图像理解(Image Captioning)(2)文本处理和模型
图像理解
- 一、文本处理
- 1.1 生成图像的描述文件
- 2.2 单词嵌⼊(Word Embedding)
- 2.3 生成输入数据结构
- 二、模型处理
- 2.1 创建用于图片理解的模型
- 2.2 模型评价
- 三、 总结
一、文本处理
1.1 生成图像的描述文件
根据数据集中的Flickr8k.token.txt文件生成含有图片对应的描述的文件
def create_descriptions(filename):
with open(filename, 'r') as file_read:
with open("descriptions.txt", "w")as f_write:
for line in file_read:
index = line.find('#')
line_datas = line[:index]+' '+line[index+3:]
f_write.write(line_datas)
2.2 单词嵌⼊(Word Embedding)
- LSTM的输⼊是数值, 单词需要转换为数值才能使⽤LSTM, 最简单的⽅式是将单词转化为整数,每个单词都对应于⼀个整数. 但是这样的⽅式⽆法有效的表达单词直接的相关性, 例如:国王, 王后, 男,⼥如果整数10,11,200,300表示的话,⽆法体现出: 国王 – 男 + ⼥ ≈ 王后
- 单词嵌⼊是利⽤神经⽹络来学习单词的表达,使⽤⼀个向量⽽不是⼀个整数来表达⼀个单词. 向量提供了更⼤的信息量, ⾥⾯可以嵌⼊单词之间的关系, 更好的表达⼀个单词.
- 创建单词嵌入工具
def creat_tokenizer():
tokenizer = Tokenizer()
train_image_names = load_image_names('../Flickr8k_text/Flickr_8k.trainImages.txt')
train_descriptions = util.load_clean_captions('descriptions.txt', train_image_names)
lines = util.to_list(train_descriptions)
print(lines)
tokenizer.fit_on_texts(lines)
dump(tokenizer, open('tokenizer.pkl', 'wb'))
2.3 生成输入数据结构
为了训练LSTM, 训练数据中的每⼀个图像的每⼀个标题都需要被重新拆分为输⼊和输出部分. 如果标题为”a cat sits on the table”, 需要添加起始和结束标志, 变为 ‘startseq a cat sits on the table endseq’, 再从它产⽣如下训练数据序列:
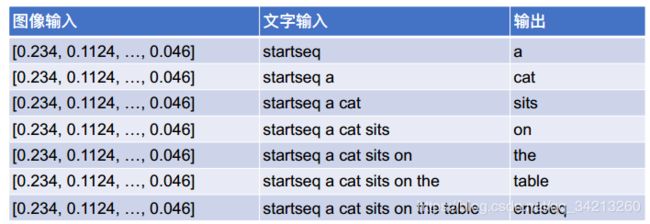
另外, 需要预处理单词,去掉 ‘s 和⼀些不需要的标点符号, 还需要将每⼀个单词转换为⼀个整数
def create_input_data(tokenizer, max_length, descriptions, photos_features, vocab_size):
X1, X2, y = list(), list(), list()
for key, desc_list in descriptions.items():
for desc in desc_list:
seq = tokenizer.texts_to_sequences([desc])[0]
for i in range(1, len(seq)):
if photos_features.__contains__(key):
in_seq, out_seq = seq[:i], seq[i]
# 填充in_seq,使得其长度为max_length
in_seq = pad_sequences([in_seq], maxlen=max_length)[0]
out_seq = to_categorical([out_seq], num_classes=vocab_size)[0]
X1.append(photos_features[key][0])
X2.append(in_seq)
y.append(out_seq)
return array(X1), array(X2), array(y)
二、模型处理
2.1 创建用于图片理解的模型
def caption_model(vocab_size, max_len):
"""创建一个新的用于给图片生成标题的网络模型
Args:
vocab_size: 训练集中标题单词个数
max_len: 训练集中的标题最长长度
Returns:
用于给图像生成标题的网络模型
"""
input_1 = Input(shape=(4096,))
droput_1 = Dropout(0.5)(input_1)
dense_1 = Dense(256, activation='relu')(droput_1)
input_2 = Input(shape=(max_len,))
embedding_1 = Embedding(vocab_size, 256)(input_2)
droput_2 = Dropout(0.5)(embedding_1)
lstm_1 = LSTM(256)(droput_2)
add_1 = add([dense_1, lstm_1])
dense_2 = Dense(256, activation='relu')(add_1)
outputs = Dense(vocab_size, activation='softmax')(dense_2)
model = Model(inputs=[input_1, input_2], outputs=outputs)
model.compile(loss='categorical_crossentropy', optimizer='adam')
return model
2.2 模型评价
-
衡量两个句⼦的相似度(BLEU)
-
⼀个句⼦与其他⼏个句⼦的相似度(Corpus BLEU)
• BLEU,全称为Bilingual Evaluation Understudy(双语评估替换),是⼀个⽐较候选⽂本翻译与其他⼀个或多个参考翻译的评价分数。
• 尽管BLEU⼀开始是为翻译⼯作⽽开发,但它也可以被⽤于评估⾃动⽣成⽂本的质量。
• 具体内容可以参考: https://cloud.tencent.com/developer/article/1042161
三、 总结
整个模型可以从头开始训练, 但是CNN的模型⾮常⼤, 如果每⼀次希望改变语⾔模型,都训练⼀遍CNN, ⾮常耗时
• 可以分开训练
• 可以将CNN部分预训练,作为图像特征提取器, 把每⼀副输⼊的图像转变为⼀组图像特征值
• 这样可以训练更快, 更加节约计算资源
完整项目数据和代码:https://download.csdn.net/download/qq_34213260/12438555