重学Redis数据结构
基础数据结构
Redis 有 5 种基础数据结构,分别为:string、list 、set 、hash 和 zset 。熟练掌握这5种基本数据结构的使用是 Redis 最基础也最重要的部分。当然,如果你还掌握了 Bit array 和 HyperLogLog ,那你将会是整条该最亮的仔。
在进入正题之前,你需要清楚一点:Redis 所有的数据结构都是以唯一的 key 字符串作为名称,然后通过这个唯一 key 值来获取相应的 value 数据。差异就在于 value 的结构不一样。这里的 value结构就是上面提到的内容。
string
string 是 Redis 最常用并且最简单的数据结构。一个常见的用途就是缓存用户信息。我们将用户信息使用 JSON 序列化成字符串,然后将序列化后的字符串使用 string 结构缓存起来。同样,取用户信息会经过一次反序列化的过程。当然你也可以使用 hash 结构,至于两者的区别在本文末尾进行描述。
Redis 的字符串是动态字符串,是可以修改的字符串,内部结构实现上类似于 Java 的 ArrayList,采用预分配冗余空间的方式来减少扩容次数。如果你熟悉 Java 的话,你此刻应该清楚 string 的低层数据结构是怎么样的了。如图所示:
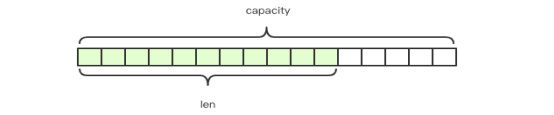
SDS
Redis 的字符串叫做「SDS」,也就是 Simple Dynamic String。它的结构是一个带长度信息的字节数组。
struct SDS<T> {
T capacity; // 数组容量,记住这个类型T,后面要考
T len; // 数组长度
byte flags; // 特殊标识位,不理睬它
byte[] content; // 数组内容
}
结合SDS的结构体和上述结构图,我们可以很清楚的知道,content 里面存储了真正的字符串内容,是以字节数组的形式存储的,这一点很重要,先记住,后面要考。capacity 表示所分配数组的长度,len 表示字符串的实际长度。
前面我们就提到,string 是可以修改的字符串,那它就要支持 append 操作。我们来看看它的源码:
sds sdscatlen(sds s, const void *t, size_t len) {
size_t curlen = sdslen(s);
// 按需调整空间,如果 capacity 不够容纳追加的内容,就会重新分配字节数组并复制原字符串的内容到新数组中
s = sdsMakeRoomFor(s,len);
if (s == NULL) return NULL; // 内存不足
memcpy(s+curlen, t, len); // 追加目标字符串的内容到字节数组中
sdssetlen(s, curlen+len); // 设置追加后的长度值
s[curlen+len] = '\0'; // 让字符串以\0 结尾
return s;
}
我们需要清楚的一点是 Redis 规定字符串的长度不得超过 512M 字节。创建字符串时 len 和 capacity 一样长,不会多分配冗余空间,这是因为绝大多数场景下我们不会使用 append 操作来修改字符串。
embstr vs raw
Redis 的字符串有两种存储方式,长度不超过 44 字节时,使用 emb 形式存储,当长度超过 44 字节时,使用 raw 形式存储。
这两种方式有何不同呢?为什么分界线是 44 呢?
在说明这个问题之前,我们需要先了解一下 Redis 对象头结构体,所有的 Redis 对象都有下面的这个结构头:
struct RedisObject {
int4 type; // 4bits
int4 encoding; // 4bits
int24 lru; // 24bits
int32 refcount; // 4bytes
void *ptr; // 8bytes,64-bit system
} robj;
关于对象头的信息这里就不详细展开了,但是从上面的结构中,我们可以计算出对象头需要的存储空间为 16 字节。
接着我们再看 SDS 结构体的大小,前面我们已经给出了SDS的结构体,关于 capacity 和 len 的类型 T 这一点,是由于 Redis 为了对内存做极致的优化,在字符串比较短时使用 byte 和 short,不同长度的字符串使用不同的类型来表示。所以我们就能得到SDS所需要的最少存储空间。意味着分配一个字符串的最小空间占用为 19 字节 (16+3)。结构如下:
struct SDS {
int8 capacity; // 1byte
int8 len; // 1byte
int8 flags; // 1byte
byte[] content; // 内联数组,长度为 capacity
}
embstr 和 raw 在内存上的结构如下图所示:
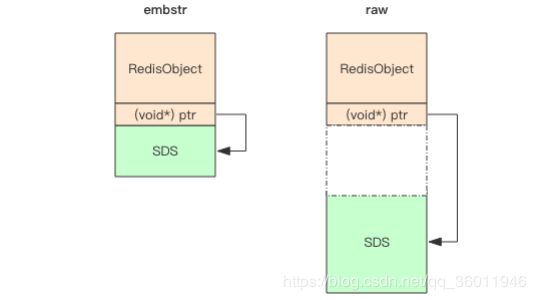
embstr 它将 RedisObject 对象头和 SDS 对 象连续存在一起,使用 malloc 方法一次分配。而 raw 存储形式不一样,它需要两次 malloc,两个对象头在内存地址上一般是不连续的。
而内存分配器 jemalloc/tcmalloc 等分配内存大小的单位都是 2、4、8、16、32、64 等等,为了能容纳一个完整的 embstr 对象,jemalloc 最少会分配 32 字节的空间(19>16),如果字符串再稍微长一点,那就是 64 字节的空间。如果总体超出了 64 字节,Redis 认为它是一个大字符串,不再使用 emdstr 形式存储,而该用 raw 形式。
当内存分配器分配了 64 空间时,那这个字符串的长度最大可以是多少呢?这个长度就是 44。那为什么是 44 呢?
前面我们提到 SDS 结构体中的 content 中的字符串是以字节 \0 结尾的字符串,之所以多出这样一个字节,是为了便于直接使用 glibc 的字符串处理函数。留给 content 的长度最多只有 44(64-19-1) 字节了。
字符串在长度小于 1M 之前,扩容空间采用加倍策略,也就是保留 100% 的冗余空间。当长度超过 1M 之后,为了避免加倍后的冗余空间过大而导致浪费,每次扩容只会多分 配 1M 大小的冗余空间。
list
list 它是链表而不是数组,既然它的底层实现是基于链表的数据结构,那么它就具备了链表的有点和缺点。插入、删除时间复杂度O(1),索引查询时间复杂度O(n)。关于时间复杂度有兴趣的同学可以了解自行一下算法和数据结构相关的内容。
Redis 底层存储的还不是一个简单的 linkedlist,而是称之为快速链表 quicklist 的一个结构。quicklist 是 ziplist 和 linkedlist 的混合体。
ziplist
压缩列表是一块连续的内存空间,结构体如下:
struct ziplist<T> {
int32 zlbytes; // 整个压缩列表占用字节数
int32 zltail_offset; // 最后一个元素距离压缩列表起始位置的偏移量,用于快速定位到最后一个节点
int16 zllength; // 元素个数
T[] entries; // 元素内容列表,挨个挨个紧凑存储
int8 zlend; // 标志压缩列表的结束,值恒为 0xFF
}
struct entry {
int<var> prevlen; // 前一个 entry 的字节长度
int<var> encoding; // 元素类型编码
optional byte[] content; // 元素内容
}

ztail_offset 是支持双向遍历的关键,用来快速定位到最后一 个元素。prevlen 它是一个变长的整数,当字符串长度小于 254 时,使用一个字节表示;如果达到或超出 254 那就使用 5 个字节来表示。这意味着如果某个 entry 经过了修改操作从 253 字节变成了 254 字节,那么它的下一个 entry 的 prevlen 字段就要更新,从 1 个字节扩展到 5 个字节;那么下下个entry 的 prevlen 字段还得继续更新,形成了级联更新。
quicklist
quicklist 是 ziplist 和 linkedlist 的混合体,它将 linkedlist 按段切分,每一段使用 ziplist 来紧凑存储,多个 ziplist 之间使用双向指针串接起来。
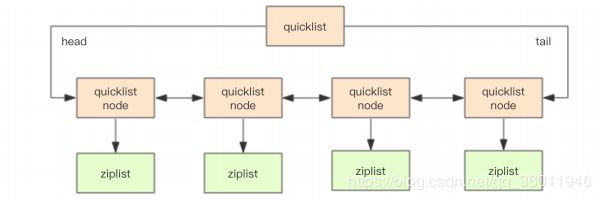
quicklist 内部默认单个 ziplist 长度为 8k 字节,超出了这个字节数,就会新起一个 ziplist。
为什么不只使用 ziplist 或者是 linkedlist ,而是要结合起来使用呢?
如果只使用 ziplist,由于它是连续的固定空间,新增元素是必定要频繁扩容,如果 ziplist 占据内存太大,重新分配内存和拷贝内存就会有很大的消耗。还有更新会涉及级联更新,这个也是不可忽视的消耗。
如果只使用 linkedlist ,普通的链表每个元素都需要附加两个指针,会比较浪费空间,而且会加重内存的碎片化,导致剩余内存足够的情况下无法分配空间。
所以 Redis 将 linkedlist 和 ziplist 结合起来组成了 quicklist。也就是将多个 ziplist 使用双向指针串起来使用。这样既满足了快速的插入删除性能,又不会出现太大的空间冗余,虽然碎片化无法彻底解决,但相对仅使用 linkedlist 来说,已经好很多了。
所以说 Redis 为了内存利用率可谓是绞尽脑汁了。
hash
Redis 的字典相当于 Java 语言里面的 HashMap,熟悉 Java 的同学肯定十分了解 HashMap 的数据结构了,它是由数组+链表的数据结构,Redis 里的实现也是一样的,在发生 hash 碰撞时,就会将碰撞的元素使用链表串接起来。大概结构如下图所示:
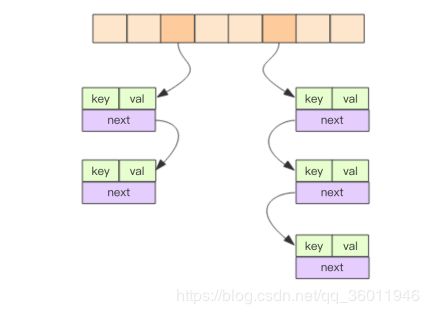
dict

dict 结构内部包含两个 hashtable,通常情况下只有一个 hashtable 是有值的。但是在 dict 扩容缩容时,需要分配新的 hashtable,然后进行渐进式搬迁,这时候两个 hashtable 存储的分别是旧的 hashtable 和新的 hashtable。待搬迁结束后,旧的 hashtable 被删除,新的 hashtable 取而代之。
渐进式 rehash
大家可以想一下,如果 Redis 采用 Java 中 HashMap 的 rehash 方式的话,在 rehash 期间是同步的,对于单线程的 Redis 来说,就意味着无法对外提供服务,如果 dicti 很大的话,阻塞时间将会很长,这对于作为存储系统的 Redis 来说是无法接受的。所以 Redis 使用渐进式 rehash 小步搬迁。
扩容
正常情况下,当 hash 表中元素的个数等于第一维数组的长度时,就会开始扩容,扩容 的新数组是原数组大小的 2 倍。
缩容
当 hash 表因为元素的逐渐删除变得越来越稀疏时,Redis 会对 hash 表进行缩容来减少 hash 表的第一维数组空间占用。缩容的条件是元素个数低于数组长度的 10%。
set
Redis 的集合相当于 Java 语言里面的 HashSet,它的 内部实现相当于一个特殊的字典,字典中所有的 value 都是一个值 NULL。
zset
zset 可能是 Redis 提供的最为特色的数据结构,一方面它是一个 set,保证了内部 value 的唯一性,另一方面它可以给每个 value 赋予一个 score,代表这个 value 的排序权重。zset 的内部实现是一个 hash 字典加一个跳跃列表 (skiplist)。
Redis 的跳跃表共有 64 层,kv 之间使用指针串起来形成了双向链表结构,它们是有序排列的,从小到大。不同的 kv 层高可能不一样,层数越高的 kv 越少。同一层的 kv 会使用指针串起来。每一个层元素的遍历都是从 kv header 出发。
查找过程
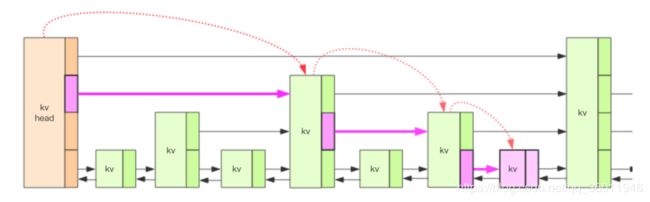
我们要定位到那个紫色的 kv,需要从 header 的最高层开始遍历找到第一个节点 (最后一个比「我」小的元素),然后从这个节点开始降一层再遍历找到第二个节点 (最后一个比「我」小的元素),然后一直降到最底层进行遍历就找到了期望的节点 (最底层的最后一个比我「小」的元素)。
如果 score 值都一样呢?
Redis 自然考虑到了这一点,所以 zset 的排序元素不只看 score 值,如果 score 值相同还需要再比较 value 值 (字符串比较)。
我们将中间经过的一系列节点称之为「搜索路径」,有了这个搜索路径,我们就可以插入这个新节点了。
插入过程
首先我们在搜索合适插入点的过程中将「搜索路径」摸出来了,然后就可以开始创建新 节点了,创建的时候需要给这个节点随机分配一个层数,再将搜索路径上的节点和这个新节 点通过前向后向指针串起来。如果分配的新节点的高度高于当前跳跃列表的最大高度,就需 要更新一下跳跃列表的最大高度。
删除过程
删除过程和插入过程类似,都需先把这个「搜索路径」找出来。然后对于每个层的相关 节点都重排一下前向后向指针就可以了。同时还要注意更新一下最高层数 maxLevel。
更新过程
当我们调用 zadd 方法时,如果对应的 value 不存在,那就是插入过程。如果这个 value 已经存在了,只是调整一下 score 的值,那就需要走一个更新的流程。一个简单的策略就是先删除这个元素,再插入这个元素,需要经过两次路径搜索。Redis 就是这么干的。
那排名 rank 是如何算出来的?
Redis 在 skiplist 的 forward 指针上进行了优化,给每一个 forward 指针都增加了 span 属 性,span 是「跨度」的意思,表示从前一个节点沿着当前层的 forward 指针跳到当前这个节 点中间会跳过多少个节点。Redis 在插入删除操作时会小心翼翼地更新 span 值的大小。
struct zslforward {
zslnode* item;
long span; // 跨度
}
struct zsl {
String value;
double score;
zslforward*[] forwards; // 多层连接指针
zslnode* backward; // 回溯指针
}
参考
[1] Redis深度历险:核心原理和应用实践.