Hive统计TopN问题
模拟的需求为统计每个区域下最受欢迎的产品TOP3,即统计每个区域点击数最多的三个产品。
首先这里有三张表,城市表city_info,产品表product_info,用户行为表user_click。其中,city_info和product_info两张维度表存在MySQL,user_click数据存在于HDFS。
city_info里面有三个字段,分别为city_id,city_name,area。下面分别展示三张表的数据。
city_info

这张表有三个字段,分别为city_id,city_name,area。area字段为该城市属于哪个区,例如华东,西南等。
product_info(部分数据展示)

产品表有三个字段,product_id,product_name,extend_info,extend_info为产品的各种属性,存储为JSON格式,方便添加产品属性。hive中要取出里面的属性,可以用get_json_object函数,
get_json_object(extend_info,'$.product_status') 取出对应的value值。但在大数据生产环境中不建议使用这个函数,因为效率极低。
user_click(部分数据展示)

这里对应的列为user_id,session_id,action_time,city_id,product_id。这里是经过清洗的数据。
统计操作
首先我们将三张表都导入到hive中。在hive中我们用test这个database。
首先我们先在hive中创建三张表。
create table city_info(
city_id int,
city_name string,
area string
)
row format delimited fields terminated by '\t';
create table product_info(
product_id int,
product_name string,
extend_info string
)
row format delimited fields terminated by '\t';
create table user_click(
user_id int,
session_id string,
action_time string,
city_id int,
product_id int
) partitioned by(date string)
row format delimited fields terminated by ',';
注意:user_click的数据字段之间是通过逗号(,)分隔的。我们将user_click建为一个分区表,分区字段为date,值为2016-05-05。
然后我们先将user_click导入到hive中
load data local inpath '/home/hadoop/data/user_click.txt' overwrite into table user_click partition (date='2016-05-05');
导入成功后,我们查看下hive中的数据
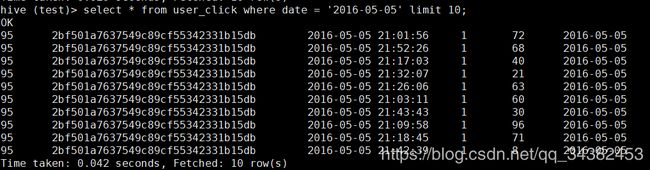
然后使用SQOOP将mysql中的city_info和product_info导入到hive
sqoop import \
--connect jdbc:mysql://localhost:3306/test \
--username root \
--password 123456 \
--table city_info \
--delete-target-dir \
--hive-import \
--hive-table city_info \
--fields-terminated-by '\t' \
--hive-overwrite \
--hive-database test \
--m 1;
sqoop import \
--connect jdbc:mysql://localhost:3306/test \
--username root \
--password 123456 \
--table product_info \
--delete-target-dir \
--hive-import \
--hive-table product_info \
--fields-terminated-by '\t' \
--hive-overwrite \
--hive-database test \
--m 1;
导入成功后,我们查看下数据
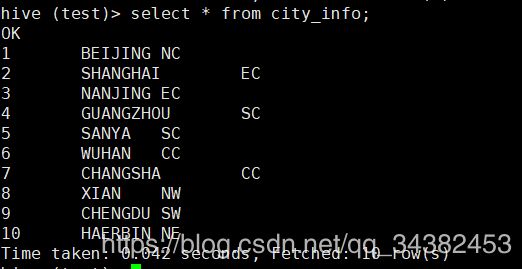

数据准备好后,我们来开始统计。
第一步,将表user_click和product_info关联,找出product_id,product_name,city_id。我们将每步的结果集都插入到临时表中。
create table tmp_product_city_info as
select p.product_id,p.product_name,u.city_id from
(select product_id,product_name from product_info) p
join
(select city_id,product_id from user_click where date = '2016-05-05') u
on p.product_id = u.product_id;

再用表tmp_product_city_info关联city_info,找出字段area。
create table tmp_product_area_info as
select t.product_id,product_name,c.area from tmp_product_city_info t
join
city_info c
on t.city_id = c.city_id;

再将每个区域下每个产品的点击次数统计出来
create table tmp_product_count_info as
select product_id,product_name,area,count(*) click_count
from tmp_product_area_info group by product_id,product_name,area;

再用窗口函数统计出每个区域按点击量排序前3的产品,并根据点击量进行分类,这里分为lower,middle,highest三类
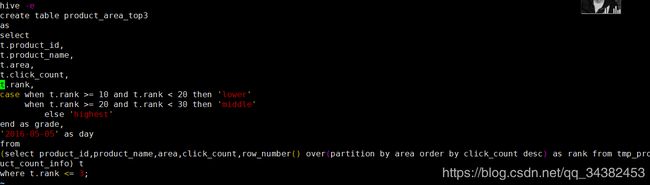
create table product_area_top3 as
select
t.product_id,
t.product_name,
t.area,
t.click_count,
t.rank,
case when t.click_count >= 10 and t.click_count < 20 then 'lower'
when t.click_count >= 20 and t.click_count < 30 then 'middle'
else 'highest'
end as grade,
'2016-05-05' as day
from
(select product_id,product_name,area,click_count,row_number() over(partition by area order by click_count desc) as rank from tmp_product_count_info) t
where t.rank <= 3;
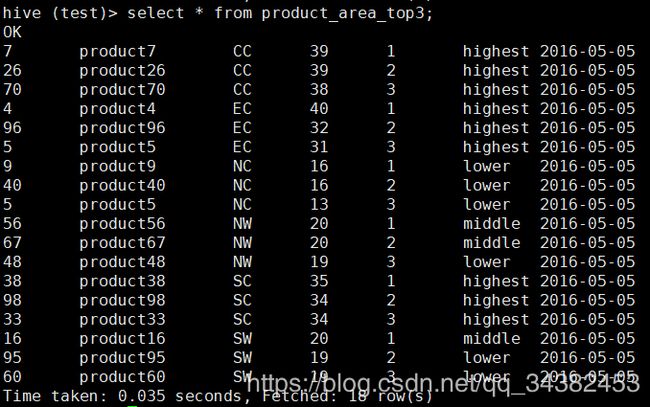
这样我们就统计出了每个区域最受喜爱的top3产品。
在生产环境中,sql执行语句肯定是写在shell脚本里的。我们在脚本前面加上
hive -e
后面加上要执行的hql,这样不用登陆hive客户端就可以执行语句了。
当然,如果不想用临时表,可以用一条语句实现。
create table test.product_area_top3_2 as
select * from
(select m.product_id,m.product_name,m.area,m.click_count,
row_number() over(partition by m.area order by m.click_count desc) as rank,
case when m.click_count > 10 and m.click_count <= 20 then 'lower'
when m.click_count > 20 and m.click_count <= 30 then 'middle'
else 'highest'
end as grade,
'2016-05-05' as date
from
(select count(*) click_count,tt.product_id,tt.product_name,tt.area from
(select u.product_id,p.product_name,c.area from
(select product_id,city_id from test.user_click where date = '2016-05-05') u
join test.city_info c on u.city_id = c.city_id
join test.product_info p on u.product_id = p.product_id) tt
group by tt.product_id,tt.product_name,tt.area) m) n
where n.rank <= 3;
也可以将脚本直接复制到shell脚本文件中,执行
hive -f xxx.sh
这样也可以执行语句。
注意:因为这不是在hive客户端执行hql语句,相关表前面需要加上database信息。不然是默认default库。