Mining Discriminative Triplets of Patches for Fine-Grained Classification 论文翻译
摘要
细粒度分类涉及基于高度局部化区域的细微差异来区分相似子类别,因此,精确定位具有区分度的区域仍然是一个主要挑战。我们提出了一个基于patch的框架来解决这个问题。为了提高patch定位的准确性,我们引入了具有几何约束的patch三元组,并自动挖掘具有鉴别意义和几何约束的三元组进行分类。所产生的方法只需要对象边界框。使用四个公开可用的细粒度数据集证明了它的有效性,在这些数据集上,它在分类性能上优于或达到与最新技术相当的性能。
1 引言
细粒度分类的任务是识别属于同一上级类别的子类别。主要的挑战是要进行细粒度分类的对象具有总体上类似的外观,并且仅在高度局部化的区域具有细微的差异。为了有效和准确地找到这些区分区域,以前的一些方法或者需要语义部分注释或者3D模型。这些方法虽然有效,但是它们需要人工标注,费时费力。另一方面,最近关于发掘具有鉴别意义的中层视觉元素方面的研究大都从巨大的候选区域中找到鉴别性patch,并将这些鉴别性元素用于分类。然而,这种方法主要应用于场景分类,而不是典型的细粒度分类。因为细粒度分类所需的具有鉴别意义的patch需要比场景分类具有更准确地定位。
为了避免额外注释的成本,我们提出一种基于pathc的细粒度分类方法,该方法克服了以往区分性中层方法的困难。我们的方法只需要对象边界框注释,并且属于弱注释细粒度分类的类别。
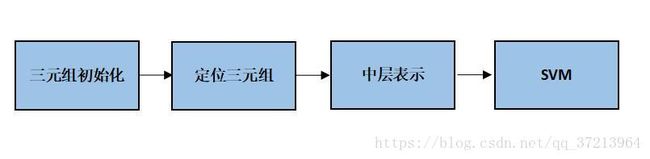
图1 工作流程
这里涉及到两个问题,一个是在没有额外注释的情况下如何精确定位具有鉴别意义的patch,第二个是如何从所有可能的候选池中自动发掘这个有鉴别意义的patch。
对于第一个问题,受嘈杂的背景,模糊以及姿态变化等影响,仅仅依靠外观是很难定位到单个的patch 的,因此文中提出了一种借助几何限制的方法定位一组三元patch。在此前的研究中也有用三元甚至更高元的约束用于图像匹配和配准,但并没有将这些限制整合到基于patch的分类框架中。我们的三元组包含三个外观描述符以及两个简单高效的几何约束,可用于消除单独patch定位时的错误检测。三元组模型相比于简单模型的优势是既可以生成丰富的几何关系模型,同时又可以产生不变性(如,旋转)和鲁棒性(如透视变化)。
第二个问题是如何从巨大的可能的patch池中自动发现有鉴别意义以及几何约束的三元组。关键是细粒度分类的对象具有整体相似的外观。因此检索最近邻的训练样本,就可以从具有相同姿态的不同类样本中获取到具有鉴别意义的patch。并且是通过使用整个训练集或是大部分训练集来取得patch。
2.具有几何约束的Triplets of Patches
假设有三个patch模板 TA, TB and TC,他们中心点的坐标分别为点A,B,C,对于每个![]() 可以是从单个patch中提取的特征向量或来自几个正样本对应的patch对应的平均向量。给定一幅图像,A0,B0,C0分别对应于A,B,C三个patch。
可以是从单个patch中提取的特征向量或来自几个正样本对应的patch对应的平均向量。给定一幅图像,A0,B0,C0分别对应于A,B,C三个patch。
2.1 顺序约束和形状约束
顺序约束编码的三个patch的顺序如图2所示,对于三联patch{A,B,C},考虑两个方向向量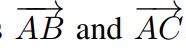 ,将其视为第三维向量为0的三维向量处理。公式吐下:
,将其视为第三维向量为0的三维向量处理。公式吐下:
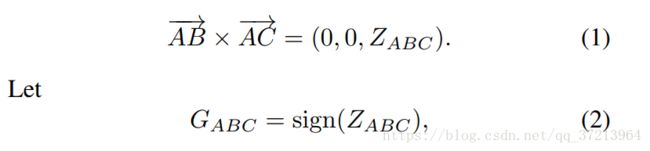
上式意味着若三个patch顺时针排列时![]()
否则为-1
固定两点B,C,顺时针排列时A位于B C连线的左侧,否则位于右侧。
在对应两点间的基于顺序约束的惩罚函数如下:
当![]() 违反
违反![]() 的顺序定义的时候,由
的顺序定义的时候,由![]() 惩罚
惩罚![]()
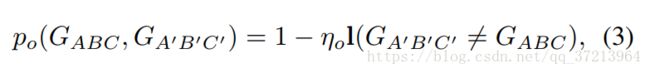
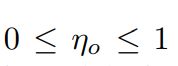 控制顺序约束的重要性。
控制顺序约束的重要性。
指示功能函数如下:
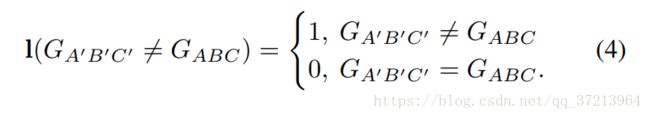
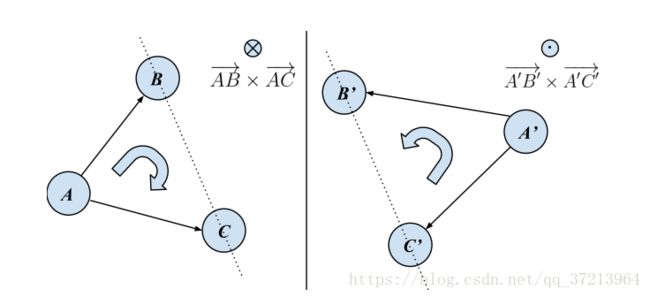
图2 顺序约束可视化。
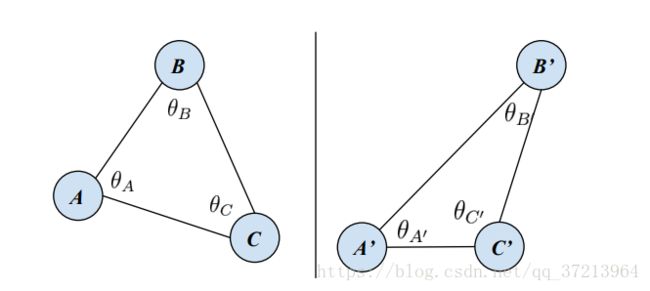
图3 形状约束可视化。通过比较两个三元组的三个角度进行约束。
形状约束通过测量由三个patch中心组成三角形的形状进行约束。如图3所示,A,B,C分别为三个patch的中心点,由三个中心点组成三角形ABC。通过比较两个三角形的角度定义惩罚函数,函数如下:
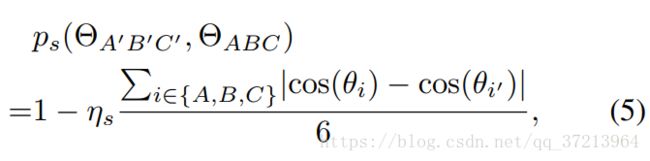
同样,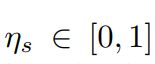 表示形状约束的权重,分母上的6是因为要保证结果Ps<=1
表示形状约束的权重,分母上的6是因为要保证结果Ps<=1
因为![]()
之所以要引入形状约束,是因为第一个顺序约束的约束范围相对较为宽泛,所以需要形状约束来进一步的进行更精细的调整。
2.2 三联检测器
此三联检测器由三个外观模型和两个几何约束组成,从patch模板![]() 中构造三个线性权重
中构造三个线性权重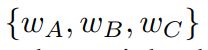
所以检测器的定义如下:
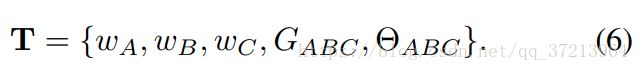
对于一组patch![]()
他的特征![]()
以及几何参数![]()
评分公式为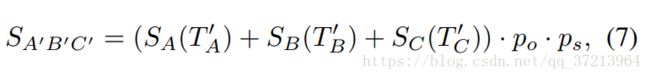
其中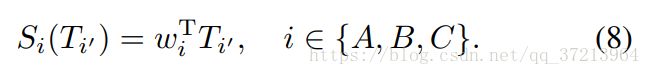
同时提出了三个技术细节:首先是如何有效地获得图像中的三重检测器的最大响应。对于这个问题的解决方法是,首先独立地找到每个外观检测器的前K个非重叠检测,然后对K的立方可能的三元组进行评估,然后选择最大分值的一个三元组。
第二个问题是如何从patch模板中获得线性权重,为了提高效率,使用LDA模型,其定义如下:
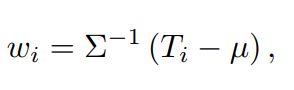
![]() 表示所有patch特征的平均值
表示所有patch特征的平均值
![]() 是协方差矩阵
是协方差矩阵
LDA模型是有效的因为它只为负patch构建一次模型。
我们的三重探测器能够处理适度的姿势变化。但是,如果我们翻转图像,两者都是外观(例如,边缘的主导方向)和patch的顺序都会改变。我们通过将三重态检测器及其镜像应用于图像,生成两个检测分数,并选择较大的分数作为响应来解决此问题。这种简单的技术在实践中证明是有效的。
未完待续。。。