Scala快速学习
文章目录
- 1、Scala六大特性
- 2、Scala的安装使用
- 3、Scala基础
- 1)、数据类型
- 2)、变量和常量的声明
- 3)、类和对象
- 4)、if else
- 5)、for,while,do...while
- 4、Scala函数
- 1)、普通函数
- 2)、递归函数
- 3)、包含参数默认值的函数
- 4)、可变参数个数的函数
- 5)、匿名函数
- 6)、嵌套函数
- 7)、偏应用函数
- 8)、高阶函数
- 9)、柯里化函数
- 5、Scala字符串
- 6、Scala集合
- 1)、数组
- 2)、list
- 3)、set
- 4)、map
- 5)、元组
- 7、Scala trait特性
- 8、Scala 模式匹配
- 9、Scala 样例类
- 10、Scala Actor
- 11、Scala 隐式转换
- 12、Scala Demo --Word Count
1、Scala六大特性
- java和scala可以无缝混编(都是基于JVM)
- 类型推测(不必指定类型,自动推测类型)
- 支持并发和分布式(Actor)
- 特质:trait(集结了java中抽象类和接口的产物)
- 模式匹配(match case :类似于java中的switch case)
- 高阶函数(参数时函数或者返回值是参数)
2、Scala的安装使用
本教程介绍在Windows下安装Scala2.10版本。安装包可以去官网下载。Scala官网。也可以直接下载我传到网盘上的压缩包。安装包如下:
链接:https://pan.baidu.com/s/1cDstlitWRXpUfDW48UzzmA 提取码:es15
下载完成之后,解压在电脑合适位置(记住该位置)。然后配置环境变量(和java配置环境变量一样)
新建一个系统变量SCALA_HOME,值是Scala安装包的位置。

编辑Path环境变量,添加;%SCALA_HOME%\bin;%SCALA_HOME%\jre\bin
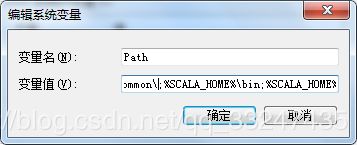
此时scala安装完毕,使用win+r输入cmd打开命令行,然后输入scala -version可以看到安装的scala的版本号。测试成功。

下面分享一个Scala工具:Eclipse Scala版本。
3、Scala基础
1)、数据类型
Byte 8bite的有符号数字,范围在-128 – 127
Short 16bite的有符号数字,范围值在-32868 – 32767
Int 32bite的有符号数字,范围在-21亿 – 21亿
Long 64bite的有符号数字,范围在 负的2的16次方 – 2的16次方
Float 32bite 单精度浮点数
Double 64bite 双精度浮点数
Char 16bite Unicode字符
String 字符串
Boolean 布尔类型
Unit 表示无值,和其他语言的void相同
Null 空值或者空引用
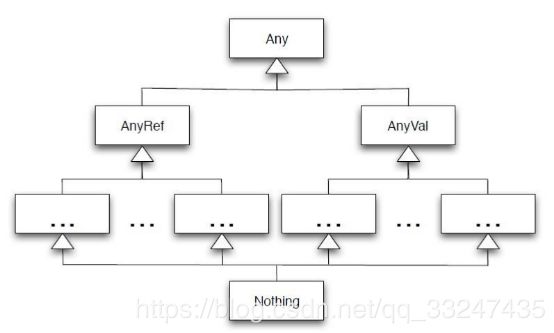
Nothing 所有其他类型的子类型,表示没有值
Any 所有类型的超类,任何实例都属于Any类型。类似于java的Object
AnyRef所有引用类型的超类
AnyVal所有值类型的超类
Nil长度为0的List
2)、变量和常量的声明
定义变量或者常量的时候,可以写上返回类型,也可以不写,如下:
变量:var age:Int = 20或者var age2 = 18
常量:val age:Int = 20或者val age2 = 18(常量不可以再次赋值)
3)、类和对象
创建类:
class Person{
val name = "zhangsan"
val age = 18
def sayName() = {
"my name is "+ name
}
}
创建对象:
object Lesson_Class {
def main(args: Array[String]): Unit = {
val person = new Person()
println(person.age);
println(person.sayName())
}
}
注意:建议类名首字母大写 ,方法首字母小写,类和方法命名建议符合驼峰命名法。
scala 中的object是单例对象,相当于java中的工具类,可以看成是定义静态的方法的类。object不可以传参数。另:Trait不可以传参数
scala中的class类默认可以传参数,默认的传参数就是默认的构造函数。
重写构造函数的时候,必须要调用默认的构造函数。
class 类属性自带getter ,setter方法。
使用object时,不用new,使用class时要new ,并且new的时候,class中除了方法不执行,其他都执行。
如果在同一个文件中,object对象和class类的名称相同,则这个对象就是这个类的伴生对象,这个类就是这个对象的伴生类。可以互相访问私有变量。
4)、if else
Scala中的if else与java中的用法基本一样。样例代码如下:
val age =18
if (age < 18 ){
println("no allow")
}else if (18<=age&&age<=20){
println("allow with other")
}else{
println("allow self")
}
5)、for,while,do…while
讲解Scala的循环之前,先讲解Scala的一个特性:until和to(主要区别是:until前闭后开,to前闭后闭)
println(1 until 10 ) //不包含最后一个数,打印 1,2,3,4,5,6,7,8,9
println(1 until (10 ,3 )) //步长为3,从1开始打印,打印1,4,7
println(1 to 10 ) //打印 1, 2, 3, 4, 5, 6, 7, 8, 9, 10
println(1 to (10 ,2)) //步长为2,从1开始打印 ,1,3,5,7,9
在逻辑上,Scala中的循环跟java中的循环一样,只是使用的方式有些区别,下面分别做介绍。
for循环
//例子: 打印九九乘法表;相当于java中的双层for循环
for(i <- 1 until 10 ;j <- 1 until 10){
if(i>=j){
print(i +" * " + j + " = "+ i*j+" ")
}
if(i==j ){
println()
}
}
与java中不一样的是,for里面可以加判断,如下:
for(i<- 1 to 10 ;if (i%2) == 0 ;if (i == 4) ){
println(i)
}
while与dowhile跟java中判断逻辑一样,下面贴个简单的while例子:
var index = 0
while(index < 100 ){
println("第"+index+"次while 循环")
index += 1
}
注意点:scala中不能使用count++,count—只能使用count = count+1 ,count += 1
for循环用yield 关键字返回一个集合val list = for(i <- 1 to 10 ; if(i > 5 )) yield i
for循环中可以加条件判断,分号隔开
4、Scala函数
1)、普通函数
函数格式:
def 函数名(变量名:变量类型,...):返回值类型 = {
函数体
}
简单函数样例:
def fun (a: Int , b: Int ) : Unit = {
println(a+b)
}
下面是Scala函数的一些规则和注意点:
1. 函数定义语法 用def来定义
2. 可以定义传入的参数,要指定传入参数的类型
3. 方法可以写返回值的类型也可以不写,会自动推断,有时候不能省略,必须写,比如在递归函数中或者函数的返回值是函数类型的时候。
4. scala中函数有返回值时,可以写return,也可以不写return,会把函数中最后一行当做结果返回。当写return时,必须要写函数的返回值。
5. 如果返回值可以一行搞定,可以将{}省略不写。(def fun1 (a : Int , b : Int)= a+b)
6. 传递给方法的参数可以在方法中使用,并且scala规定方法的传过来的参数为val的,不是var的。
7. 如果去掉方法体前面的等号,那么这个方法返回类型必定是Unit的。这种说法无论方法体里面什么逻辑都成立,scala可以把任意类型转换为Unit.假设,里面的逻辑最后返回了一个string,那么这个返回值会被转换成Unit,并且值会被丢弃。
2)、递归函数
递归函数就是循环调用自己,下面给出一个求阶乘的代码:
def fun2(num :Int) :Int= {
if(num ==1)
num
else
num * fun2(num-1)
}
3)、包含参数默认值的函数
默认值的函数中,如果传入的参数个数与函数定义相同,则传入的数值会覆盖默认值。
如果不想覆盖默认值,传入的参数个数小于定义的函数的参数,则需要指定参数名称。
def fun3(a :Int = 10,b:Int) = {
println(a+b)
}
fun3(b=2)
4)、可变参数个数的函数
多个参数用逗号分开。
def fun4(elements :Int*)={
var sum = 0;
for(elem <- elements){
sum += elem
}
sum
}
println(fun4(1,2,3,4))
5)、匿名函数
匿名函数分为有参匿名函数、无参匿名函数、有返回值的匿名函数。(可以将匿名参数的返回给一个val声明的值,匿名函数不能显式的声明返回值)
//有参数匿名函数
val value1 = (a : Int) => {
println(a)
}
value1(1)
//无参数匿名函数
val value2 = ()=>{
println("我爱Angelababy")
}
value2()
//有返回值的匿名函数
val value3 = (a:Int,b:Int) =>{
a+b
}
println(value3(4,4))
6)、嵌套函数
def fun5(num:Int)={
def fun6(a:Int,b:Int):Int={
if(a == 1){
b
}else{
fun6(a-1,a*b)
}
}
fun6(num,1)
}
println(fun5(5))
7)、偏应用函数
偏应用函数是一种表达式,不需要提供函数需要的所有参数,只需要提供部分,或不提供所需参数。
def log(date :Date, s :String)= {
println("date is "+ date +",log is "+ s)
}
val date = new Date()
//想要调用log,以上变化的是第二个参数,可以用偏应用函数处理
val logWithDate = log(date,_:String)
logWithDate("log11")
logWithDate("log22")
logWithDate("log33")
8)、高阶函数
函数的参数是函数,或者函数的返回类型是函数,或者函数的参数和函数的返回类型都是函数的函数。
//函数的参数是函数
def hightFun(f : (Int,Int) =>Int, a:Int ) : Int = {
f(a,100)
}
def f(v1 :Int,v2: Int):Int = {
v1+v2
}
println(hightFun(f, 1))
//函数的返回是函数
//1,2,3,4相加
def hightFun2(a : Int,b:Int) : (Int,Int)=>Int = {
def f2 (v1: Int,v2:Int) :Int = {
v1+v2+a+b
}
f2
}
println(hightFun2(1,2)(3,4))
//函数的参数是函数,函数的返回是函数
def hightFun3(f : (Int ,Int) => Int) : (Int,Int) => Int = {
f
}
println(hightFun3(f)(100,200))
println(hightFun3((a,b) =>{a+b})(200,200))
//以上这句话还可以写成这样
//如果函数的参数在方法体中只使用了一次 那么可以写成_表示
println(hightFun3(_+_)(200,200))
9)、柯里化函数
可以理解为高阶函数的简化
def fun7(a :Int,b:Int)(c:Int,d:Int) = {
a+b+c+d
}
println(fun7(1,2)(3,4))
5、Scala字符串
Scala中字符串String仍是不可变量。StringBuild为可变字符串。具体操作与java类似。下面是我老师整理的String方法集:String方法合集
6、Scala集合
1)、数组
创建数组:
//创建类型为Int 长度为3的数组
val arr1 = new Array[Int](3)
//创建String 类型的数组,直接赋值
val arr2 = Array[String]("s100","s200","s300")
//赋值
arr1(0) = 100
arr1(1) = 200
arr1(2) = 300
遍历数组:
for(i <- arr1){
println(i)
}
arr1.foreach(i => {
println(i)
})
创建二维数组:
val secArray = new Array[Array[String]](5)
for(index <- 0 until secArray.length) secArray(index) = new Array[String](3)
下面继续贴上我老师整理的数组方法
2)、list
list是不可变的,对list进行添加删除或者取值等操作均会返回一个新的list。
val list = List(1,3,5,9)
println(list.contains(9))
val dropList = list.drop(2)
dropList.foreach { println }
val reList = list.reverse
reList.foreach { x => print(x + "\t") }
flatmap :压扁扁平,先map再flat

val logList = List("hello bj","hello sh")
val flatMapList = logList.flatMap { _.split(" ") }
flatMapList.foreach(println)
//上面是不可变的list,下面是可变的listBuffer
var listBuffer = new ListBuffer[String]
listBuffer.+=:("zhao")
listBuffer.+=("liu")
listBuffer.foreach { println }
下面继续贴上我老师整理的list方法
3)、set
set是一个非重复的集合,若有重复数据,则会自动去重。
val set = Set(1,3,5,8,1,6,5,8)
set.foreach { x => print(x + "\t") }
下面继续贴上我老师整理的set方法
4)、map
map是K-V键值对集合。
//创建map
val map = Map(
"1" -> "bj" ,
2 -> "sh",
3 -> "gz"
)
//map遍历
for(x <- map){
println("====key:"+x._1+",value:"+x._2)
}
//遍历key
var keys = map.keys
//获取key的迭代器
var keyIterator = keys.iterator
while(keyIterator.hasNext){
val key = keyIterator.next()
println(key + "\t" + map.get(key).get)
}
下面继续贴上我老师整理的map方法
5)、元组
与列表一样,与列表不同的是元组可以包含不同类型的元素。元组的值是通过将单个的值包含在圆括号中构成的。创建过程可加new关键词,也可不加。
//创建二元组,下面两句话效果相同
val t2 = new Tuple2(1,"hello")
val tt2 = (1,"hello")
//创建三元组,下面两句话效果相同
val t3 = Tuple3(2,"bj","come")
val tt3 = (2,"bj","come")
//创建tt3的迭代器
val tupleIte = tt3.productIterator
while(tupleIte.hasNext) print(tupleIte.next + "\t")
//反转,只针对二元组
val swap = tt2.swap
//toString
println(tt3.toString())
7、Scala trait特性
Scala Trait(特征)相当于java中抽象类和接口的集合体,不只是具备接口的特征,还可以定义属性和方法的实现。一般情况下Scala的类可以继承多个Trait,从结果来看就是实现了多重继承。Trait(特征) 定义的方式与类类似,但它使用的关键字是 trait。
继承的多个trait中如果有同名的方法和属性,必须要在类中使用“override”重新定义。并且trait中不可以传参数。
//定义一个trait
trait Read {
val readType = "Read"
val gender = "m"
def read(name:String){
println(name+" is reading")
}
}
//定义第二个trait
trait Listen {
val listenType = "Listen"
val gender = "m"
def listen(name:String){
println(name + " is listenning")
}
}
//定义了一个类继承上面两个trait
class Person() extends Read with Listen{
override val gender = "f"
}
object test {
def main(args: Array[String]): Unit = {
val person = new Person()
person.read("zhangsan")
person.listen("lisi")
println(person.listenType)
println(person.readType)
println(person.gender)
}
}
8、Scala 模式匹配
模式匹配类似于java的switch case。Scala的模式匹配不仅可以匹配值还可以匹配类型、从上到下顺序匹配,如果匹配到则不再往下匹配、都匹配不上时,会匹配到case _ ,相当于default、match 的最外面的”{ }”可以去掉看成一个语句。
def match_test(m:Any) = {
m match {
case 1 => println("nihao")
case m:Int => println("Int")
case _ => println("default")
}
}
9、Scala 样例类
使用了case关键字的类定义就是样例类(case classes),样例类是种特殊的类。实现了类构造参数的getter方法(构造参数默认被声明为val),当构造参数是声明为var类型的,它将帮你实现setter和getter方法。
样例类默认帮你实现了toString,equals,copy和hashCode等方法。
样例类可以new, 也可以不用new。
case class Person1(name:String,age:Int)
object Lesson_CaseClass {
def main(args: Array[String]): Unit = {
val p = new Person1("zhangsan",10)
}
}
10、Scala Actor
Actor Model是用来编写并行计算或分布式系统的高层次抽象(类似java中的Thread)让程序员不必为多线程模式下共享锁而烦恼,每个Actors有自己的世界观,当需要和其他Actors交互时,通过发送事件和消息,发送是异步的,非堵塞的(fire-andforget),发送消息后不必等另外Actors回复,也不必暂停,每个Actors有自己的消息队列,进来的消息按先来后到排列,这就有很好的并发策略和可伸缩性,可以建立性能很好的事件驱动系统。
Actor的特征:
ActorModel是消息传递模型,基本特征就是消息传递
消息发送是异步的,非阻塞的
消息一旦发送成功,不能修改
Actor之间传递时,自己去检查消息,而不是一直等待,是异步非阻塞的
object Scala07 {
def main(args: Array[String]): Unit = {
val actor = new MyActor
actor.start()
actor ! "hello bj"
}
}
class MyActor extends Actor{
def act() = {
while(true){
receive{
case s: String => println(s)
case _ =>println("default")
}
}
}
}
11、Scala 隐式转换
隐式转换,在编写程序的时候可以尽量少的去编写代码,让编译器去尝试在编译期间自动推导出这些信息来,这种特性可以极大的减少代码量,提高代码质量。
特征:
隐式转换必须满足无歧义规则
在同一个作用域禁止声明两个类型一致的变量,防止在搜索的时候会犹豫不决
声明隐式参数的类型最好是自定义的数据类型,不要使用Int,String这些常用类型,防止碰巧冲突
def sayName(implicit name:String) = {
println("say love to " + name)
}
implicit val name = "fanbingbing"
sayName
12、Scala Demo --Word Count
package com.hpe.spark.demo
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
/**
* 单词统计并排序
*/
object WCSpark {
def main(args: Array[String]): Unit = {
//创建配置对象
val conf = new SparkConf
//设置App的名称 有啥用? 方便在监控页面找到 MR-》Yarn 8088
conf.setAppName("WordCountSpark")
//设置Spark的运行模式 local本地运行 用于测试环境
conf.setMaster("local")
//创建Spark上下文 他是通往集群的唯一通道
val sc = new SparkContext(conf)
/**
* 处理数据 在SparkCore中一切得计算都是基于RDD
* R(Resilient)D(Distributed )D(Dataset)
* RDD 弹性分布式数据集
*/
val lineRDD = sc.textFile("d:/wc.txt")
//基于lineRDD中的数据 进行分词
val wordRDD = lineRDD.flatMap { _.split(" ") }
//每一个单词计数为1 pairRDD K:word V:1
val pairRDD = wordRDD.map { (_,1) }
//相同的单词进行分组,对组内的数据进行累加
val resultRDD = pairRDD.reduceByKey((v1,v2) => v1 + v2)
//用户可以使用sortBy这个方法,来指定根据哪一个字段来排序
resultRDD
.sortBy(x => x._2,false)
.foreach(println)
//释放资源
sc.stop()
}
}
注:使用Spark函数需要导包:Spark包