快速入门网络爬虫系列 Chapter03 | 抓取网页
Chapter03 | 抓取网页
- 一、了解URL
- 二、常用的获取网页数据的方式
- 1、urllib.request
- 1.1、urllib.request.urlopen
- 1.2、urllib.request.Request
- 1.3、urllib.request的高级特性
- 1.4、Opener
- 1.5、cookie
- 2、requests库
- 2.1、用requests发起请求
- 2.2、requests.Session
- 2.3、设置代理
- 三、浏览器的简单介绍
一、了解URL
- 统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简介的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器怎样处理它。
一个基本URL包含以下内容:
模式(或称协议)、服务器名称(或IP地址)、路径和文件名,如“协议://授权/路径?查询”。完整的、带有授权部分的统一资源标志符语法看上去如下:协议://用户名:密码@子域名。域名。顶级域名:端口号/目录/文件名.文件后缀?参数=值#标志。
eg:

二、常用的获取网页数据的方式
- URLlib
- URLlib.request
- requests库(最常用)
1、urllib.request
- urllib.request是Python标准库之一,是urllib库升级和python3.0后的合并结果,提取对YRL请求更加复杂的操作
- urllib库除了提供urllib库的基本操作外,还提供了授权、重定向、cookies等其他HTTP高层接口操作。
1.1、urllib.request.urlopen
- urlopen函数创建一个指定url或者被封装request的对象,以此为出发点获取数据流,并操作数据
- urlopen的函数格式
urllib.request.urlopen(url,data = None,[timeout,]*,cafile = None, capath = None, cadefault = False,context = None)
- timeout:超时释放链接
- cafile/capath/cadefault:CA认证参数,用于HTTPS协议
- context:SSL链接选项,用于HTTPS
1.2、urllib.request.Request
- 使用urllib.request库向httpbin.org发起请求,使用url和data向服务器发送get和post请求与urllib库一致。
- urllib.request提供Request类,可用来定制请求:
urllib.request.Request(url,data = None,headers = {},origin_req_host = None,unverifiable = False,method = None)
eg:
from urllib import request,parse
url = "http://httpbin.org/post"
headers = {
"user-agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0'
"host":"httpbin.org"
}
dict = {
"name":"Hackdata"
}
data = bytes(parse.urlencode(dict),encoding = "utf8")
req = request.Request(url=url,data =data,headers=headers,method="POST")
response = request.urlopen(req)
print(response.read().decode("utf-8"))
1.3、urllib.request的高级特性
几乎可以做到任何HTTP请求中所有的事情:
- HTTPDefaultErrorHandler用于处理HTTP响应错误,错误都会抛出HTTPError类型的异常
- HTTPRedirectHandler用于处理重定向
- HTTPCookieProcessor用于处理Cookie
- ProxyHandler用于设置代理,默认代理为空
- HTTPPasswordMgr用于管理密码,它维护了用户名密码的表
- HTTPBasicAuthHandler用于管理认证,如果一个链接打开时需要认证,那么用它来解决认证问题
- 更多的可以参考官方文档
1.4、Opener
OpenerDirector:
- OpenerDirector被称之为Opener,urllib.request.urlopen()这个方法,实际上它就是一个Opener
- 为什么要引入Opener?
因为我们需要实现更高级的功能,之前我们使用的Request、urlopen()相当于类库为你封装好了及其常用的请求方法,利用它们两个我们就可以完成基本的请求,但是现在不一样了,我们需要实现更高级的功能,所以我们需要深入一层,使用更上层的实例来完成我们的操作。所以,在这里我们就用到了比调用urlopen()的对象更普通的对象,也就是Opener。
1.5、cookie
- 网站使用Cookie保存用户的浏览信息,如会话ID,上次访问的状态等。
- 客户端在请求的时候必须带上对应的Cookie,这样才能获取需要登录授权才能看到的内容
eg:获取hao123Cookie
import http.cookiejar,urllib.request
cookie = http.cookiejar.CookieJar()
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open("http://www.hao123.com")
for item in cookie:
print(item.name+"="+item.value)

2、requests库
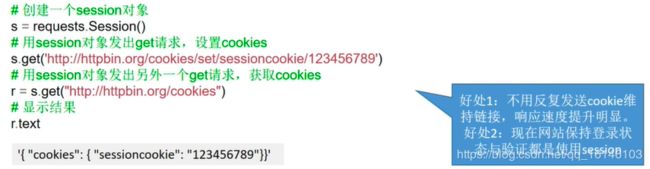
- requests库的session对象能够帮我们跨请求保持某些参数,也会在同一个session实例发出的所有请求之间保持cookies
- requests库的session对象还能为我们提供请求方法的缺省数据,通过设置session对象的属性来实现
requests库的特点:
- 发起GET和POST请求,代码量小,简洁明快
- 带持久Cookie的会话,自动管理Cookie
- 优雅的key/value Cookie格式
- 自动压缩
- 自动内容解码
2.1、用requests发起请求
import requests
import json
# 用requests发起简单的GET请求
url_get = 'http://httpbin.org/get'
response = requests.get(url_get,timeout = 5)
print(json.loads(response.text)['args'])
# 用requests发起带参数的GET请求
kvs = {'k1':'v1','k2':'v2'}
response = requests.get(url_get,params=kvs,timeout = 5)
print(json.loads(response.text)['args'])
# 用requests 发起POST 请求
url_post = 'http://httpbin.org/post'
kvs = {'k1':'v1','k2':'v2'}
response = requests.post(url_post,data=kvs,timeout = 5)
print(response.json()['form'])

上图我们可以看出,方法名把发起的请求表达的很清晰,get就是GET,post就是POST。不仅如此,我们或得的response非常强大,可以直接得到很多信息,并且response中的内容不是一次性的,requests自动将响应的内容read出来,保存在text变量中,你想读取多少次就读多少次,我们看下response中都有哪些有用的信息:
print(response.url)
print(response.status_code)
print(response.headers)
print(response.cookies)
print(response.encoding) # requests会自动猜测响应内容的编码
import json
print(response.json() == json.loads(response.text)) # response.text 是响应内容,可以读取任意次,并且requests可以自动转换json
requests = response.request # 可以直接获取response对应的request
print(response.url)
print(response.headers) # 我们发起的request 是什么样子的一目了然

2.2、requests.Session
Session():会话保持
我们先看下面一段代码:
import requests
url_cookies = 'http://httpbin.org/cookies'
url_set_cookies = 'http://httpbin.org/cookies/set?k1=v1&k2=v2'
print(requests.get(url_cookies,timeout = 5).json())
print(requests.get(url_set_cookies,timeout = 5).json())
print(requests.get(url_cookies,timeout = 5).json())

我们可以看到,调用url_set_cookies设置cookie前后发送的GET请求得到的cookie都是空的。这说明不同的请求之间是没有关系的。这是为什么呢?因为urllib2默认对所有的请求都是忽略cookie的,哪怕是重定向的请求。而requests会在一个请求之内保存cookie(url_set_cookies请求包含了一个重定向请求)。
下面我们可以加上重定向看下:
session = requests.Session()
print(requests.get(url_cookies,timeout = 5).json())
print(requests.get(url_set_cookies,timeout = 5).json())
print(requests.get(url_cookies,timeout = 5).json())

2.3、设置代理
import requests
url = 'http://httpbin.org/cookies/set?k1=v1&k2=v2'
proxies = {'http':'http://username:password@host:port','http://username:password@host:port'}
print(requests.get(url,proxies = proxies,timeout = 5).json()['args'])
# 上面的方法要给每个请求都要加上proxies参数,比较繁琐,可以为每个session设置一个默认的proxies
session = requests.Session()
session.proxies = proxies # 一个session中的所有请求都使用同一套代理
print(session.get(url,timeout = 5).json()['args'])
上述的代码不能运行,因为代理的格式是不正确的,等到我们需要时可以直接估值代码。
需要注意的是:
response中的内容是用unicode编码的,为了便于阅读我们需将其转换成中文,直接打印是不行的,因为Python将一个dict转换成字符串时保留了unicide编码,所以直接打印出来的不是中文。
这里我们采用另一种转换的方法:先将得到的form dict 转换为 unicode字符串(注意其中的ensure_ascii=False参数,它的含义是不对unicode字符转义),然后将得到的unicode字符串编码成UTF-8字符串,最后再转换成dict,方便输出。
三、浏览器的简单介绍
Chrome中提供了检查网页元素的功能,叫做Chrome Inspect。在网页中通过点击右键可以查看该功能,如下图所示:

在本页调出Chrome Inspect,我们可以看到类似于下面的界面:
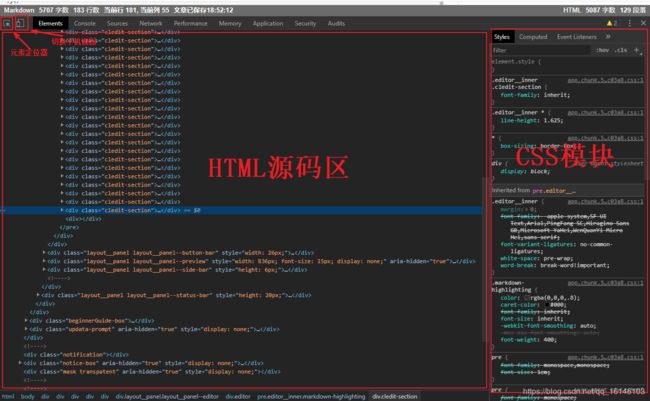
通常我们最常用的功能就是查看一个元素的源码,点击左上角的元素定位器,就可以选择网页中的不同元素,HTML源码区就会自动显示指定元素的源码,通常CSS显示区也会显示这个元素应用的样式。Chrome Inspect更加常用的功能是监控网络交互过程,选择功能栏中的Network,即可看到下面的界面:
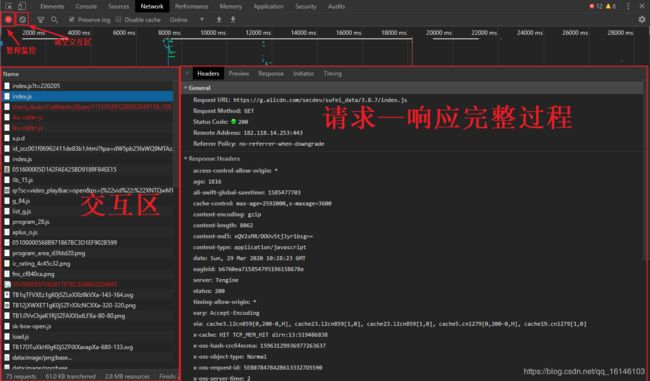
Chrome Network 的交互区显示了一个网页加载过程,浏览器发起的所有请求。选择一个请求,右侧就会显示该请求的详情,包括请求头、响应头、响应内容等。Chrome Network是我们研究网页交互流程的重要工具。Cookie和Session是重要的网络技术,在Chrome Inspect中也可以查看网页Cookie,选择功能栏中的Application,即可看到下面的界面:
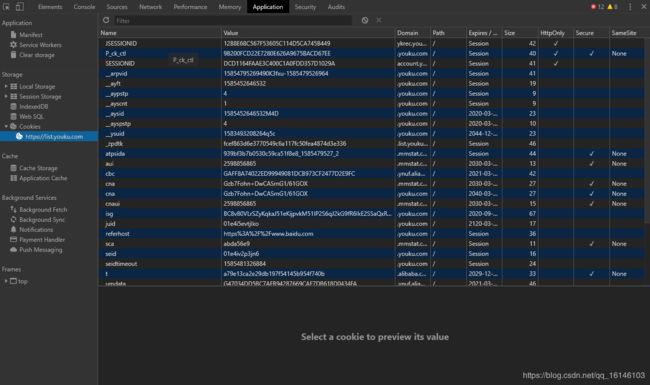
从Chrome Application的左侧选择Cookies,即可看到以K-V形式保存的Cookie。这个功能在我们研究网页的登录过程时非常有用。需要注意的是,在研究一个完整的网络交互过程前,要记得在Cookies上点击右键,然后点击Clear清空所有旧的Cookies。
HTTP Response的第一行,即Status Line 中包含了状态码。状态码由三位数字组成,标志着服务器对客户端请求处理结果。状态码分为以下几类:

下面是一些常见的状态码及其描述:

实际应用中,大多数网站都有反爬虫策略,响应状态码代表了服务器的处理结果,是我们调整爬虫抓取状态(如频率、ip)的重要参考。比如说我们一直正常运行的爬虫突然获取了403响应,这很可能是服务器识别了我们的爬虫,并拒绝了我们的请求。这时,我们就要减慢爬取频率,或者重启Session,甚至更换IP。