基于骨架的动作识别AGC-LSTM网络(一)
最近自己在一边看机器学习视频的同时一边在看最近关于基于骨骼的动作识别的论文,An Attention Enhanced Graph Convolutional LSTM Network for Skeleton-Based Action Recognition这篇是CVPR2019的一篇论文,上周把这篇论文看了一遍(差不多就是单纯的翻译了一遍),今天又没事翻看了一下,下面我把我自己在阅读的过程自己整理的。
摘要
目前研究的主要挑战:怎么有效的提取具有辨别性的空间和时间特征
因此提出了 注意力增强图卷积LSTM网络 AGC-LSTM
AGC-LSTM不仅可以捕捉空间配置和时间动态的判别特征,而且可以捕捉时间域和空间域的共现关系;此外提出了时间层次结构来增强最高层AGC-LSTM层的时间感受域,从而提高了学习高级语义表现的能力,并且显著减少了计算成本;为了选择和辨别空间信息,注意力机制采用增强每个AGC-LSTM层的关键关节的信息。
一、介绍
动作识别主要分为两类:基于RGB视频和基于3D骨架数据
基于RGB视频:主要关注于模拟RGB帧和和时间光流中的空间和时间表示。局限性:背景杂乱,照明变化,外观变化等等。
基于3D骨架数据:表示具有一组关键关节的3D坐标位置的身体结构,因为没有色彩信息所以没有RGB视频的局限性。
人体骨骼3个显著的特征:
- 每一个节点和他相邻的节点有强相关性,因此骨骼框架包含大量的人体结构信息
- 不仅仅是相同的关节(比如手、手腕、手肘)有时间连续性,整个身体结构也存在时间连续性
- 时间域与空间域有共现关系

上图是AGC-LSTM网络架构
首先,每一个关键点的坐标转换为一个具有线性层的空间特征;
然后,连接两个连续的帧的空间特征和特征差异来构成增强特征(为了消除两个特征之间的比例差异,在处理每个关节序列时使用共享LSTM);
接下来,使用3个AGC-LSTM层来模拟时空特征,AGC-LSTM层的结构图如下;
最后,使用所有关节点的全局特征和来自最后一个AGC-LSTM层的聚焦关节的局部特征来预测动作分类。
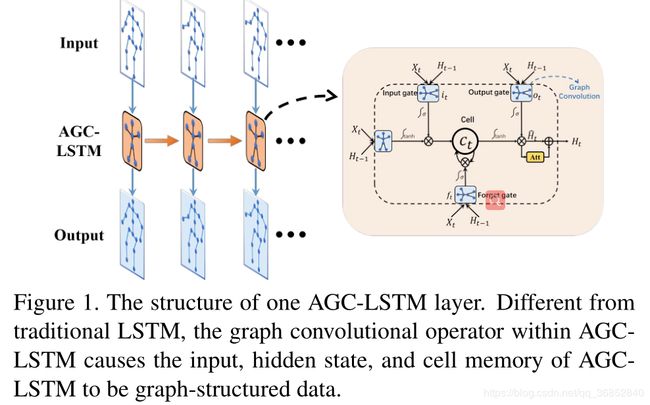
上图是AGC-LSTM层的结构图
由于AGC-LSTM中的图卷积运算子,使得其不但可以有效的获取空间配置和时间动态的判别特征,还可以探索空间域和时间域的共现关系。
受CNN的空间池化的启发,提出了时间层次结构和时间平均池化来增强最高层AGC-LSTM时间接受域,这提高了学习高级时空语义特征的能力,并且降低了计算成本。
二、相关工作
Neural networks with graph
现存的图模型框架主要有两种:GNN、GCN
GNN:图神经网络,图和循环神经网络的结合,通过节点的状态更新和信息传递的多重迭代,每一个节点捕捉其相邻节点内的语义关系和结构信息。
GCN:图卷积网络,它将卷积网络推广到图,有两种GCN:光谱GCN和空间GCN
光谱GCN在图光谱域中变换图形信号,然后在光谱域使用光谱滤波器
空间GCN应用卷积运算利用邻域信息为每一个节点计算新的特征向量
为了计算图序列的时空特征,图卷积LSTM在Structured sequence modeling with
graph convolutional recurrent networks被第一次提出,它是GCN 的扩展,具有循环架构。
Skeleton-bsaed action recongnition
传统基于骨骼的动作识别方法主要关注于设计手工制作的特征。最近的研究主要是通过深度学习网络来学习人类动作表示。
使用图神经网络来捕捉空间结构信息和使用LSTM来模拟时间动态,虽然可以提高性能,但是忽略了时间特征和空间特征的共现性,而AGC-LSTM不但可以提取可辨别的时间特征和空间特征而且还可以探索时间域和空间域的共现关系。
今天就只整理了介绍和相关工作部分,模型架构部分的算法自己还没有弄太懂,等自己弄懂了后会继续更新进行补充。(由于自己英语不是特别好而且刚入门计算机视觉,可能会出现对专业词汇和知识点的理解不到位,如果发现可以评论或者私信,然后我进行改正。)