Oracle %type、%rowtype,varry、record、table 详解
文章目录
- 1、概述
- 1.1 场景
- 1.2 思维导图
- 1.3 基础数据准备
- 2、%type、%rowtype、record
- 3、集合操作
- 3.1 varry 一维数组(设置长度)
- 3.2 table 多维数组
- 3.2.1 存储单行多列(效果同 varry 一维数组)
- 3.2.2 存储多行多列
- 4、常见问题
- 4.1 何时使用 index by
- 4.2 空数组时
- 4.3 清除数组元素 delete 和 置 null 的区别
- 4.4 数组遍历时,不连续下标异常
- 5、数组属性和函数
1、概述
1.1 场景
在 PL / SQL 开发过程中,经常会出现
%type、%rowtype,varry、record、table这些数据类型。
我刚开始接触时,真不明白这些是啥意思。又或 对某些 使用方式不明确(如:index by…)。百度也没找到自己满意的回复,于是根据自己的实际开发经验来完善这篇文章。
- Oracle 中是没有
“数组”这个概念的 - 不过可以通过集合类型
VARRY和TABLE,来实现“数组”。下面统一称为“数组”
1.2 思维导图
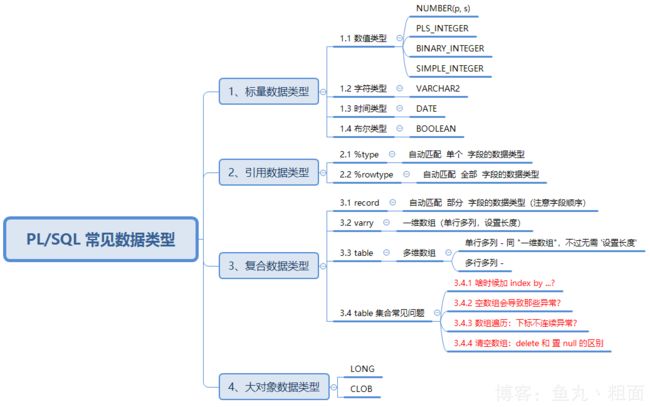
1.3 基础数据准备
CREATE TABLE stu(
ID NUMBER(3),
NAME VARCHAR2(30),
SEX VARCAHR2(2)
);
INSERT INTO stu(ID, NAME, SEX) VALUES(1, '小游子', '女');
INSERT INTO stu(ID, NAME, SEX) VALUES(2, '小优子', '男');
INSERT INTO stu(ID, NAME, SEX) VALUES(3, '瑶瑶', '女');
COMMIT;
2、%type、%rowtype、record
- %type:
单条记录类型自动匹配 - %rowtype:
所有记录类型自动匹配 - record:
部分记录类型自动匹配
DECLARE
v_id stu.id%TYPE;
v_stu stu%ROWTYPE;
TYPE record_stu IS RECORD(
v_name stu.name%TYPE,
v_sex stu.sex%TYPE);
v_stu_record record_stu;
BEGIN
-- TODO: %type - 单条记录
SELECT t.id INTO v_id FROM stu t WHERE t.id = 1;
dbms_output.put_line('%type - v_id: ' || v_id);
-- TODO: %rowtype - 所有记录
SELECT t.* INTO v_stu FROM stu t WHERE t.id = 1;
dbms_output.put_line('%rowtype - v_stu: ' || v_stu.id || ' : ' ||
v_stu.name || ' : ' || v_stu.sex);
-- TODO: record - 部分记录 (select 变量的顺序 和 into 中变量的顺序一致 => 保证数据类型相同 )
SELECT t.name, t.sex INTO v_stu_record FROM stu t WHERE t.id = 1;
dbms_output.put_line('record - record_stu: ' || v_stu_record.v_name ||
' : ' || v_stu_record.v_sex);
EXCEPTION
WHEN OTHERS THEN
dbms_output.put_line(SQLERRM);
dbms_output.put_line(dbms_utility.format_error_backtrace);
END;
/
3、集合操作
- 在 Oracle 中集合中,若想扩充大小有两种方法
- 方式1:(手动)
集合.extend(一次只申请一个空间长度) - 方式2:(自动)
TypeIS TABLE OF index by ..
- 方式1:(手动)
- Oracle 下标定义和其他语言有些区别
- 下标从
1开始算,而不是0哦。
- 下标从
3.1 varry 一维数组(设置长度)
语法:
type 数组名 is varray(size) of 元素类型 [not null];
size : 数组最大长度,必填项。
实例演示:
DECLARE
TYPE varry IS VARRAY(4) OF VARCHAR2(30); -- 最大长度是 4
v_varry varry;
BEGIN
-- 初始化 3 个下标, 也就只能写 3 个长度,即使定义的 有 4 个长度
v_varry := varry('a', 'b', 'c'); -- 构造方法 进行初始化
FOR i IN v_varry.first .. v_varry.last LOOP
dbms_output.put_line(v_varry (i));
END LOOP;
END;
/
3.2 table 多维数组
Oracle 官方解释: The PLS_INTEGER and BINARY_INTEGER data types are identical and are used interchangeably in this document. The
PLS_INTEGERdata type stores signed integers in the range-21,4748,3648 through 21,4748,3647represented in 32 bits. It has the following advantages over the NUMBER data type and subtypes: PLS_INTEGER values require less storage. PLS_INTEGER operations use hardware arithmetic, so they are faster than NUMBER operations, which use library arithmetic.
理解:一般使用pls_integer就可以,除非批次处理业务量大于21,4748,3647,才考虑使用binary_integer
语法:
type table_name is table of element_type[not null]
[index by [binary_integer|pls_integer]];
index by : 创建一个主键索引,以便引用记录表变量中的特定行.
-- 下列参数下标自增(无需 显示初始化:extend)
binary_integer : 由 Oracle来 执行,不会出现溢出,但是执行速度较慢,
因为它是由 Oracle 模拟执行。
pls_integer : 由硬件即直接由 CPU 来运算,因而会出现溢出,但其执行速度
较前者快许多,数据范围:参考 ‘Oracle 官方解释中的红色字体’
3.2.1 存储单行多列(效果同 varry 一维数组)
- 这个和
VARRAY类似。但是赋值方式稍微有点不同,不能使用同名的 构造函数 进行赋值。 - 有个细节:去掉
index by ..后,是可以使用 构造函数 的哦
DECLARE
-- 此例中 INDEX BY PLS_INTEGER 加不加都可以,具体解释看后面
TYPE varry_stu IS TABLE OF VARCHAR2(30) INDEX BY PLS_INTEGER;
v_stu_varry varry_stu;
BEGIN
-- varry_stu := varry_stu('a', 'b', 'c');
-- 此时 不能像 varry 使用上述 构造函数 进行初始化了哦
v_stu_varry(1) := 'a';
v_stu_varry(2) := 'b';
v_stu_varry(3) := 'c';
FOR i IN v_stu_varry.first .. v_stu_varry.last LOOP
dbms_output.put_line(i || ' : ' || v_stu_varry(i));
END LOOP;
END;
/
3.2.2 存储多行多列
TYPE <类型名> IS TABLE OF [%rowtype / record]- 若想匹配所有字段,与
%rowtype最为方便 - 若想匹配部分字段,与
record最为方便
- 若想匹配所有字段,与
- 下列实例是数据仓库中,
表同步的常见写法- 当然,实现功能的写法有很多种,这里,只给出我认为最优的。
DECLARE
i_stu_id NUMBER(3) := 3; -- 模拟入参
v_sql VARCHAR(2000);
cur_stu SYS_REFCURSOR;
TYPE record_stu IS RECORD(
v_id stu.id%TYPE,
v_name stu.name%TYPE);
TYPE table_stu IS TABLE OF record_stu; -- 思考:加不加 index by ...?
v_stu table_stu;
BEGIN
v_sql := 'SELECT t.id, t.name FROM stu t WHERE t.id <= :b1';
OPEN cur_stu FOR v_sql
USING i_stu_id; -- 绑定变量 : 大数据处理常用优化手段
LOOP
FETCH cur_stu BULK COLLECT
INTO v_stu LIMIT 2; -- 数据量太少,仅当前测试使用哦,实际开发 建议 500 左右
EXIT WHEN v_stu.count = 0;
-- 细节:如果此处使用 cur_stu%notfound 不足 limit n 的数据不会在操作了哦
FOR i IN v_stu.first .. v_stu.last LOOP
dbms_output.put_line('学号:' || v_stu(i).v_id || ' , ' ||
'姓名:' || v_stu(i).v_name);
-- 模拟表同步(不存在时 insert、存在时 update)
END LOOP;
END LOOP;
CLOSE cur_stu;
EXCEPTION
WHEN OTHERS THEN
IF cur_stu%ISOPEN THEN
CLOSE cur_stu;
END IF;
dbms_output.put_line(SQLERRM);
dbms_output.put_line(dbms_utility.format_error_backtrace);
END;
/
4、常见问题
4.1 何时使用 index by
- PL/SQL 向
集合类型中插入数据时,必须先扩展内存空间,有两种方式- 手动:extend()
- 自动:index by …
DECLARE
TYPE string_array IS TABLE OF VARCHAR2(30);
TYPE string_array_index IS TABLE OF VARCHAR2(30) INDEX BY PLS_INTEGER;
v_a string_array;
v_b string_array_index;
BEGIN
-- 不加 INDEX BY... 是 可以 使用构造函数的
v_a := string_array('a1', 'a2', 'a3');
-- 加了 INDEX BY... 是 不能 使用构造函数的
-- varry_stu := varry_stu('b1', 'b2', 'b3');
v_b(v_b.count) := 'b0'; -- 细节: 刚开始,数组为空,故 v_b.count = 0
v_b(v_b.count) := 'b1'; -- 之后 count 依次递增(切记:不可指定 count 哦,不然就不递增了,而是重复修改原记录)
v_b(v_b.count) := 'b2';
-- TODO: 分别插入新数据 new1, new2
-- v_a
v_a.extend(2);
v_a(4) := 'new1';
v_a(5) := 'new2';
FOR i IN v_a.first .. v_a.last LOOP
dbms_output.put_line(i || ' : ' || v_a(i));
END LOOP;
dbms_output.new_line();
-- v_b
v_b(v_b.count) := 'new1';
v_b(v_b.count) := 'new2';
FOR i IN v_b.first .. v_b.last LOOP
dbms_output.put_line(i || ' : ' || v_b(i));
END LOOP;
END;
/
输出结果:
1 : a1
2 : a2
3 : a3
4 : new1
5 : new2
0 : b0
1 : b1
2 : b2
3 : new1
4 : new2
4.2 空数组时
- 没加 index by 的数组必须
初始化 - 空数组时,array.first = array.last = null;
- 空数组时,array.count = 0;
DECLARE
TYPE string_array IS TABLE OF VARCHAR2(30);
TYPE string_array_index IS TABLE OF VARCHAR2(30) INDEX BY PLS_INTEGER;
v_a string_array := string_array(); -- 必须先初始化
v_b string_array_index; -- 加了 index by 相当于 默认初始化
BEGIN
dbms_output.put_line('v_a.first: ' || v_a.first);
dbms_output.put_line('v_a.last: ' || v_a.last);
dbms_output.put_line('v_a.count: ' || v_a.count);
dbms_output.new_line();
dbms_output.put_line('v_b.first: ' || v_b.first);
dbms_output.put_line('v_b.last: ' || v_b.last);
dbms_output.put_line('v_b.count: ' || v_a.count);
END;
/
输出结果:
v_a.first:
v_a.last:
v_a.count: 0
v_b.first:
v_b.last:
v_b.count: 0
4.3 清除数组元素 delete 和 置 null 的区别
- 置 null:清除数组元素,但
不删除内存空间 - delete:清除数组元素,并且
删除内存空间
DECLARE
TYPE string_array_index IS TABLE OF VARCHAR2(30) INDEX BY PLS_INTEGER;
v_b string_array_index;
BEGIN
v_b(v_b.count) := 'b1'; -- 因为 数组为空,故而 v_b.count = 0
v_b(v_b.count) := 'b2';
v_b(v_b.count) := 'b3';
-- TODO:置 null 方式,清除数组元素
dbms_output.put_line('原数组长度:' || v_b.count);
v_b(0) := NULL;
dbms_output.put_line('置 null 后的长度:' || v_b.count);
FOR i IN v_b.first .. v_b.last LOOP
dbms_output.put_line(i || ' : ' || v_b(i));
END LOOP;
dbms_output.new_line();
-- TODO:delete 方式,清除数组元素
v_b.delete(0);
dbms_output.put_line('delete 后的长度:' || v_b.count);
FOR i IN v_b.first .. v_b.last LOOP
dbms_output.put_line(i || ' : ' || v_b(i));
END LOOP;
END;
/
输出结果:
原数组长度:3
置 null 后的长度:3
0 :
1 : b2
2 : b3
delete 后的长度:2
1 : b2
2 : b3
4.4 数组遍历时,不连续下标异常
- 数组遍历时,是严格按照下标顺序来的,若中间出现
断层(找不到下标),就会报错。
DECLARE
TYPE string_array_index IS TABLE OF VARCHAR2(30) INDEX BY PLS_INTEGER;
v_b string_array_index;
BEGIN
v_b(v_b.count) := 'b1'; -- 因为 数组为空,故而 v_b.count = 0
v_b(v_b.count) := 'b2';
v_b(v_b.count) := 'b3';
v_b.delete(1); -- 删除 'b2'
FOR i IN v_b.first .. v_b.last LOOP
-- 测试时,请去掉 IF,直接 dbms_output 即可。
IF v_b.exists(i) THEN
dbms_output.put_line(i || ' : ' || v_b(i));
END IF;
END LOOP;
END;
/
输出结果:
0 : b1
2 : b3
5、数组属性和函数
| 属性/函数 | 描述 |
|---|---|
count |
返回集合中元素的个数 |
delete |
删除集合中 所有 的元素及 extend |
delete(x) |
删除元素下标为 x 的元素(对 varry 非法) |
delete(x, y) |
删除元素下标从 x 到 y 的元素(对 varry 非法) |
trim |
从集合末端开始删除一个元素(对 index by 非法) |
trim(x) |
从集合末端开始删除 x 个元素 (对 index by 非法) |
exists(x) |
如果集合元素 x 已经 初始化(extend) ,则返回 true,否则返回 false |
extend |
在集合 末尾 添加一个元素(对 index by 非法) |
extend(x) |
在集合 末尾 添加 x个元素 (对 index by 非法) |
extend(x, n) |
在集合 末尾 添加元素 x 个下标为n 的 副本(对 index by 非法) |
first |
返回集合中第一个元素的下标号,对 varry 集合 始终 返回 1(除非 未初始化 则为 空) |
last |
返回集合中最后一个元素的下标号,对 varry 集合 值始终 等于 count (除非 未初始化 则为 空) |
limit |
返回 varry 集合的最大的元素个数,对 index by 无效 |
next(x) |
返回在第 x 个元素之后紧挨着它的元素下标(x+1),若 x 是最后一个元素,则返回 null |
prior(x) |
返回在第x个元素之前紧挨着它的 元素下标(x-1),如果 x 是第一个元素,则返回 null |