一、基础铺垫
首先我们来个例子:
public class AtomicMain {
public static void main(String[] args) throws InterruptedException {
ExecutorService service = Executors.newCachedThreadPool();
Count count = new Count();
// 100个线程对共享变量进行加1
for (int i = 0; i < 100; i++) {
service.execute(() -> count.increase());
}
// 等待上述的线程执行完
service.shutdown();
service.awaitTermination(1, TimeUnit.DAYS);
System.out.println("公众号:Java3y---------");
System.out.println(count.getCount());
}
}
class Count{
// 共享变量
private Integer count = 0;
public Integer getCount() {
return count;
}
public void increase() {
count++;
}
}
你们猜猜得出的结果是多少?是100吗?
多运行几次可以发现:结果是不确定的,可能是95,也可能是98,也可能是100。
根据结果我们得知:上面的代码是线程不安全的!如果线程安全的代码,多次执行的结果是一致的!
我们可以发现问题所在:count++并不是原子操作。因为count++需要经过读取-修改-写入三个步骤。举个例子:
- 如果某一个时刻:线程A读到count的值是10,线程B读到count的值也是10
- 线程A对count++,此时count的值为11
- 线程B对count++,此时count的值也是11(因为线程B读到的count是10)
- 所以到这里应该知道为啥我们的结果是不确定了吧。
要将上面的代码变成线程安全的(每次得出的结果是100),那也很简单,毕竟我们是学过synchronized锁的人:
- 在increase()加synchronized锁就好了
public synchronized void increase() {
count++;
}
无论执行多少次,得出的都是100。
从上面的代码我们也可以发现,只做一个++这么简单的操作,都用到了synchronized锁,未免有点小题大做了。
- Synchronized锁是独占的,意味着如果有别的线程在执行,当前线程只能是等待!
于是我们原子变量的类就登场了。
1.2CAS再来看看
在写文章之前,本以为对CAS有一定的了解了(因为之前已经看过相关概念,以为自己理解了),但真正敲起键盘写的时候,还是发现没完全弄懂...所以再来看看CAS吧。
比较并交换(compare and swap, CAS),是原子操作的一种,可用于在多线程编程中实现不被打断的数据交换操作,从而避免多线程同时改写某一数据时由于执行顺序不确定性以及中断的不可预知性产生的数据不一致问题。 该操作通过将内存中的值与指定数据进行比较,当数值一样时将内存中的数据替换为新的值。
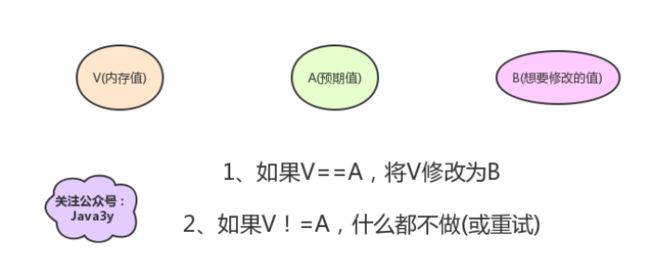
CAS有3个操作数:
- 内存值V
- 旧的预期值A
- 要修改的新值B
当多个线程尝试使用CAS同时更新同一个变量时,只有其中一个线程能更新变量的值(A和内存值V相同时,将内存值V修改为B),而其它线程都失败,失败的线程并不会被挂起,而是被告知这次竞争中失败,并可以再次尝试(或者什么都不做)。
我们画张图来理解一下:
我们可以发现CAS有两种情况:
- 如果内存值V和我们的预期值A相等,则将内存值修改为B,操作成功!
- 如果内存值V和我们的预期值A不相等,一般也有两种情况:
– 重试(自旋)
– 什么都不做
我们再继续往下看,如果内存值V和我们的预期值A不相等时,应该什么时候重试,什么时候什么都不做。
1.2.1CAS失败重试(自旋)
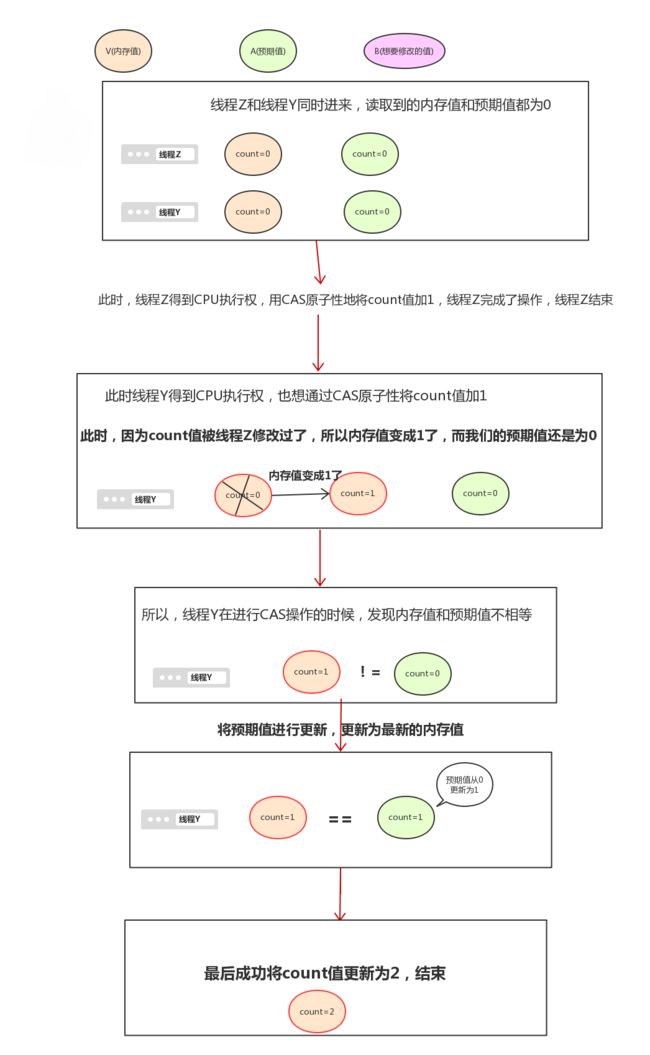
比如说,我上面用了100个线程,对count值进行加1。我们都知道:如果在线程安全的情况下,这个count值最终的结果一定是为100的。那就意味着:每个线程都会对这个count值实质地进行加1。
画张图来说明一下CAS是如何重试(循环再试)的:
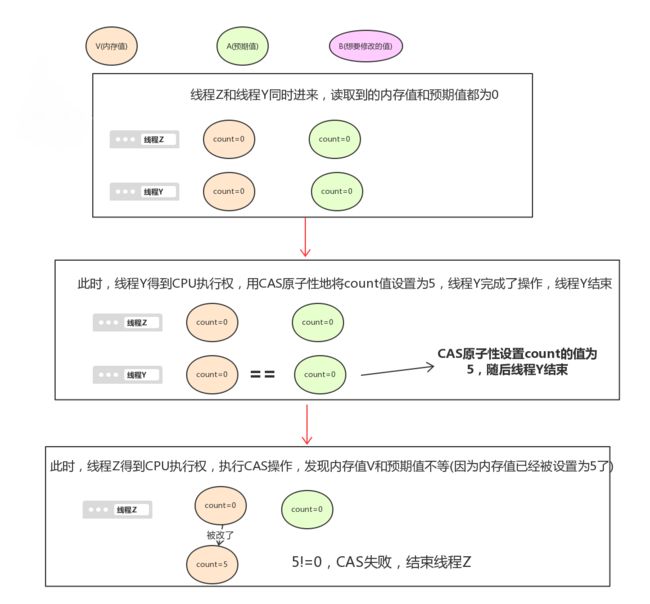
1.2.2CAS失败什么都不做
上面是每个线程都要为count值加1,但我们也可以有这种情况:将count值设置为5。
画个图说明一下:
理解CAS的核心就是:CAS是原子性的,虽然你可能看到比较后再修改(compare and swap)觉得会有两个操作,但终究是原子性的。
二、原子变量类简单介绍
原子变量类在java.util.concurrent.atomic包下,总体来看有这么多个:
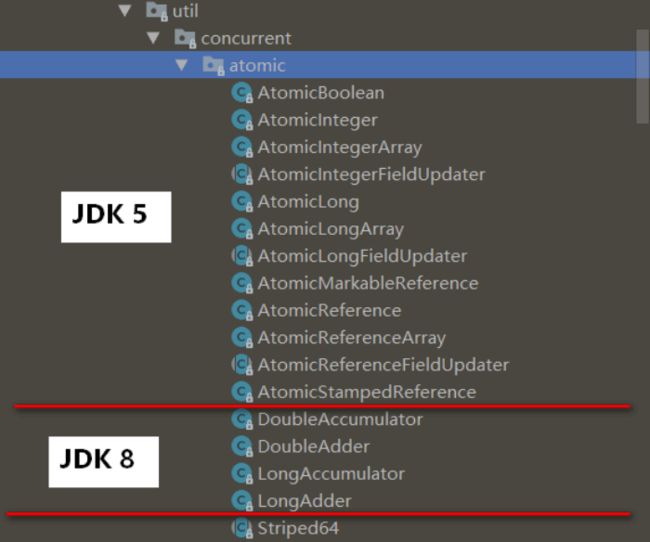
我们可以对其进行分类:
- 基本类型:
– AtomicBoolean:布尔型
– AtomicInteger:整型
– AtomicLong:长整型
- 数组:
– AtomicIntegerArray:数组里的整型
– AtomicLongArray:数组里的长整型
– AtomicReferenceArray:数组里的引用类型
- 引用类型:
– AtomicReference:引用类型
– AtomicStampedReference:带有版本号的引用类型
– AtomicMarkableReference:带有标记位的引用类型
- 对象的属性:
– AtomicIntegerFieldUpdater:对象的属性是整型
– AtomicLongFieldUpdater:对象的属性是长整型
– AtomicReferenceFieldUpdater:对象的属性是引用类型
- JDK8新增DoubleAccumulator、LongAccumulator、DoubleAdder、LongAdder
– 是对AtomicLong等类的改进。比如LongAccumulator与LongAdder在高并发环境下比AtomicLong更高效。
Atomic包里的类基本都是使用Unsafe实现的包装类。
Unsafe里边有几个我们喜欢的方法(CAS):
// 第一和第二个参数代表对象的实例以及地址,第三个参数代表期望值,第四个参数代表更新值 public final native boolean compareAndSwapObject(Object var1, long var2, Object var4, Object var5); public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5); public final native boolean compareAndSwapLong(Object var1, long var2, long var4, long var6);
从原理上概述就是:Atomic包的类的实现绝大调用Unsafe的方法,而Unsafe底层实际上是调用C代码,C代码调用汇编,最后生成出一条CPU指令cmpxchg,完成操作。这也就为啥CAS是原子性的,因为它是一条CPU指令,不会被打断。
2.1原子变量类使用
既然我们上面也说到了,使用Synchronized锁有点小题大作了,我们用原子变量类来改一下:
class Count{
// 共享变量(使用AtomicInteger来替代Synchronized锁)
private AtomicInteger count = new AtomicInteger(0);
public Integer getCount() {
return count.get();
}
public void increase() {
count.incrementAndGet();
}
}
修改完,无论执行多少次,我们的结果永远是100。
其实Atomic包下原子类的使用方式都不会差太多,了解原子类各种类型,看看API,基本就会用了。
2.2ABA问题
使用CAS有个缺点就是ABA的问题,什么是ABA问题呢?首先我用文字描述一下:
- 现在我有一个变量count=10,现在有三个线程,分别为A、B、C
- 线程A和线程C同时读到count变量,所以线程A和线程C的内存值和预期值都为10
- 此时线程A使用CAS将count值修改成100
- 修改完后,就在这时,线程B进来了,读取得到count的值为100(内存值和预期值都是100),将count值修改成10
- 线程C拿到执行权,发现内存值是10,预期值也是10,将count值修改成11
上面的操作都可以正常执行完的,这样会发生什么问题呢??线程C无法得知线程A和线程B修改过的count值,这样是有风险的。
2.3解决ABA问题
要解决ABA的问题,我们可以使用JDK给我们提供的AtomicStampedReference和AtomicMarkableReference类。
简单来说就是在给为这个对象提供了一个版本,并且这个版本如果被修改了,是自动更新的。
原理大概就是:维护了一个Pair对象,Pair对象存储我们的对象引用和一个stamp值。每次CAS比较的是两个Pair对象
因为多了一个版本号比较,所以就不会存在ABA的问题了。
2.4LongAdder性能比AtomicLong要好
如果是 JDK8,推荐使用 LongAdder 对象,比 AtomicLong 性能更好(减少乐观锁的重试次数)。
去查阅了一些博客和资料,大概的意思就是:
- 使用AtomicLong时,在高并发下大量线程会同时去竞争更新同一个原子变量,但是由于同时只有一个线程的CAS会成功,所以其他线程会不断尝试自旋尝试CAS操作,这会浪费不少的CPU资源。
- 而LongAdder可以概括成这样:内部核心数据value分离成一个数组(Cell),每个线程访问时,通过哈希等算法映射到其中一个数字进行计数,而最终的计数结果,则为这个数组的求和累加。
– 简单来说就是将一个值分散成多个值,在并发的时候就可以分散压力,性能有所提高。