
面对微软发布的全新API,两家厂商的反应是不同的。此时NVIDIA沉浸于GeForce4 Ti带来的全盛,这是一款在DirectX 8.0为NVIDIA公司带来无数好评的GPU产品,同时它当之无愧地代表了图形业界的最高性能。NVIDIA为了追求完美,选择稍作等待来支持更成熟的DirectX 9.0,在NDIDIA心中所谓“成熟”的Shader Model是一个较为特殊的版本,它实际上是由VS2.0和PS3.0组成的。
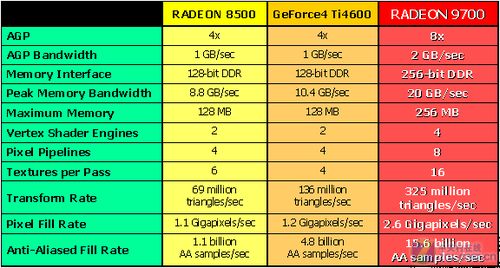
Radeon 9700与竞争对手规格对比
而ATI并没有选择“成熟”的Shader Model,依靠和微软紧密的合作,ATI发布Radeon 9700时,选择了VS 2.0/PS 2.0,并且发布速度惊人。直至5个月后,NVIDIA公司才发布了研发代号NV30的GeForce FX,同时这款产品在功耗和特性方面并不占优。
Radeon 9700成为了ATI最成功的一代显卡,无论高中低端,R300架构造就的ATI显卡在竞争中都取得明显的优势。R300应该是当时正式上市的最复杂的图形处理器,由0.15µm工艺制造的大约1亿700万个晶体管组成,相对于竞争对手的GPU,它的规模明显放大了很多。
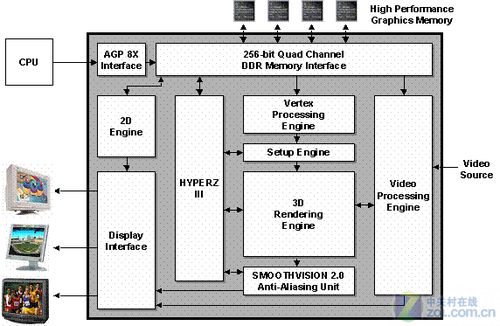
R300芯片微架构
ATI在这时尝到了甜头,R300的成功让它认为设计一款大型GPU产品,然后通过灵活地组合其功能单元开发出针对中低端市场的小型GPU产品,是非常容易获得利润的,同时保证了自己在高端领域的形象。
这种思路直接影响了R600的开发,尽管当时没有明确提出R600这个名称,但是ATI还是信心满满地开始规划未来的美好前景。
R300的成功,还为ATI赢得了另一份荣誉,那就是微软的信任。同为2003年,ATI和微软宣布了一份开发协议——由ATI来为当时的下一代主机XBOX开发业界尖端的图形单元Xenos。这打破了先前微软和NVIDIA的合作关系,意味着XBOX下一代主机的图形部分将更换一位新的合伙人。到了2005年,微软透露360将使用由ATI设计的专用图形单元,它工作在500MHz的时脉上,拥有48条统一着色器和10M嵌入式内存。

第一款统一渲染架构GPU——Xenos处理器
Xenos是微软与ATI的合作结晶,于2005年发布在XBOX360游戏主机中。这款GPU最大的特色是采用了统一着色器单元架构,顶点、像素着色器程序都在同样的单元上执行,由线程调度器作动态的资源分配,还引入了顶点纹理拾取(VTF单元)等ATI同期R5XX产品所不具备的特性。
| 濮元恺所写过的技术分析类文章索引(持续更新) | |||
| NVIDIA/ATI命运转折 |
改变翻天覆地 |
显卡只能玩游戏? 10年GPU通用计算回顾 |
通用计算对决 |
| 从裸奔到全身武装 |
AMD统一渲染架构 |
浅析DirectX11技术 |
摩尔定律全靠它 |
| 我就喜欢 |
别浪费你的电脑 分布式计算在中国 |
从Folding@home项目 |
Computex独家泄密 解析AMD下代GPU |

R520和R580对NVIDIA的影响
● R520和R580对NVIDIA的影响
此后为了应对NVIDIA迅速推出的Geforce 7800GTX,ATI发布了Radeon X1000系列产品,开发代号为R520。基于R520的X1800XT是全球首批采用0.09微米制程的显示核心。采用新工艺的好处是不言而喻的,除了使显卡的核心频率能达到前所未有的高度之外也降低了芯片的生产成本。
不过R520仍然不是Radeon X1000系列的最终形态,2006年1月24日,距离Radeon X1800发布4个月还不到的时间,ATI正式发布新一代的高端产品——Radeon X1900系列。作为06年推出的新高端产品,RADEON X1900不仅拥有高时钟频率的特点,而且还在架构上作了大刀阔斧的改进,性能获得显著提升。在玩家眼中最为出色的3:1黄金架构正是在R580时代诞生。
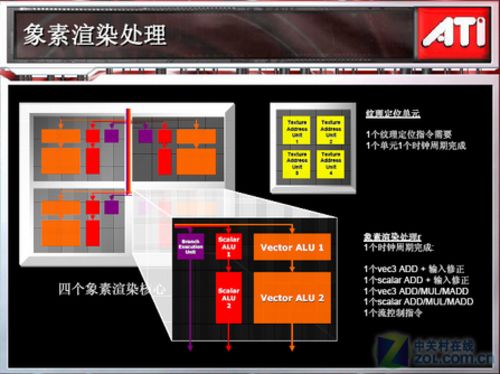
代号R580的RADEON X1900系列的每条传统的像素管线拥有3个像素渲染单元
传统的管线概念(Pipeline)中,像素渲染单元(Pixel Shader)跟Pipeline数目相同,NVIDIA的G70图形就是这样一个概念;但是ATI在全新的R580图形芯片中,稍微修正了像素渲染单元跟Pipeline的关系。Radeon X1900需要重点强调的地方在于,R580图形芯片拥有16条传统的像素管线(Pixel Pipeline),但是却拥有48个像素渲染单元和16个纹理单元,算术处理能力是以前旗舰级GPU的3倍,在晶体管数量只增加20%的情况下,渲染能力理论上增加了200%。
Radeon X1900让ATI重夺性能王座。ATI从R520到R580让人意想不到的变化无疑激怒了NVIDIA,NVIDIA习惯把持性能王座,它肯定不想王位被ATI夺去。在ATI内部,Carrell Killerbrew(ATi工程院院士、RV770首席架构师)正在下一个赌注,他打赌NV会低估R580,NV会像评估R480一样评估R580。他打赌NVIDIA会被R580弄得大吃一惊然后弄出一颗比G70大得多的芯片。NVIDIA不想丢掉性能王座,所以G80会是一个怪兽。
NVIDIA果然做出了惊人的选择,不但快速将GPU的着色器Shader结构从SIMD迁移到MIMD领域,同时将MIMD结构的流处理器数目提升到128个。代号G80的GeForce 8800 GTX相对于上一代产品,几乎经过了重新设计,各方面的改进都非常大。

G80微架构示意图
G80架构使用了多指令流多数据流MIMD结构标量流处理器,一共128个流处理器替代了原来分立的Vertex Shader和Pixel Shader,拥有当时最强的性能,当然G80拥有6.81亿个晶体管,是G71的2.5倍之多,显存方面384Bit显存位宽也充分保证了数据吞吐能力。在性能上GeForce 8800GTX显卡把3D图形处理器的性能又引领到一个前所未有的高度,这给对手承重的打击,ATI竟在半年之内拿不出一款足以抗衡G80核心的产品。NVIDIA凭借G80的革命性架构毫无悬念的夺取了3D性能的制高点。
G80架构奠定了NVIDIA此后长时间的产品线发展规划,直至今天在市场上热卖的GT240等中端产品,都基于G80架构衍生而来。同时G80架构在图形处理方面的执行效率出色,也成为NVIDIA自己至今难以逾越的标杆。
G80架构的所有流处理器,会被GigaThread线程处理器根据工作负荷,自动分配执行顶点着色器、几何着色器、像素着色器指令,线程调度是硬件执行完全自动化的,加上采用的是标量架构,不管是DX7、DX8、DX9、DX10还是OpenGL,G80的统一着色器都会达到100%的运作效率。这是MIMD架构区别与传统SIMD架构最明显的地方,也是NVIDIA和ATI在走进统一渲染时代所使用的不同策略。
R600与G80的不均衡对抗
● R600与G80的不均衡对抗
代号G80的GeForce 8800 GTX相对于上一代产品,几乎经过了重新设计,各方面的改进都非常大。而R600家族的体系架构在一定程度上可以看作是延续自Xenos。
但是ATI在2006年7月24被AMD收购以及它之前的研发精力不足,直接影响了R600家族产品的开发受到很大影响。最后导致没有统一架构设计经验的NVIDIA在2006年11月8日成功发布了G80核心的GeForce 8800 GTX显卡,巨大的技术革新和性能提升,获得了用户的一致认同。

至今耳熟能详的G80架构GeForce 8800 GTX显卡
G80架构使用了多指令流多数据流MIMD结构标量流处理器,一共128个流处理器替代了原来分立的Vertex Shader和Pixel Shader,拥有当时最强的性能,当然G80拥有6.81亿个晶体管,是G71的2.5倍之多,显存方面384Bit显存位宽也充分保证了数据吞吐能力。在性能上GeForce 8800GTX显卡把3D图形处理器的性能又引领到一个前所未有的高度,这给对手承重的打击,ATI竟在半年之内拿不出一款足以抗衡G80核心的产品。NVIDIA凭借G80的革命性架构毫无悬念的夺取了3D性能的制高点。
直到2007年6月3日,AIT终结了长达7个月的等待时间,Radeon HD 2000家族终于发布。业内第一片DX10 GPU的头衔被G80抢了去,不过ATI这次也没有完全被NVIDIA牵着鼻子走。除了对DX10和统一着色架构的支持外,R600还加入了一些特有的功能。例如,独立于几何着色器(Geometry Shader)的专用曲面细分单元(tessellation),加入属于Direct X 10.1范畴的可编程AA功能等。
R600架构在最后的设计阶段,已经发现了明显的问题,那就是SIMD结构的流处理器在使用了VLIW之后,过分依赖指令系统和编译器的效率。如果说流处理器数量足够多,则可以在宏观上抑制这种性能下降,但是R600但是只有320个流处理器。

80nm工艺制造的Radeon HD 2900 XT显卡
并且受制于台积电的80纳米高速版(80HS)工艺,加之R600集成了大约7亿枚晶体管这个不小的数量,R600最后的工作频率在一味追求GFLOPS浮点吞吐量的前提下达到了740MHz,并且为512Bit显存通道配备多达16颗显存……以上各种因素影响最终让R600架构的高端代表产品Radeon HD 2900 XT的整张显卡提升到高达225W。
随着各大媒体对于Radeon HD 2900 XT评测的结束,我们看到了一个让人吃惊的事实。基于R600架构的Radeon HD 2900 XT产品没能够战胜NVIDIA的GeForce 8800GTX,甚至在有些领域大幅度落后于对手。这导致Radeon HD 2900 XT的定位只能针对NVIDAI的8800GTS 640MB显卡,售价自然也只能和对手的次高级显卡持平甚至略低。
现在回忆当时的场景,你甚至无法想象ATI设计出一款全新架构的GPU,又因为巨额亏损惨遭收购,最终这款GPU的性能还是无法对手的高端产品向抗衡。在R600设计完成并走上市场后,整个AMD的GPU设计团队非常沮丧。
RV670开始改进 绝境求生
● RV670开始改进 绝境求生
R600出现了严重的问题,如果以2003年ATI设计这颗GPU的思路来衡量这款产品,我们可以判断它已经失败,因为耗费巨大研发实力的顶级GPU无法和对手的顶级产品相提并论,更严重的是基于R600架构的其他中低端产品也受到了高端产品的影响,比如说中端2600XT也大幅度落后于8600GT,直至后期驱动改善才获得一定程度的性能提升。
现在AMD唯一剩下的,就是未来的开发计划,和一个没有因为失败而相互离弃的团队,这个团队由AMD著名的架构师Carrell Killerbrew带队,后来由来自于Beyond 3D的Dave Baumann负责接管。
RV670已经没有时间重新设计芯片,而且巨大的设计成本和GPU相对较短的生命历程,也让AMD放弃了这个决定,ATI只是在芯片的内部进行了一些细微的调整,加入了DirectX 10.1技术的支持,同时得益于AMD在半导体工艺方面的经验以及和TSMC方面的紧密合作,RV670正在悄然发生转变……

代号RV670的工艺改进版显卡
RV670的GPU微架构并没有任何大的改动,只是将内存控制器由512bit缩减到256bit,这样就带来了芯片内部线长的大幅度下降,同时GPU需要的显存数目也有很大减少,显卡整体制造成本下降。
RV670可以说是完封不动的工艺微缩,这样的做法我们认为主要是为了更快地把成熟产品做工艺提升后的微缩化产品推出市场。不过在技术特性上,RV670通过简单改进,实现了Direct3D 10.1、PCI Express 2.0 x16以及PowerPlay的支持,这些细节方面的改进最后成为了用户非常欣赏的产品亮点。
总体而言,新发布的代号RV670的Radeon HD 3000让我们看到了AMD的愿景和希望。2007年12月,Radeon HD 3870和Radeon HD 3850成功发布。RV670的卖点主要是R600相当的性能但是只需要R600一半功耗、UVD视频引擎、优化流式数据运算、灵活的多GPU交火平台、完整的PCIE 2.0方案等等。
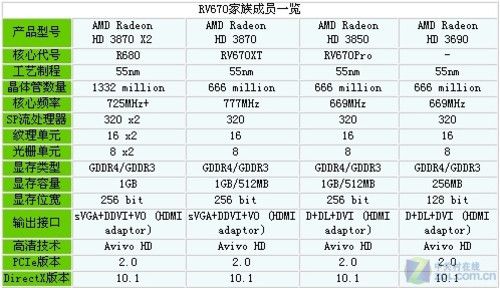
RV670芯片衍生出的高端显卡
RV670的发布,让AMD已经跌落到谷底的市场占有率出现了一定程度的回升,同时AMD也发现了R600架构一个重要的特性,那就是可以在功率得以控制的前提下迅速扩张,同时不断换用新工艺来降低功耗。这种特性是MIMD结构的流处理器所不具备的,这是SIMD架构常年以来的重要特色之一。沿着这条发展道路,AMD逐渐找到了突破口。RV670让我们看到了改进的力量,而AMD随后设计出的几代GPU产品,则让我们看到SIMD结构Shader巨大的扩张能力。
GT200体现NVIDIA变化方向
● GT200体现NVIDIA变化方向
在2005年,ATI和NVIDIA都面临这样的情况:造一颗最快的GPU,并提供稳定的驱动程序,那么就可以赢得市场。过去几年中,ATI一直是这么干的。但是在公司内部,有一些人认为是时候改变了。在很多方面ATI和NVIDIA都面临不同的挑战,NVIDIA从之前激进的工艺更新策略中汲取了教训,GT200很有可能仍然采用老的,更成熟的工艺,因此导致GT200的面积很大。

从R300到RV770的芯片面积变化对比
如上图,GT200面积的面积可以说是前所未有。代号GT200的新一代DX10芯片是NVIDIA作为08年暑期攻势的重点产品,和G92只是G80的改进版不同的是,GT200是真正在体系架构上进行了革新的产品,处理单元规模、内存配方面都有了不同程度的提升。
代号GT200的GeForce GTX 280是NVIDIA基于第二代统一着色器及计算架构的第一款产品,架构归属于为G100,在性能上相对上一代的产品(G80)来说快大约50%到100%。NVIDIA的旗舰GeForce GTX 280集成14亿晶体管电路,拥有240颗流处理器,配备了1GB GDDR3显存,采用了512-bit位宽,显存带宽高达141.7GB/s,成熟的65nm技术让GT200虽然庞大,但是功耗和发热都处于可控范围。
GT200晶体管集成度达到了14亿,而依然使用着65nm的制造工艺,因为这种工艺可以非常稳定地生产这种大体积的芯片,改进工艺反而容易出现不可预料的问题。
同时NVIDIA在GT200芯片设计方面提出了Gaming Beyond和Computing Beyond口号,我们可以理解为这颗芯片在提供优秀的图形性能前提下,同样对GPU的运算能力做了大幅度优化。这是NVIDIA在提出CUDA方案后,首次如此强调GPU的通用计算能力,但是我们现在审视这款产品就会发现,GT200在通用计算方面的努力甚至牺牲了一部分图形性能。

看似无人可挡的GT200产品留下巨大的市场空隙
GT200代表了当时图形业界大的性能,同时一些先进特性让人们对这款GPU刮目相看,包括更大的显存容量、更高的显存控制器位宽(NVIDIA第一次尝试512bit位宽)、更强的指令调度能力和流处理器周边资源配合,当然还有首次支持IEEE754规格的双精度浮点支持。虽然NVIDIA一直没有忘记改进每瓦特以及每平方毫米性能,但是GT200带来的功耗和面积问题,还是让它的图形处理执行效率相对于G92芯片有少许不足。
GT200的另一个问题是没有将芯片进行有效划分组合,这导致了GT200架构没有中低端产品。只是使用了Harvesting(屏蔽功能单元)的方式制造出了GTX260和GTX275等产品。这些产品的价格直到今天还在1000元人民币以上阶段徘徊,无法真正触及消费级市场。而消费者喜闻乐见的500-1000元显卡市场,还是由G80的衍生产品G92和GT210/220/240所控制,很多用户已经对这种市场划分方式感到索然无味。
RV770的策略与成功
● RV770的策略与成功
“让NVIDIA取得性能王座,让NVIDIA获得光环效应,我们要做的是设计在$200-$300价格段最好的GPU。”这句话出自RV770的首席设计师Carrell Killerbrew之口。在2005年夏,ATI决定瞄准性能级市场,而非狂热级市场来设计GPU。你可以认为性能级市场正是2002年R300竞争的市场。当然你更难以想象ATI在一念之间放弃了顶级GPU产品的设计,转而为用户设计一颗使用体验更好的芯片。

如今Carrell Killerbrew先生在AMD的6屏技术展示台前
AMD在R600丢掉了GPU性能王座,AMD最大的芯片不能和NVIDIA竞争,其后一年,AMD的营收和市场占有率都不断下降。而与此同时,Carrell仍然不停的让AMD内部每个人都信服RV770的设计走了一条正确的道路,他的论调在当时听起来就像是一个疯子说的一样。
事实上AMD在2005年已经感受到了功耗对于整个GPU设计的影响,所以较小的芯片战略已经在公司内部获得认同,整个RV770设计花了大约三年时间。这意味着当我们讨论R600的失败时,那帮工程师正在设计RV770并对此持乐观态度。当然,这很艰难,ATI因为R600完全丢掉了性能王座。Carrell Killerbrew(AIT工程院院士、RV770首席架构师)以及RV770的团队高层和其他人要求整个团队忘记发生在R600上的事情,忘掉ATI丢掉性能王座这个事情,致力于做好RV770这颗关键的GPU芯片。
这对于AMD是一个极度冒险的决定,因为一旦GPU设计定位降低之后,可能生产出性能较差的GPU产品,同时自己在高端市场完全没有控制力,这样的设计有可能重蹈R600失败的覆辙。要知道出于大幅亏损中的AMD,已经无力一次次承受这样的挫折……

芯片规模意味着AMD主动让出最高端的性能王位
RV770首先决定使用新工艺,AMD在RV670上已经试水了这种做法,效果一般。不过这并非策略问题,RV670平庸的销量是因为时间上来不及,继承了R600满身的BUG,RV770可不会如此,它是一个健全人。
放弃最大的芯片并不意味着放弃性能。RV770成功的修复了R600上臭名昭著的ROP bug,现在能获得比较正常的抗锯齿性能了。但仅这样这是不够的,为了取得优势,RV770最初的性能目标是1.5倍于R600。Carrell Killerbrew和他的团队评估后,把这个数字提升到了2.5——你没有看错,Carrell Killerbrew和他的团队要把两颗半R600塞进一颗比R600还要小的芯片里面。
前面我们说过,R600架构虽然效率并非最高,但它的规模是非常容易扩充的。现在,终于到了使用这个技能的时候了。R600和RV670都具备4个渲染核心,总共320个流处理器。而在RV770上,AMD把这两个数字分别扩大到了10和800,整整2.5倍的运算能力提升。扩充后的RV770已经拥有了1TFLOPS以上的运算能力。
RV770运算资源的大幅度扩充带来Shader单元的性能提升,但是让NVIDIA更没有想到的是ATI潜心研究改进了R600以来GPU的后端设计,主要是RBE(Render Back-End)单元,也就是NVIDIA所称的ROP单元。RBE单元主要用来实现多重采样和抗锯齿以提高画质或者降低高画质下GPU的性能衰减。
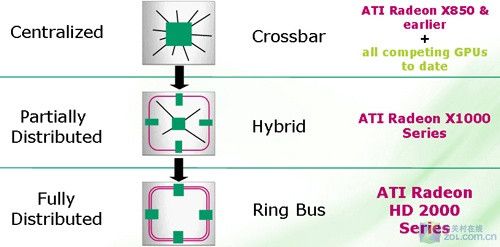
最初ATI认为先进的R600 Ringbus环形内存控制器总线被舍弃
RV770另一个值得称道的地方在于它彻底摒弃了一直处于争议的R600 Ringbus环形内存控制器总线,使用AMD擅长的Crossbar总线。Ringbus最大的优势在于可以用最少的晶体管来实现最大的带宽,但是Ringbus的代价是极大地整体延迟和粗糙的数据流动管理。业界公认的最快的互联方式只有Crossbar,NVIDIA虽然承受着高集成度带来的苦恼,但一直坚持使用Crossbar。
AMD的赌注与HD4850的改变
● AMD的赌注与HD4850的改变
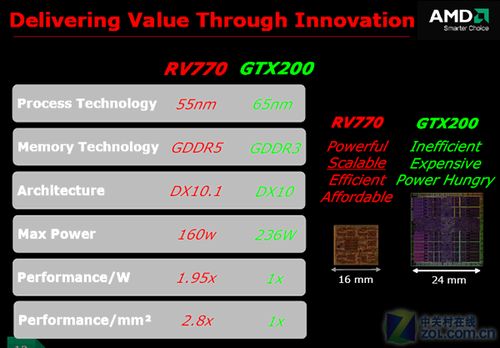
为了实现规模扩充同时控制芯片大小的目标,Carrell把赌注全部压在了2项新技术上:TSMC 55nm CMP工艺,和三星GDDR5显存。
R520和R600延期的惨痛教训表明,全新的工艺好处和几乎bug一样多,但是跨代的工艺制程进步可以让同样的芯片面积缩小40%,所以AMD毫不犹豫的使用了TSMC最新的55nm工艺,这是一场赌博。如果TSMC 55nm CMP不能按时到位,那RV770就是第二个R600。幸运的是,在RV670上,AMD已经尝试过了55nm工艺制程,现在虽然麻烦不少,但已经不是无法克服了。相对的,NV完全沉浸在G80以落后半代的工艺击败R600的喜悦中,不愿意给新产品冒险,GT200仍然使用的是保守的65nm工艺。仗未开打,AMD已经先声夺人。
RV770与GT200的对决让人充满忧虑
Carrell Killerbrew的第二个赌注就是GDDR5显存。R600为了512bit内存总线付出了巨大的晶体管代价,在RV770上,Carrell Killerbrew决定把内存总线缩减为256bit。这又是一个惊人的决定,你有见过产品越做越回去的吗?显然,256bit的位宽无法提供足够的显存带宽来达成RV770的性能目标。于是AMD找到了三星,问他们能不能合作提供一种比当时市面上所有显存快两倍的显存。
请记住,那是在2005年,当时甚至连这种新的显存技术的原型都没有,GDDR5的规范还没有最终确定。没有测试设备,没有界面设计,什么都没有。只知道GDDR5可以提供GDDR3两倍的带宽,这样就可以依靠256bit的显存位宽达成一个512bit显存位宽的目标。而这正是AMD想要的,所以RV770决定采用GDDR5。

RV770的命运和GDDR5紧紧连在一起
如果GDDR5不能在3年内准备好并投入生产上市,AMD将面临既没有高端GPU,也没有性能级GPU的窘境。如果GDDR5工作正常,那么意味着RV770能够成功,并且从另一方面来讲,这是NVIDIA所不具备的。RV770许配给了GDDR5,没有其他选择了。很明显,AMD当初其实是在赌博,一个双重的赌博,只有两方面都胜出才能获胜的双重赌博。55nm或者GDDR5任何一个因素输掉,RV770的结局都将注定是惨败。
另一个值得关注的产品是性价比超高的Radeon HD 4850。这款产品最初是256MB显存,500MHz的核心频率,900MHz的显存频率。但是设计师Dave坚持认为4850需要512MB的GDDR3和625MHz的核心频率,以及933MHz的显存频率。

定位出色的Radeon HD4850显卡
来自于Beyond 3D的Dave Baumann在2008年二月变成了RV770的产品经理。他不但坚持这个规格,也使得工程师团队信服了这个规格并做了改变。Dave向工程师们论述为什么要改变规格以及市场需要怎样的规格。在讨论快结束时,他已经不需要说服他们了。板卡和ASIC团队拥护这样的改变。
这种改进让代号RV770Pro的Radeon HD 4850在199美元的市场上找不到瞬间对手,因为它的性能过于出色,市场占据能力极强,所以NVIDIA GeForce 9800 GTX价格突然暴降,以便维持竞争力,但是即使如此也不够。如果没有Dave Baumann这样的改变,HD 4850不能对NV的GeForce 9800 GTX施加如此大的压力,它的价格也不会降得这么快。在这场较量中AMD用自己的努力,将消费者推向了最终的胜利。
RV870的设计思路和诞生背景
● RV870的设计思路和诞生背景
将R600的流处理器数目翻2.5倍,其他单元做进一步优化,AMD造就了成功的RV770,那RV770的规模还能否继续放大?放大后发热和功耗是否能够控制?是冒险尝试新工艺还是使用稳定的55nm工艺制造……在RV770诞生之后,图形业界对于AMD的下一款产品充满了期待。NVIDIA也计划在G92的基础上再度推出GT2X0等中低端芯片规格以抢占市场,当然AMD没有忘记,单卡单芯性能最强的仍然是GTX285,而并非自己的产品。
在这种紧要关头,AMD下一代旗舰——RV870的规格备受瞩目,它肩上的责任也异常重大,首先AMD寄希望于这款核心能够完全扭转高端市场的战局,击败后的GTX280;同时AMD希望能够通过RV870核心衍生出纷繁复杂的产品线,这样就能进一步加大市场占有率。
当然我们所期待的RV870,并不是此时开始设计,按照GPU的设计周期和最后的资料推断,2006年AMD在内部已经开始了对RV870芯片的讨论,它起初被命名为“Evergreen”。
在2007年秋天,对“Evergreen”将来具体会什么样,ATI已经有了粗略的轮廓。ATI对DirectX 11和微软在Win7方面的计划已经有相当了解,虽然不知道GPU具体什么时间发布,但他们知道应该什么时间准备好。这将是又一轮的市场增长点,必须根据这个增长点调整产品发布策略。“Evergreen”必须在2009年第3季度前准备好。
2007年8月至11月期间,AMD遭遇到市场方面的巨大压力,R600几乎失败,RV770的小芯片战略更得不到公司上下的支持,但Carrell Killerbrew还是非常自信地劝说所有开发团队的成员,让他们相信未来能够成功。果然RV770获得了市场的好评,但是AMD后来对RV870芯片已经产生了分歧。Rick Bergman(AMD绘图部门总经理)认为AMD这次应该出其不意地将RV870设计为大芯片,起码在芯片面积方面和NVIDIA的GT200b相当,但是Carrell Killerbrew还是坚持小芯片战略。
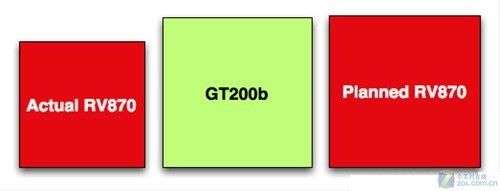
对于RV870的芯片面积,AMD举棋不定
在ATI公司里,有一份称之为《产品必备特性》的文件,简称为PRS。这起初是一个大文本文件,后用Word写成。这是一份AMD内部的绝密文档,它对芯片设计的优先级做出严格规定,高优先级的特性绝不能取消,低优先级的特性则可以忽略。但是关于RV870设计方向的最后讨论结果,AMD内部竟然没有达成一致,也就是说PRS文档上迟迟没有限定芯片面积。
2008年2月,台积电开始对AMD发出种种暗示:关于40nm制程的成本,AMD不要过于兴奋。AMD先前可能还有点乐观情绪,但从台积电返回的工程师说,RV870的制造成本将会非常昂贵,并建议重新考虑芯片架构。
在包括Carrell在内的众多员工经历了诸多艰辛工作和牺牲后,ATI将边长为22mm的RV870削减成大约18mm×18mm的芯片。其中被牺牲的包括负责芯片间通讯的“Sideport”模块和其他一些特性。
此时台积电的工艺已经越来越完备,AMD也把RV870的芯片规模进一步缩小,已经掌握了市场主动权和研发节奏的AMD首先在2009年初使用一款规模较小的RV740核心试水40nm工艺。作为AMD的首款40nm工艺图形核心,RV740将配备640个流处理器、32个纹理单元、16个光栅处理单元,位宽128-bit,标配512MB GDDR5显存,频率800MHz(等效3200MHz),可以弥补显存减半造成的带宽损失,同时浮点计算能力大约900GFlops。

AMD首片40nm晶圆
这次工艺试水获得了成功,不但为RV870使用40nm工艺铺平了道路,RV740这颗投石问路的芯片也成为“100美元内速度最快的芯片”。
RV870芯片概况与策略
● RV870芯片概况与策略
在所有铺垫工作完成之后,2009年09月23日,AMD为我们带来了基于DirectX 11的Radeon HD5870显卡。它采用第二代40nm工艺制造、搭载第四代GDDR5显存、拥有1600个流处理器、Eyeinfinty多屏显示技术、超低待机功耗等。最为关键的是Radeon HD5870满足了DirectX 11的一切设计要求,同时取得了对NVIDIA上一代顶级单卡GeforceGTX285的全面领先。无论是技术、规格还是性能,AMD用数据说话证明了自己再一次登上GPU王座。
RV870的成功在于多个方面,首先它率先支持了微软的DirectX 11硬件要求,这是NVIDIA当时的产品无法触及的。同时从性能角度讲,自从Radeon 1900XT在Geforce 8800GTX的打压下失去性能皇冠后,Radeon HD5870再次夺回了顶级显卡的王位。更重要的是,AMD在R300之后首次取得了时间、性能、规格上的三重领先。现在,AMD最大的芯片比NV最大的芯片更快。不仅如此,它还比NV最大的芯片要小,而且更便宜。
在2009年12月下旬,台积电宣布TSMC 40nm工艺良率已达到稳定,这更给AMD的Radeon HD5000系列产品打了一针强心剂,HD5000系列产品的供应量随之得到增长。

Radeon HD5000系列产品带来了性能的大幅度增长
下面就让我们来预览一些AMD的Radeon HD5870产品的重要特性:
·第一款支持DX11的GPU,微软的所有要求AMD都非常精准地完成;
·第一款制程进入40nm线宽的GPU,晶体管数目突破21亿;
·第一款浮点运算能力超过2TeraFlops的GPU,RV770是当时业界第一款超越1TFLOPS大关的GPU;
·第一款具备民用级别多屏幕显示能力的GPU,实现3屏甚至6屏显示不再需要代价高昂的专业设备。

霸气十足的Radeon HD5870 Eyefinity 6屏输出显卡
回顾Radeon HD 2000到HD5000系列产品的发展历程,我们首先把架构扩张的头等功记在SIMD结构的流处理器身上。使用了VLIW技术的SIMD结构流处理器以较小的晶体管消耗获得了强大的规模效应。同时虽然这种结构在效率上明显输给MIMD结构,但是它在遇到全4D指令或者大量的4D指令时,可以爆发出澎湃的指令吞吐量,而目前的很多游戏中还是大量掺杂着4D指令,这为SIMD结构的流处理器性能发挥奠定了基础。
所以当我们回顾GPU在同一渲染时代的发展历程时,我们不得不把这种较为传统的SIMD结构流处理器放在比较重要的位置来思考。NVIDIA一次次改进架构却难以换来大幅度的性能提升,AMD不断堆砌流处理器数量,甚至减少了每个流处理器周边资源的配置,还是保证了GPU的快速向前;不但如此还有功耗问题,GT200架构开始,NVIDIA已经不得不把功耗作为一个很重要的参考因素来设计GPU,而AMD则表现地轻松很多,典型例子就是两款性能不相上下的产品——GTX260+和HD5770,基于RV840的HD5770在提供了比肩GTX260+的性能前提下,消耗的电力约为对手的1/2,这就是技术进步的重要体现。
除了规模上的扩张,RV870还竭力弥补了R600架构之前遗憾。过去,由于过分注重成本,从R600开始AMD家族的通用运算能力就落后对手不少。AMD在RV870上着重改进了这一点,新加入的LDS(Local Data Share)有效提升了存储性能,改善了流处理器的执行效率。RV870不但支持微软DirectCompute和苹果OpenCL通用计算平台,还重新优化了数据共享结构,提供了完整的多级缓存供流计算使用,并且优化了访存能力。抢占式多线程虽然在技术层面略逊于Fermi的多级多分配并行多线程设计,但是就技术的标准来讲,RV870与对手站到了同一起跑线上。
Fermi架构的困惑
● Fermi架构的困惑
RV870发布之后一周后,NVIDIA仓促宣布了下一代DX11产品——Fermi的规格。Fermi具备512个标量流处理器,384bit GDDR5内存界面,晶体管数量达到创纪录的32亿个。但是直到2010年3月末,Fermi才得以在媒体上和广大用户见面,Fermi相比原定的期限足足晚了半年才出现。
如今我们对Fermi的性能已经了如指掌,在Fermi发布之前,很多用户对它的期望值很高,希望它能在大部分应用中大幅度领先于HD5870,毕竟两者的晶体管数量相差将近50%,发热和耗电也有巨大差异。但是在Fermi发布后,我们看到除了DirectX 11游戏中的Tessellation曲面细分特性方面Fermi有惊人表现,在其他领域Fermi只能用平常来形容。

Fermi架构示意图
其实Fermi架构的困惑主要集中在3个问题上,首先是图形处理与通用计算的冲突没有得到化解,导致面向并行计算领域的Fermi在很多图形处理中吃亏。图形业界普遍认为从DirectX10统一渲染架构开始,Shader运算能力强劲的GPU在图形运算方面也会表现优秀,但是这种愿望没有实现。
因为目前大部分的游戏是从PS3或者XBOX主机上迁移而来的,为了降低开发难度和节约成本,大多数游戏厂商会用一套源代码通吃整个PC和家用级平台。这些游戏虽然打着DirectX10甚至是DirectX 11的封装,但还是含有太多的DirectX9编程烙印,并不复杂的Shader效果背后,实际上是程序指令中的1D指令数量并不多,指令相关和分支嵌套等数量更为有限。这导致MIMD结构的流处理器无法发挥最佳效率,而传统的SIMD架构反而能够更好适应曾今的编程环境。
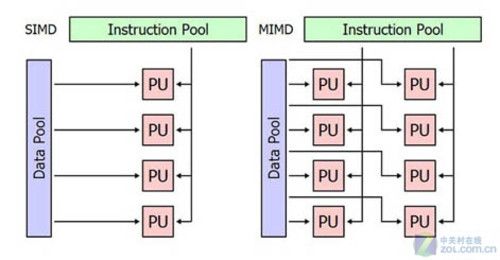
SIMD和MIMD架构的对比
其次是Fermi架构的TMU资源发生了变化,这导致Fermi架构GTX470/480的纹理填充率低下,甚至还不如曾今的王者GTX285高,更别提和HD5870相提并论了。有两种观点来解释NVIDIA此次的设计,第一种认为NVIDIA已经没有足够的晶体管来做TMU部分了,所以Fermi是64个TA + 256个TF的1:4非对称设计,这种设计在G80上曾今出现过,当时比例为1:2,但是在G92又被改为1:1,因为非对称的TA/TF资源在运行大部分图形运算时,会对GPU全局速度产生不容忽视的影响。
另一种观点认为DirectX10引入了一种叫直接像素纹理的技术,如果未来的图形编程能遵循这项技术,则输出的像素直接构成材质,没有纹理和混合等概念了,这样GPU中的TMU和ROP等单元都将消失,Shader承担绝大部分图形运算,Fermi很可能是在下这个赌注,因为Fermi的Shader运算性能很强劲。
导致Fermi难产和功耗较大的另一个因素是芯片的栅氧层漏电情况加剧。RV870的内部互联极为密集,采用CMP可以更好的保障层间以及层面上的应力稳定性和可加工性。虽然NVIDIA的线密度和布局决定无需借助CMP进行处理,但也因为这些,NVIDIA不得不面对比ATI更加严重的接触性热电跃迁。

AMD GlobalFoundries的德累斯顿工厂内部
RV870系列多为重复单元,互联级别和走线长度都很大,这样层上的应力负担就会很大。这时候使用CMP可以减小层上以及层间的应力负担。NVIDIA没这问题,但是NVIDIA的布线触点很多,触电部分是最容易受热电子迁移导致的物质迁移影响的部分,所以必须想办法减少这部分所带来的影响。
简单来说栅氧层越薄,晶体管也会有更高的性能。按规律MOS管的栅氧层每一代都要变得略薄,90nm阶段,栅氧层厚度发展到了小于2nm。2nm以上的栅氧层可以看作理想的绝缘层,但是2nm以下就会出现明显的穿通泄漏现象,这个泄漏也是按指数形式增加的。栅氧层漏电的情况AMD和NVIDIA都在忍受,但是RV870的21亿个晶体管规模明显小于Fermi架构GF100的32亿个晶体管,所以宏观上漏电导致的发热也就更低。
R600芯片设计之初遇到的问题
● R600芯片设计之初遇到的问题
现在回忆R600芯片,你能发现那是AMD所经历的一次难得的失败。因为从技术角度讲,R600架构延续了上一代R520/R580顶点着色器和像素着色器分置的SIMD结构(准确地说顶点着色器在Geforce 6000系列中已经上升为MIMD结构),这样的延续带来的直接后果就是技术研发的投入变小,相因的AMD在后期遇到的问题也会少很多,而且这些问题都是可控的。同时SIMD的另一个优势就是扩张容易,并且模拟这种扩张带来的性能变化比较简单,这一点是NVIDIA所不具备的。NVIDIA设计出一套非常优秀的G80架构,却在未来的发展道路上遇到很多障碍。
我比较喜欢分析AMD的失败,因为这些失败造就了后来的成功,那就让我们一起了解R600到底有哪些具体的失误,它们有细节方面的,也有策略方面的。
首先是R600时代,存储器速度限制像一堵看不见的墙壁一样挡在了AMD的面前,R600架构遇到了“Memory Wall(存储墙)”。这也是任何高速运算设备设计时所必须要面临的问题。

红色线表示具备访问存储器能力的模块
Radeon HD 2900XT核心工作频率为750MHz,运算单元单个时钟周期的长度在1.5ns以下。而我们可怜的外部存储器(显存)还在以400MHz左右的速度工作,加上内存本身的定址延迟和传输过程中的路径延迟,延迟就会大得可怕。如果换算成GPU内部的时钟,就是数百个周期的数据等待延迟,这种延迟会让整个流水线都陷入停顿,对于高速运行的GPU来说是灾难性的。
最重要的一点是R600还不够疯狂,换而言之就是320个流处理器单元的规模还不够多。我们知道R600的US是分“1大4小”,即一个全功能SP单元和4个仅能执行乘加运算而无法执行连乘运算的部分功能SP。如果指令段能够有相当多的天然4D指令,那么R600/RV770都可以以几乎全功率的性能进行运算。
但是很遗憾,如果你要实现复杂的Shader效果,不可能完全禁锢与全4D指令中,复杂多变的指令才是关键。全4D可以说是DX9B甚至更早的时代才有的光景。从这个角度来说,AMD之所以将R600的US设计成这样,简单地说就是不够进步的表现。
但是不够进步,可以通过堆量来实现掩藏发生内存存取动作的目的,而R600在需要疯狂的时候却又显得保守,只有320个流处理器或者仅有64个SIMD簇的规模让他在底层吞吐上并没有占据太大优势。
测试数据表明在AMD最为擅长的5D浮点指令吞吐中,R600仅超越G80约为80%,虽然这个超越非常明显,但是理论中几乎没有5D单发射指令可供R600去执行。几个所谓的并行吞吐测试R600虽然赢了,但是幅度太小,串行执行则全盘皆输。
而在明显放大的RV770架构中,RV770在5D浮点指令吞吐中领先对手GTX260达到124%,也就是说RV770将流处理器数量扩充到800个之后,已经达到了对手无法触及的5D理论吞吐量。同时情况出现了一些变化,NVIDIA长时间把守的串行指令执行测试中,RV770已经有少量超越GT200架构的表现,这是一个可喜的改变。

R600到R800 5D浮点指令吞吐测试对比
上图的测试数据来自著名的PCINLIFE网站,我们从该网站的几篇评测里凑齐了这项测试的数据,我想让数据来告诉读者,运算器堆砌带来的暴力吞吐能力是非常可怕的。
到了RV870时代,1600个流处理器的规模,已经让SIMD结构GPU不再低人一等,这时的5D浮点指令吞吐测试中,RV870已经领先GTX285将近229%,除了串行浮点MAD测试中输给了GTX285,其他底层指令吞吐测试全部翻盘。
RV770和RV870架构追求不断改进
● RV770和RV870架构追求不断改进
现在的AMD,最大的追求就是在尽可能保证小尺寸核心的基础上,提供尽可能多的性能。或者这话应该换一种方式说——堆垛晶体管的临界点,出现在增加晶体管所导致的性能增加出现拐点的那一刻。当堆垛晶体管所能够换来的性能增幅明显下降的时候,就停止堆垛晶体管。
疯狂的ALU运算器规模堆砌,让NVIDIA毫无招架之力,同时坚持以效率致胜的MIMD结构流处理器长期无法摆脱晶体管占用量大的烦恼,运算器规模无法快速增长。Fermi架构完全放弃了一味追求吞吐的架构设计方向,这一点在通用计算或者说复杂的Shader领域值得肯定,但是遇到传统编程方式的图形运算,还是因为架构过于超前显得适应性不足。
RV770可以说是AMD化腐朽为神奇的力作,较之R600,RV770不仅将公共汽车一般缓慢的Ringbus换成了高速直连的Crossbar,而且还追加了大量的资源,比如为16个VLIW CORE配置了16K的Local Data Share,同时将原有的Global Data Share容量翻倍到了16K,在此基础上,还将VLIW CORE规模整体放大到了R600的250%(320个提升到800个),另外,在后端配置的RBE单元以及更加完善的TA/TF也促成了RV770的脱胎换骨。
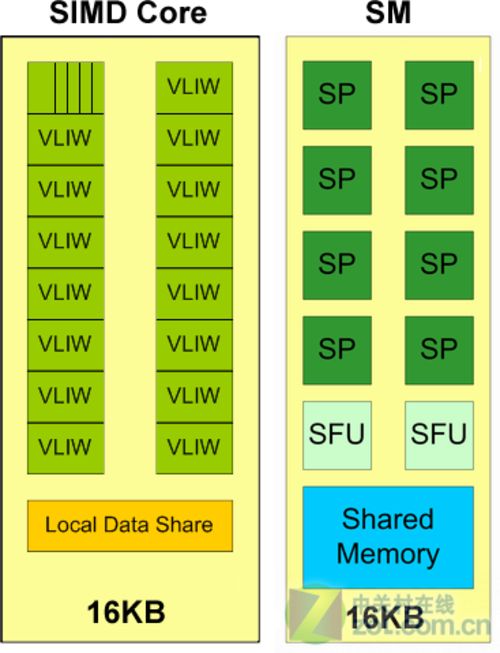
GT200和RV770运算单元架构
在扩展ALU资源的基础之上,AMD还在做着另外一件事,那就是尽一切可能逐步优化较为古老和低效的SIMD结构。在RV7中对LDS的空间直接读写操作管理等改进就是这类努力地开始。这导致了R600和R700在Shader Program执行方面有很大差别。R600的Shader Program是Vertical Mode(5D)+Horizontal Mode(16x5D)的混合模式。而RV770是单纯的Vertical Mode(16x4D=64D & 16*1D=16D,即64D+16D)。
简单的说,RV770更加趋紧于NV50 Shader Unit的执行方式,而R600则相去甚远。总的来说,NV更加趋紧于使用基于硬件调度器的Superscalar方式来开发ILP,而AMD更加趋紧于基于软件编译器调度的VLIW方式来开发ILP。

AMD RV870芯片显微照片与功能分析
到了RV870架构,AMD控制甚至紧缩资源,然后靠制程来拼规模,并最终让SIMD尽可能接近通过暴力吞吐掩盖延迟的最理想结局。然后就出现了我们现在看到的拥有1600个流处理器,体积却依然小于Fermi架构GF100的RadeonHD5870显卡。
回过头再去思考这条简单而又粗暴的发展路线,你不得不承认AMD在绝境中拾起R600架构并将其不断改变,最终在3年后重返GPU最高性能王座。
Fermi未来的性能亮点与优势
● Fermi未来的性能亮点与优势
Fermi架构不能说不优秀,因为它的设计方向已经发生了巨大转变,同时它将GPU定义为大规模并行处理器,说明Fermi架构在面对复杂指令时能够表现出非常强劲的处理能力,而我们在针对Fermi架构目前的测试中,确实发现了一些问题值得探讨。这些问题的特点非常明显:如果解决好,它们将成为Fermi架构发挥优势的重要筹码;如果解决不好,Fermi架构在日后的表现将会快速增长。
就目前Fermi架构GTX470/GTX480产品所表现出的各种特性来看,我认为有以下几把双刃剑悬在NVIDIA头上迟迟不能解决:
1、大容量可读写缓存架构对GPU性能和功耗的影响
Fermi有768KB的统一的L2缓存,可以支持所有的存取和纹理操作。L2缓存和所有的SM都想通。L2提供有效和高速的数据支持。有些算法不能在运行前就确定下来,像一些物理问题,光线跟踪,稀疏矩阵乘法,尤其需要缓存的支持。过滤器和转换器需要所有的SM都去读取相同数据的时候,缓存一样会有很大的帮助。

Intel利用晶体管睡眠技术分区管理SRAM缓存功耗
缓存的可读写性带来了很多问题,它包括缓存一致性协议,缓存的命中率等问题,这些问题每年要消耗Intel和AMD等CPU制造公司很多研发力量,而费米的诞生,只能把NVIDIA也牵连进来。同时缓存所面临的另外一个问题就是功耗难以控制,SRAM电路不像其他逻辑电路设计,一旦通电就会全速运行功耗也达到最大值。目前Intel和AMD所使用的都是分块管理缓存,针对这一部分电路并没有非常好的功率控制方式。
Cache引入后,驱动就变得更加重要或者说是极端重要。首先,开发一种任何游戏几乎都能受益的全局优化算法对NVIDIA来说太难了,同时如果针对某个游戏优化,那就不可避免的会出现其他游戏不合口味的问题。Cache的引入是良好的开端,但我更希望这个开端由Intel来做。毕竟NVIDIA从未涉及过大容量全局缓存的开发工作,所以做这项工作还是不够稳妥的。
2、纹理单元配置的冒险性
基于全新DirectX 11技术的GTX 480在拥有前面两个介绍的引擎之后,对于诸如Tessellation曲面细分等技术的支持自然优异。但是对于传统GPU显示核心而言,最为基本的TA和TF资源也不能或缺。GF100核心每个SM单元内包含四个纹理单元,GTX 480共拥有4组GPC即16个SM单元,简单计算可知在GTX 480内共有64个Texture Units纹理单元,与GT200架构中的80个纹理单元相比似乎有所减少。

GF100架构的一个SM内部纹理单元配置
更为重要的是GF100的TA纹理寻址单元数量为64个,而TF纹理过滤单元则达到了256个,在G80架构中TA与TF之比为1:2,而后期改进的G92核心中NVIDIA出于无奈,将TA与TF之比恢复为1:1,若GF100的TA、TF数量的确为64/256,那么这个比例将达到前所未有的1:4。和传统的1:1配置相比,GF100的纹理定址能力明显减弱。拾取单元需要定址之后才能动作的,定址单元不够的情况下,在大多数3D应用中光有拾取是完全靠不住的。
但是NVIDIA坚持认为TA与TF单元的比率,是根据大量的模拟结果,由构架团队决定的,影响最终架构的有模拟结果,以及对未来发展趋势的预测,当然也外带情报,最终Fermi架构GF100芯片的纹理单元配置是取合适比例的结果。
回顾统一渲染架构,探寻SIMD极限
● 回顾统一渲染架构历程,探寻SIMD结构极限
AMD从R600核心开始,一直延续着上述理念设计GPU产品,R600身上有很多传统GPU的影子,其Stream Processing Units很像上代的Shader Units,它依然是传统的SIMD架构。这些SIMD架构的5D ALU使用VLIW技术,可以用一条指令完成多个对数值的计算。
由于内部的5个1D ALU共享同一个指令发射端口,因此宏观上R600应该算是SIMD(单指令多数据流)的5D矢量架构。但是R600内部的这5个ALU与传统GPU的ALU有所不同,它们是各自独立能够处理任意组合的1D/2D/3D/4D/5D指令,完美支持Co-issue(矢量指令和标量指令并行执行),因此微观上可以将其称为5D Superscalar超标量架构。
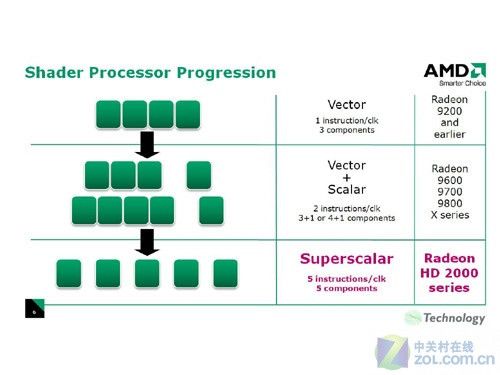
AMD的流处理器结构变化
SIMD虽然很大程度上缓解了标量指令执行效率低下的问题,但依然无法最大限度的发挥ALU运算能力,尤其是一旦遇上循环嵌套分支等情况,SIMD在矢量处理方面高效能的优势将会被损失殆尽。同时VLIW的效率依赖于指令系统和编译器的效率。SIMD加VLIW在通用计算上弱势的原因就在于打包发送和拆包过程。
NVIDIA从G80开始架构作了变化,把原来的4D着色单元彻底打散,流处理器不再针对矢量设计,而是统统改成了标量运算单元。每一个ALU都有自己的专属指令发射器,初代产品拥有128个这样的1D运算器,称之为流处理器。这些流处理器可以按照动态流控制智能的执行各种4D/3D/2D/1D指令,无论什么类型的指令执行效率都能接近于100%。
AMD所使用的SIMD结构流处理器,具有非常明显的优势就是执行全4D指令时简洁高效,对晶体管的需求量更小。而NVIDIA为了达到MIMD流处理器设计,消耗了太多晶体管资源,同时促使NVIDIA大量花费晶体管的还有庞大的线程仲裁机制、端口、缓存和寄存器等等周边资源。NVIDIA为了TLP(线程并行度)付出了太多的代价,而这一切代价,都是为了GPU能更好地运行在各种复杂环境下。
但是业界普通的共识是SIMD结构的流处理器设计能够有效降低晶体管使用量,特别是在已经设计好的架构中扩展流处理器数量的难度,比起MIMD结构要容易很多。对比R600和G80架构可知,4个1D标量ALU和1个4D矢量ALU 的理论运算能力是相当的,但是前者需要4个指令发射端和4个控制单元,而后者只需要1个,如此一来MIMD架构所占用的晶体管数将远大于SIMD架构。
当然RV870目前的状态虽然不错,但是下一代的R900架构已经很难延续这种简单的性能提升模式了,说到底还是回到了文章开始的问题。R600拥有令人难以置信的512bit显存位宽,以此引出的问题是芯片面积很大因为你不得不进行复杂的绕线(route)。据可靠消息,R600的内部互联线长达到19000公里,RV770到了27000公里,如果RV770不换掉ringbus环形内存总线,线长可能要超过40000公里,现在R800在AMD的全力改进下稳定在了36000公里。理论上基于IC设计层面,R800还可以继续扩展规模,但是实际操作中几乎已经不可能了。IC设计中,不是晶体管多内部互联线长就会过度,要看芯片具体结构,大量重复的单元才会导致线长急剧放大。

用于芯片制造的CMP化学机械研磨机
内部互联线长对芯片互联层数提出了极高要求,AMD一味增加GPU重复单元(流处理器)的做法,导致AMD手头已经没有继续上攻互联层的技术储备了,目前是9/14,既逻辑互联层为9,物理互联层为14。互联层越高,垂直互联越多,水平方向上的布局越松散,电磁和应力环境越好。但是互联层越高,垂直互联越复杂,空间电磁和应力环境越差,而且走线设计或者说布局也会成问题。互联层越高,核心面积就可以越小,但是两者并非线性关系,而且相应的设计难度也就越高。
另外一个困扰AMD的问题是要保证严格同步,如果未来的R900为了扩充流处理器数量真提升到3200SP而且维持现有工艺和布线状态以及电压不变的前提下,芯片内的信号延迟将从飞秒级提升到接近纳秒级。以现在的互联状态和布局,没有任何一家厂商能够控制这样的延迟水平。
据相关消息透露,AMD也会在今年晚些时候推出新一代的Radeon HD6000系列显卡(初步代号为R900),继续巩固过去半年来之不易的领先优势。目前关于R900的资料还非常少,最引人注目的变化是AMD的架构设计基础可能会从SIMD(单指令多数据)转向MIMD(多指令多数据),而这也是R900面临的最大风险之一。NVIDIA早就采用了MIMD结构了,并且在MIMD结构的流处理器中积累了深厚的经验。如今SIMD架构遇到瓶颈,AMD能否顺利过渡到MIMD,这也是未来一两年内显卡制高点争夺战的关键所在。
基本信息分析——Radeon HD2900 XT
● 每代顶级产品基本信息分析——Radeon HD2900 XT
在这个环节,我们使用了常用的GPU-Z软件和EVEREST系统信息检测软件来测试每代核心顶级显卡的基本信息,这样可以帮助各位用户更好的回顾和分析核心架构规模和这代产品的基本概况。首先登场的是R600架构的代表之作——Radeon HD2900 XT显卡。
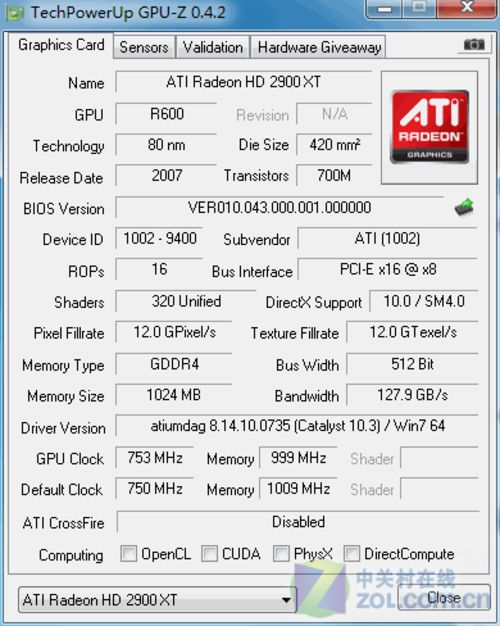
Radeon HD2900 XT显卡GPU-Z信息
在GPU-Z信息测试中,软件识别出了这款产品的基本情况,我们可以看到它使用了集成320个流处理器的,R600核心,较为传统的80nm工艺、7亿个晶体管。为了和对手的8800GTX相抗衡,这款产品使用了当时极高的核心频率,结果带来的后果是功耗和发热急剧增加,但是性能仍然无法和NVIDIA的高端旗舰竞争。
显存方面,R600使用了512位显存控制器以最大限度地增加外部显存带宽,但是同样带来了晶体管的耗费和成本与功耗的增加。更可惜的是当时的DDR4显存也没有及时发挥优势,最终靠着512位Ringbus总线,Radeon HD2900 XT显卡将带宽硬撑到127.9GB/s,虽然最大程度上换取了显存带宽的提升,但是由于架构劣势,这款显卡可以被认为是比较失败的产品之一。
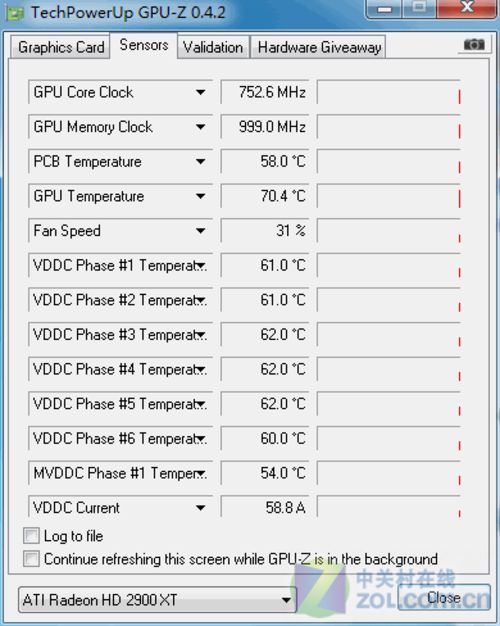
Radeon HD2900 XT显卡GPU-Z信息
在传感器页面,我们看到了这款显卡的传感器能够准确识别显卡的工作状态。我们用Furmark做了一个简单的3D负载,发现传感器对于温度的检测非常准确,GPU核心也支持频率自适应变化以降低功耗,速度监控非常细致。传感器的周详设计,是一款高端显卡所必备的特性之一。

Radeon HD2900 XT显卡 EVEREST信息
上图是EVEREST检测结果,我们首先选择“图形处理器”,但是由于软件版本限制没有检测到可用信息。我们换用“GPGPU”页面,得到了这款核心的通用计算能力。比较重要的几个和图形相关的参数包括:GPU核心频率:850MHz,显存总容量和剩余容量:1024MB/992MB。同时还有它的Warp粒度为每个Warp拥有64个线程。当然我们发现一个细节,AMD为了划分中高端市场,在RV840核心中砍掉了双精度运算能力,但是高端用户一定明白双精度运算在图形处理中是完全没有必要的。
基本信息分析——Radeon HD3870
● 每代顶级产品基本信息分析——Radeon HD3870
在这个环节,我们使用了常用的GPU-Z软件和EVEREST系统信息检测软件来测试每代核心顶级显卡的基本信息,这样可以帮助各位用户更好的回顾和分析核心架构规模和这代产品的基本概况。第二款登场的是改进于R600架构的RV770架构代表之作——Radeon HD3870显卡。
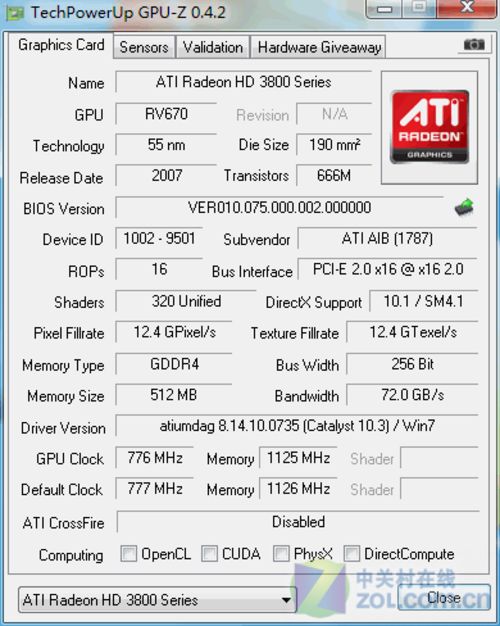
Radeon HD3870显卡GPU-Z信息
在GPU-Z信息测试中,软件识别出了这款产品的基本情况,我们可以看到它使用了集成320个流处理器的RV670核心,55nm工艺、6.66亿个晶体管。这款产品出自迪兰恒进之手,它使用非公版设计,使用了双层热管完全无风扇,但是频率还是能够坚持运行在公版标准。第一次看到这种散热方案出现在高端产品中,让我非常吃惊。
显存方面,RV670核心使用了256位显存控制器以减小芯片面积,降低芯片是生产成本和功耗,但是借助频率较高的DDR4显存最终显存带宽达到了72.0GB/s,这种设计能够媲美上代旗舰512bit的HD 2900XT显卡的带宽优势,足以为320个流处理器提供数据支持,同时找到了GPU性能与功耗的设计平衡。
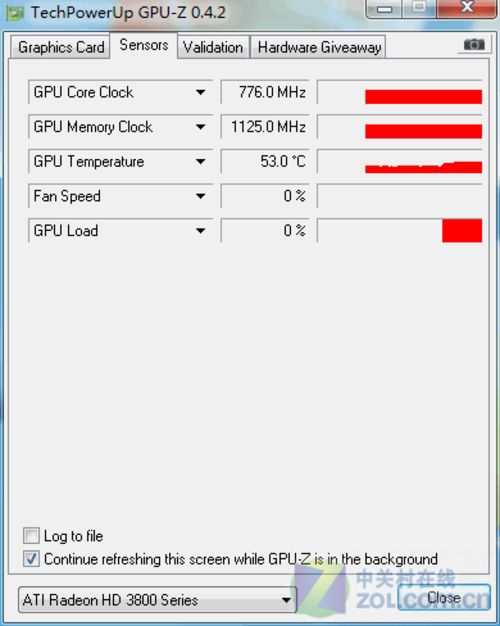
Radeon HD3870显卡GPU-Z信息
在传感器页面,我们看到了这款显卡的传感器能够准确识别显卡的工作状态。但遗憾的是这款显卡的传感器数量明显偏少,或者说能被GPU-Z识别的传感器数量偏少。但是温度和频率还是得以正常识别,无风扇4热管设计让这款迪兰恒进HD3870显卡在运行时可以给予用户最好的使用体验。
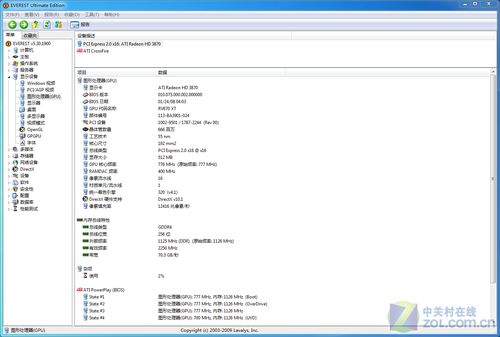
Radeon HD3870显卡 EVEREST信息
上图是EVEREST检测结果,我们选择“图形处理器”,EVEREST侦测到的结果基本与GPU-Z软件一致。相对于上代顶级显卡HD2900XT的技术特性也在检验中得到体现,就像我们上文所说,虽然是一些细节方面的不触碰核心架构的改进,但是它们在日后使用中为用户带来了更好的使用感受。
基本信息分析——Radeon HD4890
● 每代顶级产品基本信息分析——Radeon HD4890
在这个环节,我们使用了常用的GPU-Z软件和EVEREST系统信息检测软件来测试每代核心顶级显卡的基本信息,这样可以帮助各位用户更好的回顾和分析核心架构规模和这代产品的基本概况。第三款登场的是在架构方面做出第一次大幅度改进的RV770架构代表之作——Radeon HD4890显卡。它代表了AMD在55nm工艺方面最成熟的微架构设计,大幅度扩充了ALU运算器规模线程管理能力与周边资源增加,让这款显卡为后来的R800架构铺平了横向扩张的道路。
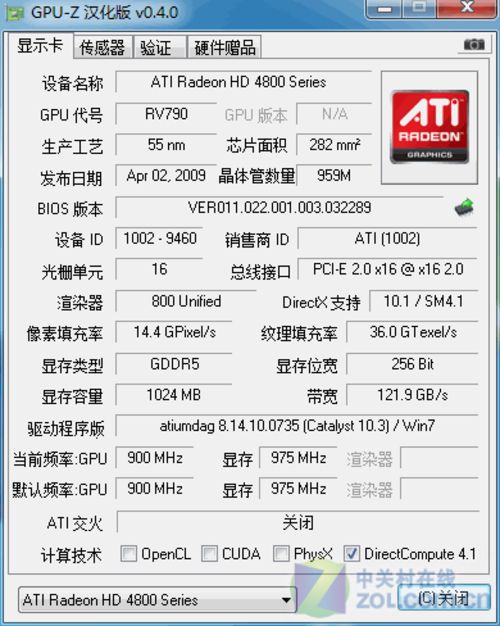
Radeon HD4890显卡GPU-Z信息
在GPU-Z信息测试中,软件识别出了这款产品的基本情况,我们可以看到它使用了集成800个流处理器的RV770核心,55nm工艺、9.59亿个晶体管。作为AMD官方超频版的显卡,HD4890的构架在RV770的基础上并未做出重大变化,虽然核心面积由原来的256mm2增加到282mm2,但是其核心晶体管数量仍然与Radeon HD 4870相同,为9.56亿个。
据业内人士透露,HD4890属于重新Tape Out的产物,即在RV790核心外围,新增加了Decap Ring(去耦环),可以有效降低信号噪音,可让其稳定运行的频率达到一个更高的值;另外一个重要的变化是:HD4890采用了TSMC(台积电)55nm工艺中价格最高的55GT,这也是为什么Radeon HD 4890的核心频率能达到这么高的原因之一。
显存方面,RV670核心使用了256位显存控制器以减小芯片面积,降低芯片是生产成本和功耗,但是借助频率极高的DDR5显存最终显存带宽达到121.9GB/s,这种设计相比第一代统一渲染架构旗舰512bit的HD 2900XT显卡,显得更为从容和稳健。
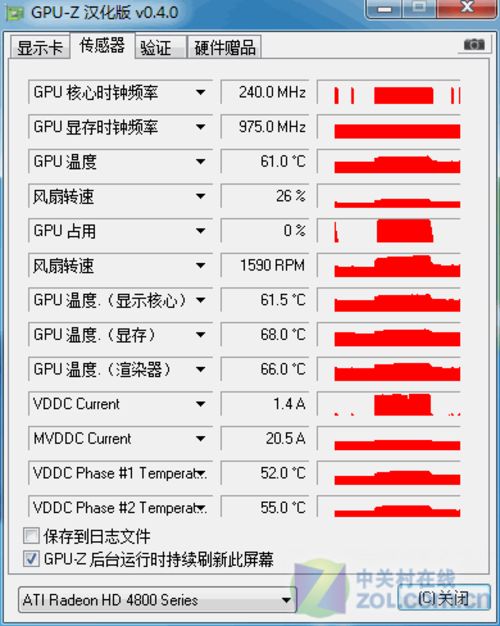
Radeon HD4890显卡GPU-Z信息
在传感器页面,我们看到了这款显卡的传感器能够准确识别显卡的工作状态。丰富的传感器数量能够准确描述这款显卡的运行状态,这是高端显卡所必须的特性。改良后的散热、供电以及1.5A的风扇电流,让这款显卡的温度在满载时也能有效控制。
Radeon HD3870显卡 EVEREST信息
上图是EVEREST检测结果,我们选择“图形处理器”,EVEREST侦测到的结果基本与GPU-Z软件一致。同时我们发现AMD在RV770核心中加入的Powerplay功耗控制技术,在这款公版显卡中得到了完美体现。也就是说在轻负载3D或者2D状态中,这款显卡的低功耗和静音特性能够有效体现。
基本信息分析——Radeon HD5870
● 每代顶级产品基本信息分析——Radeon HD5870
在这个环节,我们使用了常用的GPU-Z软件和EVEREST系统信息检测软件来测试每代核心顶级显卡的基本信息,这样可以帮助各位用户更好的回顾和分析核心架构规模和这代产品的基本概况。
最后一款登场的是在架构方面做出第一次大幅度改进的RV870架构代表之作——Radeon HD5870显卡。它代表了AMD在40nm工艺方面最成熟的微架构设计和AMD所有产品中最强的单卡单芯性能,特别是在性能功耗比方面表现优异。
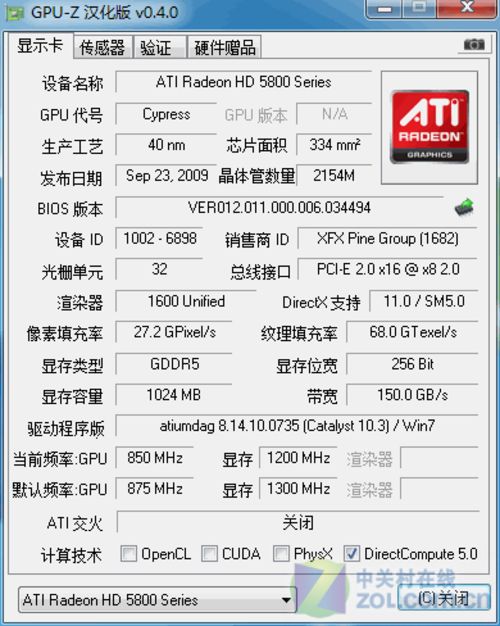
Radeon HD5870显卡GPU-Z信息
在GPU-Z信息测试中,软件识别出了这款产品的基本情况,我们可以看到它使用了集成1600个流处理器的R800核心(Cypress),40nm工艺、21.54亿个晶体管。本次测试的产品在频率方面默认做出了提升,但是为了测试结果更有对比性,我们还是将它还原为最初的公版频率。
显存方面,RV870核心使用了256位显存控制器以减小芯片面积,降低芯片是生产成本和功耗,但是借助频率极高的DDR5显存最终显存带宽达到150.0GB/s。同时借助于对DirectX 11的支持,这款显卡能够对DirectComputer计算接口提供支持,这为以后市场更大的GPU通用计算提供了基础。
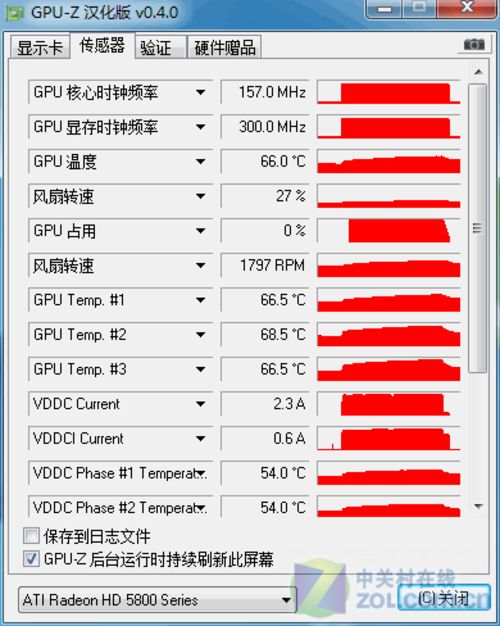
Radeon HD5870显卡GPU-Z信息
在传感器页面,我们看到了这款显卡的传感器能够准确识别显卡的工作状态。丰富的传感器数量能够准确描述这款显卡的运行状态,这是高端显卡所必须的特性。复杂的监控项目甚至在一屏无法显示。

Radeon HD5870显卡 EVEREST信息
上图是EVEREST检测结果,我们选择“图形处理器”,EVEREST侦测到的结果基本与GPU-Z软件一致。同时我们发现AMD在RV770核心中加入的Powerplay功耗控制技术在这代核心中还是有较好的继承。通过我们前文的分析可知,R800核心的功耗控制能力更为优秀。
性能测试的硬件、软件平台状况
性能测试的硬件、软件平台状况
● 测试系统硬件环境
性能测试使用的硬件平台由Intel Core i7-975 Extreme Edition、ASUS P6T Deluxe主板和2GB*3三通道DDR3-1600内存构成。细节及软件 环境设定见下表:
| 测 试 平 台 硬 件 | |
| 中央处理器 | Intel Core i7-975 Extreme Edition |
| (4核 / 超线程 / 133MHz*25 / 8MB共享缓存 ) | |
| 散热器 | Thermalright Ultra-120 eXtreme |
| (单个120mm*25mm风扇 / 1600RPM) | |
| 内存模组 | G.SKILL F3-12800CL9T-6GBNQ 2GB*3 |
| (SPD:1600 9-9-9-24-2T) | |
| 主板 | ASUS P6T Deluxe |
| (Intel X58 + ICH10R Chipset) | |
| 显示卡 | |
| AMD 产 品 | |
| Radeon HD 2600XT | |
| (RV630 / 512MB / 核心:800MHz / Shader:800MHz / 显存:2200MHz) | |
| Radeon HD 3850 | |
| (RV670 / 512MB / 核心:669MHz / Shader:668MHz / 显存:1400MHz) | |
| Radeon HD 4830 | |
| (RV770 / 512MB / 核心:575MHz / Shader:575MHz / 显存:1800MHz) | |
| Radeon HD 5770 | |
| (RV840 / 512MB / 核心:850MHz / Shader:850MHz / 显存:4800MHz) | |
| Radeon HD 5830 | |
| (RV870 / 512MB / 核心:800MHz / Shader:800MHz / 显存:4000MHz) | |
| Radeon HD 2900XT | |
| (R600 / 512MB / 核心:740MHz / Shader:740MHz / 显存:1650MHz) | |
| Radeon HD 3870 | |
| (RV670 / 512MB / 核心:776MHz / Shader:776MHz / 显存:2250MHz) | |
| Radeon HD 4890 | |
| (RV770 / 512MB / 核心:900MHz / Shader:900MHz / 显存:3900MHz) | |
| Radeon HD 5870 | |
| (RV870 / 1024MB / 核心:850MHz / Shader:850MHz / 显存:4800MHz) | |
| Radeon HD 5970 | |
| (RV870 / 2048MB / 核心:725MHz / Shader:725MHz / 显存:4000MHz) | |
| 硬盘 | Western Digital Caviar Blue |
| (640GB / 7200RPM / 16M缓存 / 50GB NTFS 系统 分区) | |
| 电源供应器 | AcBel R8 ATX-700CA-AB8FB |
| (ATX12V 2.0 / 700W) | |
| 显示器 | DELL UltraSharp 3008WFP |
| (30英寸LCD / 2560*1600分辨率) | |

G.SKILL F3-12800CL9T-6GBNQ

AcBel R8 ATX-700CA-AB8FB

Thermalright Ultra-120 eXtreme
我们的硬件评测使用的内存模组、电源供应器、CPU散热器均由COOLIFE玩家国度俱乐部提供,COOLIFE玩家国度俱乐部是华硕(ASUS)玩家国度官方店、英特尔(Intel)至尊地带旗舰店和芝奇(G.SKILL)北京旗舰店,同时也是康舒(AcBel)和利民(Thermalright)的北京总代理。
● 测试系统的软件环境
| 操 作 系 统 及 驱 动 | |
| 操作系统 | |
| Microsoft Windows 7 Ultimate RTM | |
| (中文版 / 版本号7600) | |
| 主板芯片组 驱动 |
Intel Chipset Device Software for Win7 |
| (WHQL / 版本号 9.1.1.1120) | |
| 显卡驱动 | |
| AMD Catalyst for Win7 | |
| (WHQL / 版本号 10.3) | |
| 桌面 环境 |
2560*1600_32bit 60Hz |
| 测 试 平 台 软 件 | |
| 3D合成 测试软件 |
3Dmark 06 |
| Futuremark / 版本号1.10 | |
| 3Dmark Vantage | |
| Futuremark / 版本号1.01 | |
| 其他综合测试项目 | Sisoft GPGPU着色器性能 单精度Shader型浮点 |
| Sisoft GPGPU着色器性能 双精度Shader型浮点 |
|
| 3Dmark Vantage 贴图填充率 | |
| 3Dmark Vantage 视差闭塞映射 | |
| 3Dmark Vantage GPU粒子模拟 | |
| 3Dmark 06 Shader Particles 3.0 | |
| Furmark Open GL 性能测试 | |
| Lightsmark 光照渲染测试 | |
| DirectX 10 SDK Cube Map GS | |
| DirectX 10 SDK Nbody Gravity | |
| 辅助测试软件 | Fraps |
| beepa / 版本号 3.0.3 | |
各类合成测试软件和直接测速软件都用得分来衡量性能,数值越高越好,以时间计算的几款测试软件则是用时越少越好。
DX9理论性能测试:3DMark 06
● DX9理论性能测试:3DMark 06
3Dmark 06作为上一代3DMark系列巅峰之作,所有测试都需要支持SM3.0的DirectX 9硬件,并且支持HDR特性,这款软件的最终得分里CPU性能占有不小的权重,因此它更适宜分析整个系统的3D加速能力。

历代芯片顶级显卡成绩对比:

历代芯片性能级显卡成绩对比:
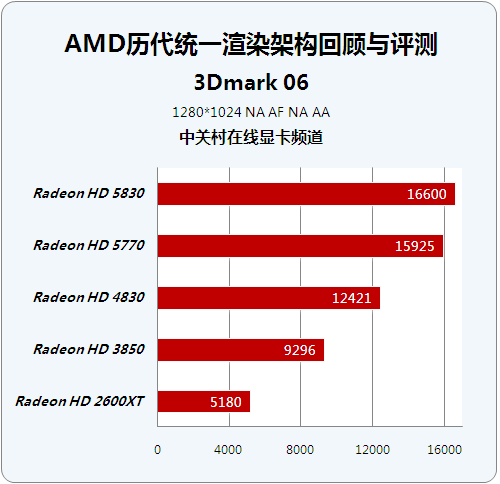
在代表DirectX 9时代的3Dmark06测试中,HD5870表现出了最高的效率,同时HD4890依靠绝对的频率优势,在这项测试中发挥出色。
在性能级显卡中,HD5830得分领先,但最耀眼的明星是目前价格在1000元左右的HD5770,毕竟RV840能以800个流处理器的规模取得接近RV870核心的成绩,是相当值得欣慰的。但是这从另外一个方面体现出HD5830的ROP单元规模不足。
DX10理论性能测试:3Dmark Vantage
● DX10理论性能测试:3Dmark Vantage
3DmarkVantage是Futuremark最新推出的一款显卡3D性能测试,该款软件仅支持DirectX 10系统及DirectX 10显卡。测试成绩主要由两个显卡测试和两个CPU测试构成,整个测试软件各家偏重整机性能。

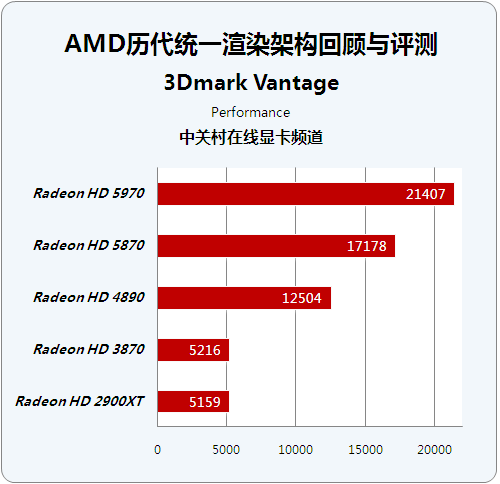
历代芯片顶级显卡成绩对比:
历代芯片性能级显卡成绩对比:
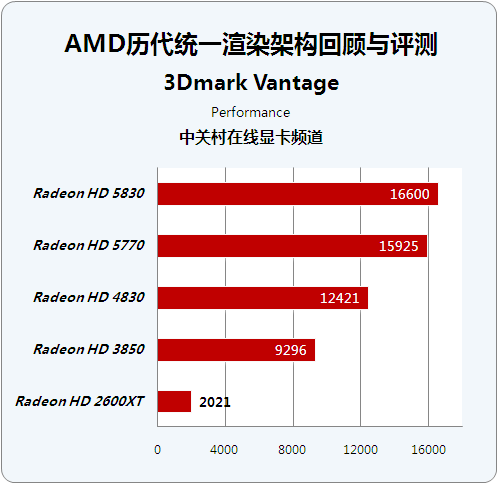
在代表GPU的DirectX 10图形能力的评测中,我们为了照顾HD2600XT的显存限制,使用了Performance模式进行测试。这项测试中GPU得分权重达到0.9,而更为严格的Extreme测试GPU权重达到0.95。
测试结果较好的体现了GPU的着色器性能增长,因为3Dmark Vantage正确的理解了DirectX 10的含义,将测试重点放在着色器Shader的性能方面,所以我们看到各代产品之间的差距越来越大,结合前文的分析,相信大家能够体会到架构变革带来的性能提升。
GPGPU着色器性能-单精度Shader
● Sisoft GPGPU着色器性能-单精度Shader型浮点
我们使用了SiSoftware Sandra 2010版软件来检测这款所搭载的GPU理论浮点吞吐量。这个测试可以检测GPU的Shader单元运算能力,虽然它是面向通用计算程序设计的,但是在一些较为高端的对Shader负载较重的游戏中,Shader单元运算能力强的显卡可以有更强劲的发挥和更小的性能衰减。
我们使用的版本号是16.36.2010,测试方法是进入程序后,选择界面中的Benchmark工具,然后选择GPGPU Processing项目。
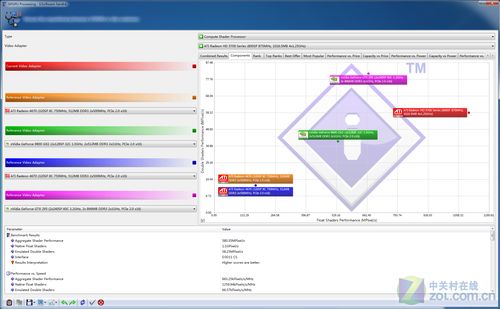
历代芯片顶级显卡成绩对比:

历代芯片性能级显卡成绩对比:

需要注意的是这里检测的仅是理论浮点值,实际运算环境中将会包含大量跳转嵌套分支等指令,只有运算器组织得当的GPU,才能有效避免理论值的大幅度衰减。测试的编程接口可以实现与GPU的自适应变化,所以测试结果无论是对于NVIDIA还是AMD都可以体现出最佳性能。
在这项测试中,我们看到流处理器数量或者说芯片规模的增长,能够带来单精度Shader型浮点运算效率的线性提升,同时HD2900XT和HD5970之间的差异巨大。我们发现这个测试只能支持单GPU,这对于HD5970这样的单卡双芯显卡是非常不公平的,所以我们手动对HD5970的成绩加倍,以加入另一个GPU的浮点吞吐性能。
GPGPU着色器性能-双精度Shader
● Sisoft GPGPU着色器性能-双精度Shader型浮点
在双精度测试中,我们同样使用SiSoftware Sandra 2010版软件来检测显卡所搭载的GPU理论浮点吞吐量。对于没有双精度单元或者不支持双精度运算的GPU,则使用单精度模拟的方式来测试它的双精度Shader型浮点性能,因此一些低端显卡或HD3000系列之前的显卡双精度性能不可能为零。
我们使用的版本号是16.36.2010,测试方法是进入程序后,选择界面中的Benchmark工具,然后选择GPGPU Processing项目。
历代芯片顶级显卡成绩对比:

历代芯片性能级显卡成绩对比:

需要注意的是双精度检测的同样是理论浮点值,实际运算环境中将会包含大量跳转嵌套分支等指令,只有运算器组织得当的GPU,才能有效避免理论值的大幅度衰减。并且双精度运算在目前的图形计算中是没有任何用处的,所以被取消的双精度单元GPU不会在游戏中出现任何性能下降。
这项测试的结果出乎我们意料,因为所有的显卡都没有体现出实际应该拥有的理论值,或者说和理论的双精度Shader型浮点值相差甚远。我们怀疑是Sisoftware Sandra的版本问题,也就是说这款软件还不能对GPU的双精度Shader型浮点性能进行准确测试。
3Dmark Vantage 贴图填充率测试
● 3Dmark Vantage 贴图填充率测试
3DMark Vantage一共提供了6个特性测试项目,与前面的显卡、处理器测试不同,预设等级不会对特性测试造成影响,而特性测试的得分也不会被加入到3DMark总分的考察范围内。
本次我们选取了第一项贴图填充率测试,来测试不同时代统一渲染架构的变化。

历代芯片顶级显卡成绩对比:

历代芯片性能级显卡成绩对比:

特性测试的前两个项目都是用来考核显卡的传统填充率性能,其中测试一的“贴图填充率”主要用于考核显卡的贴图填充率性能;而测试二的“色彩填充率”测试则比较有趣,通过渲染FP16格式目标来考核显卡在FP16 HDR下的填充率性能。对于目前的主流显卡来说,显存带宽对于这两项测试的结果影响更大。
3Dmark Vantage 视差闭塞映射
● 3Dmark Vantage 视差闭塞映射
POM可以说是目前Bump mapping(凹凸映射)的极致,POM可以在两个三角形组成的平面上模拟出极其复杂精细的凹凸表面。因此可以节省大量的多边形开销,当然天下没有免费的午餐,POM需要消耗巨大的Pixel Shader性能作为代价。但随着GPU shader性能的不断提升,POM仍然具备成为主流技术的潜力,目前Crysis等游戏已经采用POM来描绘各种高级次表面效果。

历代芯片顶级显卡成绩对比:
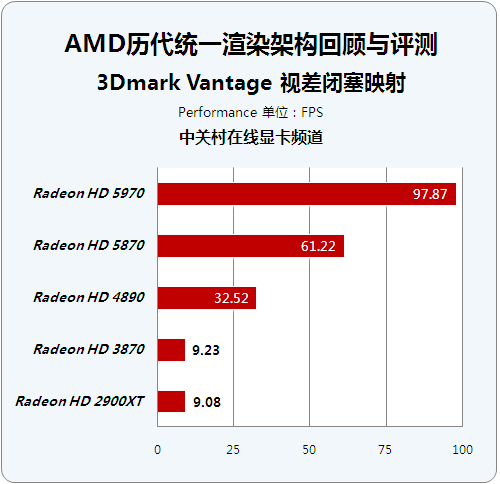
历代芯片性能级显卡成绩对比:
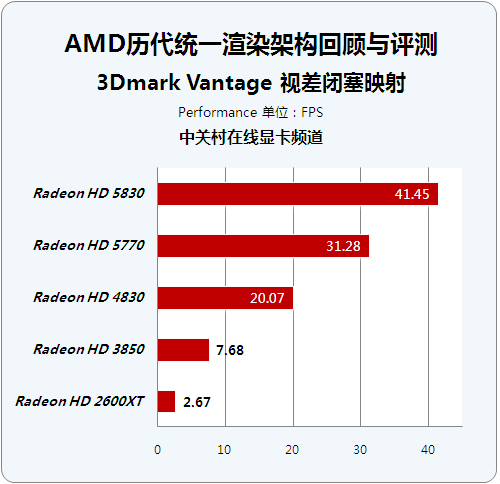
在Vantage的POM测试中,整个场景只用了两个三角形,其它从高空俯视下看到的山川海岳全是POM创造出来的“假象”。场景还有多个光源做打光,而所有凹凸在光照下均能投射精确的自体阴影,所有这些都需要大量的光线追踪计算跟着色运算做支持。整个测试考核了GPU在处理高级复杂的Pixel Shader方面的性能,包括大量的贴图读取性能、动态流控制以及传统Strauus光照的性能。
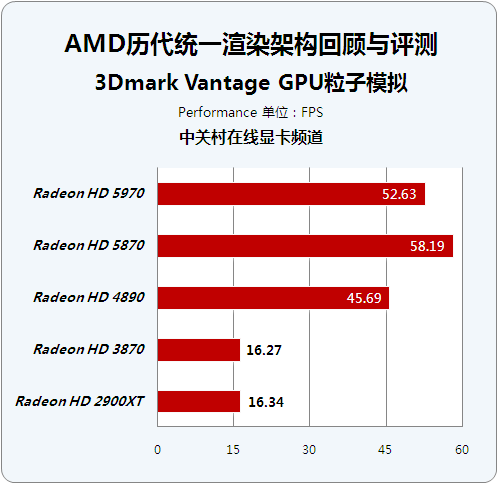
3Dmark Vantage GPU粒子模拟
● 3Dmark Vantage GPU粒子模拟
该测试着重考核了显卡的粒子性能,但是跟普通的GPU粒子系统不同,这里所有的粒子都被赋予了物理属性。该测试通过顶点来模拟粒子的物理性,每一个粒子都被视为一个顶点,因此需要计算每一个顶点跟深度图的碰撞检测。成千上万个粒子对GPU的顶点shader和stream out性能提出了严峻的要求。
历代芯片顶级显卡成绩对比:
历代芯片性能级显卡成绩对比:
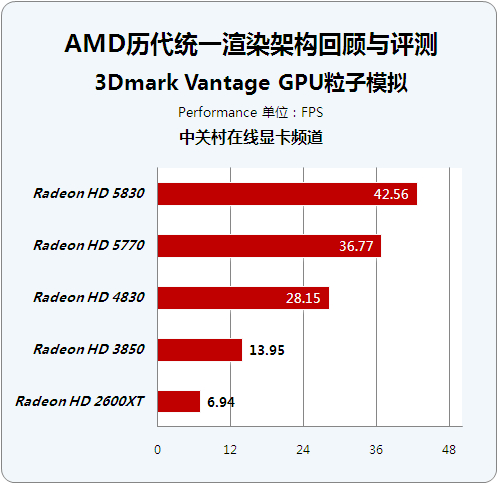
通过测试我们发现这个项目没有对多GPU做优化,所以HD5970因为频率因素出现了一定幅度的下降。虽然现在顶点着色器已经和像素着色器整合为一体,但是这项测试对于GPU的一些特性还是可以清晰体现。
3Dmark 06 Shader Particles 3.0
该项测试是在3DMark06中首次出现的测试项目,该测试项目利用显卡的硬件能力来对游戏中的物理运算能力进行检测,并检验其能否轻松的在显卡上被正确执行,这样游戏开发人员便可以依据这些数据,来充分的发挥显卡的硬件能力,降低CPU占用率,以便让CPU去执行其它的运算任务。该项测试需要SM3.0和硬件Vertex Texture Fetch (VTF)的支持。

历代芯片顶级显卡成绩对比:

历代芯片性能级显卡成绩对比:

在这项测试中,VTF单元数量对最后结果的直接影响非常大。是Vertex Texture Fetch的缩写,指的是顶点纹理获取。VTF中纹理在Vertex Shader引擎内可以动态取样,顶点可以动态变更和加入几何LOD。关于VTF和“render to vertex buffer”(R2VB)的争端,曾今在NV40/G70和R520之间激烈展开。最后随着技术的发展,VTF已经成为GPU中不可或缺的一个功能单元。
Furmark Open GL 性能测试
● Furmark Open GL 性能测试
FurMark 是 oZone3D 开发的一款 OpenGL 基准测试工具,通过皮毛渲染算法来衡量显卡的性能,同时还能借此考验显卡的稳定性。软件提供了多种测试选项,比如全屏/窗口显示模式、九种预定分辨率(也可以自定义)、基于时间或帧的测试形式、多种多重采样反锯齿(MSAA)、竞赛模式等等,并且支持包括简体中文在内的5种语言。
历代芯片顶级显卡成绩对比:

历代芯片性能级显卡成绩对比:

OpenGL的英文全称是“Open Graphics Library”,顾名思义,OpenGL便是“开放的图形程序接口”。虽然DirectX在家用市场全面领先,但在专业高端绘图领域,OpenGL是不能被取代的主角。
本次测试加入OpenGL性能测试,就是为了对不同时期AMD统一渲染架构显卡的性能做更深入的了解。当然FurMark测试对于多GPU也没有提供支持,否则HD5970会有更强的性能表现。当然我们也明白,随着图形API全面倒向DirectX阵营,OpenGL的发展前景不容乐观。
Lightsmark 光照渲染测试
● Lightsmark 光照渲染测试
Lightsmark是一款集中于光影效果和性能测试的新一代显卡3D性能测试软件,Lightsmark主要用来测试电脑运行下一代全局实时光照(Global Illumination)的能力,开发者表示,全局实时光照技术将应用在未来数月发布的多款游戏当中。

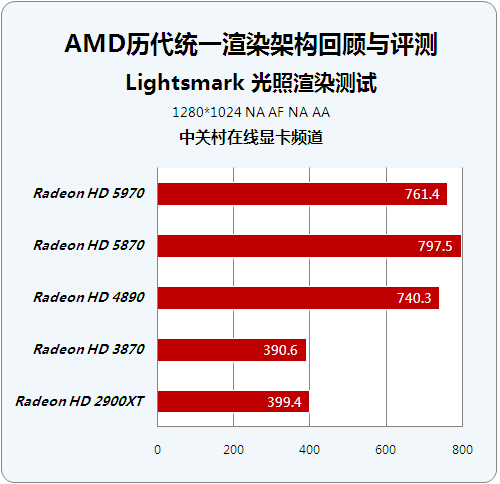
历代芯片性能级显卡成绩对比:

Lightsmark软件已经由发布时的1.1版更新到了1.2版,1.1在基于Radeon HD 2000/3000系列显卡显卡测试时存在一个小bug,一个OPEN GL的提示窗会造成系统失去响应,随后发布的1.2版纠正了这些小bug。
Lightmark软件的菜单界面非常简单,支持从640x480至2560x1600之间多个分辨率测试,并且有全屏(Fullscreen)和窗口(window)两种模式选择。光照渲染能力是GPU综合测试的重要组成部分,运行Lightsmark软件的全过程,也可以认为是顺便欣赏当今各种先进的光照效果的一种享受。这个软件测试不同光照渲染方式的帧数,然后计算平均值反馈给用户。
DirectX 10 SDK Cube Map GS
● DirectX SDK Cube Map GS
CubeMapGS是微软DirectX 10 SDK开发包中的示例演示之一。它调用中使用了Direct3D 10两个显著特点:立方纹理渲染目标使目标数组和几何着色器。一个渲染目标数组允许多个渲染目标和深度模板纹理活跃同时进行。通过使用6个渲染目标,为每立方织构面对一个数组,所有六个面可以呈现在一起的立方体。当几何着色器发出一个三角形,它可以控制在三角形上得到栅格阵列渲染目标。对于每一个传递给三角形的几何着色器,6个三角形的着色器和像素着色器输出到生成,生成每一个目标的三角形。
历代芯片顶级显卡成绩对比:

历代芯片性能级显卡成绩对比:

环境映射构建在三维图形流行和良好的技术支持之上。传统意义上,动态立方体环境映射创建取得的每一个立方体纹理面表面设置为使目标表面呈现的每个立方体面对现场一次。该立方体纹理可以被用来使环境映射对象。这种方法增加了传递渲染,大大减少了应用程序的帧速率。在Direct3D 10中,应用程序可以使用几何着色器和渲染目标阵列来解决这个问题。
DirectX 10 SDK N Body Gravity
● DirectX 10 SDK N Body Gravity
DirectX 10 SDK N Body Gravity应用于高级实时渲染的3D图形和游戏,它首次出现在2007年的SIGGRAPH会议中所表现的三个应用之一。Direct3D 10样本显示N体粒子系统管理完全由GPU进行处理。

历代芯片顶级显卡成绩对比:
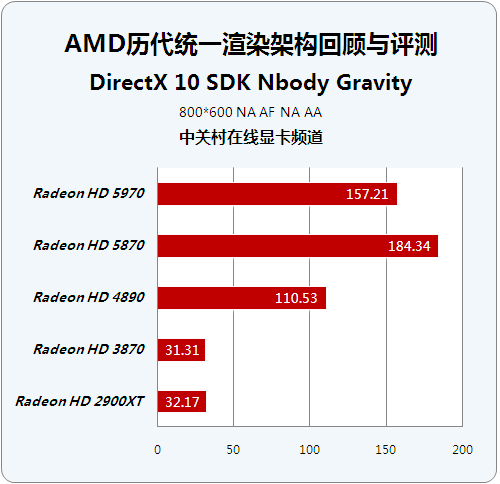
历代芯片性能级显卡成绩对比:

该示例显示了计算系统中的所有粒子之间的相互作用。在这种情况下,涉及的互动之间所有可能的paritcle对重力的影响。在计算N*N相互作用的过程中,我们使用了Splatting。遗憾的是该测试同样没有针对多GPU做出优化,同时我们看到这个测试对于芯片架构更替的体现非常明显。
测试总结与回顾
● 测试总结与回顾
本次我们选取的测试项目,尽力兼顾GPU的全局性能和不同功能单元性能,或者说我们侧重于GPU在某项应用中的实际表现。所以我们没有选择游戏测试这种家喻户晓的3D图形负载,但是这并不说明我们忽视游戏测试的重要性。
回顾AMD在统一渲染时代做出的努力,我们能够感觉到从R600到R800时代,AMD在试图通过不断堆砌SIMD结构的ALU运算器以提升性能,这是一个简单而粗暴的真理。
同时还有一些细节是用户所没有注意到的,比如我们所熟知的RV770架构在程能力和并性能力方面做出很多优化,这些优化让RV770的性能表现相对于R600可以用脱胎换骨来形容。到了R800时代,AMD为了妥协工艺与架构之间的关系,没有做出太显著的架构改善,但是巨大的处理资源还是让用户真切地感受到了性能提升。

AMD在2005年发现了芯片规模的迅速增长对于功耗和发热的压力问题,并逐步提高重视程度着手解决。在GPU产品模块化设计的时代,衡量不同架构和工艺之间的关系已经成为一个重要并难以解决的问题。在这一点上,众多的评测数据特别是每瓦特性能这个指标,已经证明了AMD近几年间的路线。
从另一个角度讲,AMD和NVIDIA在设计思路方面的差异是很明显的。NVIDIA一直用优秀的架构设计,来回避制造工艺带来的种种问题,而AMD虽然在架构上显得落后,但是芯片制程方面总能够领先对手一段时间或者说一段距离。因此AMD可以倚重芯片工艺的进步来考虑未来的发展,NVIDIA则更多地想凭借架构特别是TLP(线程并行度)思路来兼顾图形与计算两个方面。
面对现在图形编程特别是游戏编程在DirectX 9时代的深刻烙印,AMD的想法是正确的,它能够利用架构特性,用最小的晶体管开销换取最大的性能;但是面对未来的图形编程环境,更为灵活地处理繁杂的1D或者非全4D指令才应该是GPU应该走的路,NVIDIA的想法和做法也完全准确,不过NVIDIA为了自己想去开拓的通用计算市场,不得不搭载很多控制和缓存逻辑电路,实现芯片运算器规模的成倍增长的代价要大很多。
就像文中所说,NV更加趋紧于使用基于硬件调度器的Superscalar方式来开发ILP,而AMD更加趋紧于基于软件编译器调度的VLIW方式来开发ILP。总体来说,AMD使用了更大规模的ALU运算器单元,NVIDIA则更注重如何利用有限的ALU运算器资源。AMD将更多的晶体管消耗在大量的SIMD Core单元上,NVIDIA则将更多的晶体管消耗在仲裁机制、丰富的共享缓存资源和寄存器资源以及充足的发射端方面。
让我们把话题转向最新发布的Fermi架构GPU。仅从GPU架构方面分析,我们看到了在以前GPU中根本不可能见到的各种设计,这无疑是一种技术进步的体现。最终导致Fermi放弃浮点吞吐完全转向执行效率,可以算是让NVIDIA近几年设计思路达到完美的体现。但是对于Fermi架构在图形方面的表现,我们还是认为其性能功耗比有待提高。
马上我们就能够看到大量的DirectX 11游戏走入我们的视线,在DirectX 11接口中,Tessellation作为核心技术总是让人大开眼界。当然我们也知道,Fermi架构的GTX480产品拥有15个Tessellation单元的庞大规模,所以曲面细分综合性能远超AMD相关DirectX产品,不过对于Tessellation单元未来的发展,我也不免感到迷茫。
Direct X作为微软主推,业界倾力支持的图形API,一路走来成功统一了无数功能独立的单元,让GPU宏观上看起来更加,可编程性更强。但是曲面细分性能或者说业界对曲面细分的依赖,再次造就出独立的Tessellation单元。当然虽然它不太符合通用处理单元的设计方向,但是如果计算晶体管的投入与性能回报,独立的硬件Tessellation单元是目前最好的选择。
回顾R600到R800的发展历程,我们不好得出什么太直观的结论,毕竟在两家图形芯片厂商激烈竞争的时候,我们不应该带有倾向性或者融入个人情感去讨论这些问题。每当我遇到这种难题时,我还是愿意回到市场,让市场去检验一代或者几代芯片组的发展历程,让用户完成对NVIDIA和AMD两家图形芯片厂商最终的评定。
要说这篇测试的遗憾,就是时间和精力过于有限,导致无法运行更多项目,特别是底层性能的分析;同时对于每项测试数据,也只能寥寥几笔带过,没有做更为深入的分析。希望我们故事化的架构分析能够获得读者的喜欢,也希望我们的评测数据能为用户在分析和理解AMD统一渲染架构演化的过程中,起到一些帮助。
在文章最后,我需要感谢迪兰恒进这家老牌AIB厂商,还有艾维硕科技媒体公关经理,朱亮先生。这本是一篇技术分析文章,而我为了让读者看得更加明白,决定临时加入测试部分。本次测试所用的部分显卡如HD2900XT、HD2600XT,在市场上已经绝迹。在他无私帮助下,迪兰恒进储备的经典显卡来到中关村在线显卡频道,这些古董级别的收藏显卡,最终完成了对所有项目的测试。