A SURVEY OF ONTOLOGY EVALUATION TECHNIQUES
摘要本体论是一些感兴趣领域的明确的正式概念化。 本体越来越多地用于各种领域,例如知识管理,信息提取和语义网。 本体评估是从特定应用标准的角度评估给定本体的问题,通常是为了确定几个本体中哪一个最适合特定目的。 本文介绍了本体评估的最新进展。
1 INTRODUCTION
现代信息系统的焦点正在从“数据处理”转向“概念处理”,这意味着处理的基本单元越来越少是原子数据,并且正在成为一种语义概念,它讽刺解释并存在于与其他概念的背景。本体通常用作通过提供相关概念和它们之间的关系来捕获关于某个区域的知识的结构。使特定学科或方法科学化的关键因素是评估和比较该领域内的想法的能力。在处理本体形式的抽象时,语义Web研究领域也是如此。本体是用于概念化知识的基本数据结构,但我们通常能够构建许多不同的本体,概念化相同的知识体系,并且我们应该能够说出哪些最适合某些预定义的标准。因此,如果要在语义Web和其他语义感知应用程序中广泛采用本体,则本体评估是必须解决的重要问题。面向众多本体的用户需要有一种评估方法,并决定哪一种最符合他们的要求。同样,构建本体的人需要一种方法来评估结果本体,并可能指导构建过程和任何细化步骤。自动或半自动本体学习技术还需要有效的评估措施,可用于从许多候选中选择“最佳”本体,选择学习算法的可调参数值,或指导学习过程本身(如果后者被制定为通过搜索空间的路径。
2 A CLASSIFICATION OF ONTOLOGY EVALUATION APPROACHES
在文献中已经考虑了各种评估本体的方法,这取决于正在评估什么类型的本体以及用于何种目的。从广义上讲,大多数评估方法属于以下类别之一:
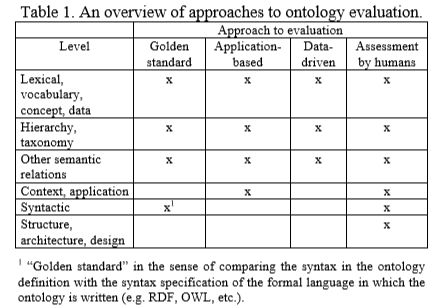
•基于将本体论与“黄金标准”(本身可能是本体论;例如MAEDCHE和STAAB,2002)进行比较的那些; •那些基于在应用程序中使用本体并评估结果的人(例如PORZEL&MALAKA,2004);
•涉及与本体所涵盖的领域的数据来源(例如文档集合)进行比较的那些(例如BREWSTER等,2004);
•那些评估由人类进行评估的人,他们试图评估本体符合一套预定标准,标准,要求等的程度(例如,LOZANOTELLO和GÓMEZ-PÉREZ,2004)。
除了上述评估类别之外,我们还可以根据评估级别对本体评估方法进行分组,如下所述。
本体是一个相当复杂的结构,通常更加切合实际地分别评估不同级别的本体,而不是试图直接评估本体作为一个整体。如果我们想要一个主要是自动化的评估而不是完全由人类用户/专家执行,则尤其如此。基于级别的方法的另一个原因是当在本体的构造中使用自动学习技术时,所涉及的技术对于不同级别而言实质上是不同的。不同的作者已经对各个级别进行了不同的定义,但这些不同的定义往往大致相似,通常涉及以下级别:
词汇,词汇或数据层。这里的重点是本体中包含哪些概念,实例,事实等,以及用于表示或识别这些概念的词汇。对该级别的评估倾向于涉及与涉及问题域的各种数据源(例如,域特定文本语料库)的比较,以及诸如字符串相似性度量(例如,编辑距离)的技术。
层次结构或分类。本体通常包括概念之间的分层关系。虽然也可以定义概念之间的各种其他关系,但is-a关系通常特别重要并且可能是特定评估工作的焦点。
其他语义关系。除了is-a之外,本体可以包含其他关系,并且可以分别评估这些关系。这通常包括精度和召回等措施
上下文或应用程序级别本体可以是更大的本体集合的一部分,并且可以引用或引用这些其他本体中的各种定义。在这种情况下,在评估时考虑此上下文可能很重要。另一种形式的上下文是使用本体的应用程序;评估着眼于如何使用本体来影响应用程序的结果。
句法层面。对于大部分手动构建的本体,对该级别的评估可能特别有意义。本体通常以特定的形式语言描述,并且必须与该语言的语法要求相匹配。还可以考虑各种其他句法考虑因素,例如自然语言文档的存在,避免定义之间的循环等(GÓMEZ-PÉREZ,1994)。
结构,建筑,设计。这主要是对手动构建的本体感兴趣。我们希望本体符合某些预定义的设计原则或标准;结构问题涉及本体的组织及其对进一步发展的适用性(GÓMEZ-PÉREZ,1994,1996)。这种评估通常完全手动进行。
下表总结了本节开头列表中的哪些方法通常用于这些级别中的哪些级别。
3 EVALUATION ON THE LEXICAL/VOCABULARY AND CONCEPT/DATA LEVEL
可以用于评估本体的词汇/词汇级别的方法的示例是MAEDCHE AND STAAB(2002)提出的方法。基于Levenshtein编辑距离测量两个弦之间的相似性,将其归一化以产生范围[0,1]中的分数。然后通过获取第一组的每个字符串,找到它与第二组中最相似的字符串的相似性,并对第一组的所有字符串求平均,来定义两组字符串之间的字符串匹配度量。可以采用在被评估的本体中用作概念标识符的所有字符串的集合,并将其与被认为是所考虑的问题域的概念的良好表示的“黄金标准”字符串集进行比较。黄金标准实际上可能是另一个本体论(如Maedche和Staab的工作),或者它可以从文档语料库(见第7节)统计,或由领域专家准备。
本体的词汇内容也可以使用信息检索中已知的精度和召回概念来评估。在此上下文中,精度将是本体词汇条目(用作概念标识符的字符串)的百分比,其也出现在黄金标准中,相对于本体词的总数。召回是相对于黄金标准词汇条目的总数,在本体中也作为概念标识符出现的黄金标准词条的百分比。实现更宽容的匹配标准(允许同义词等)的一种方法是使用来自WordNet或类似资源的上位词来扩充每个词条(BREWSTER等,2004);然后,不是测试两个词条的相等性,而是可以测试它们相应的词组之间的重叠(每个词包含一个带有上位词的条目)。
也可以使用相同的方法来评估其他级别上的本体的词汇内容,例如,用于标识关系,实例等的字符串
VELARDI等。 (2005)描述了一种评估本体学习系统的方法,该系统采用一系列自然语言文本并试图从中提取相关的特定领域概念(术语和短语),然后找到它们的定义(使用网络搜索) 和WordNet条目)并通过is-a关系连接一些概念。 他们的评估方法的一部分是为多词术语生成自然语言的光泽。 然后可以由领域专家评估这些光泽,因此领域专家不必熟悉通常描述本体的正式语言。
4 EVALUATION OF TAXONOMIC AND OTHER SEMANTIC RELATIONS
BREWSTER等。 (2004)建议使用数据驱动的方法来评估本体和文档语料库之间的结构拟合程度。 (1)给定来自感兴趣的域的文档语料库,基于EM的聚类算法用于以无监督的方式确定隐藏的“主题”的概率混合模型,使得每个文档可以被建模为已经生成混合主题。 (2)本体的每个概念c由一组术语表示,包括本体中的名称和取自WordNet的该名称的上位词。 (3)在聚类期间获得的概率模型可用于针对由聚类算法识别的每个主题测量概念c与该主题的拟合程度。 (4)此时,如果我们要求每个概念至少适合某个主题,我们就会获得一种词汇级别的本体评估技术。或者,我们可能要求与同一主题相关的概念在本体中应该密切相关(通过is-a和可能的其他关系)。这表明本体的结构与领域特定的文档语料库中的主题的隐藏结构相当合理。作为评估关系的方法,这种方法的一个缺点是难以考虑关系的方向性(例如,我们可能知道概念c1和c2应该是相关的,但我们不能真正推断c1是否是-c2,或者c2是-c1,或者如果应该使用一些完全不同的关系)。
鉴于黄金标准,关联级别上的本体评估也可以基于精确度和召回度量,将本体论与人类提供的黄金标准或统计相关术语列表进行比较。 SPYNS(2005)使用它来评估从自然语言文本中自动提取一组lexons的方法,即形式为
GUARINO AND WELTY(2002)讨论了本体评估的一个不同方面。他们指出了几个哲学概念(必要性,刚性,统一性等),可以用来更好地理解本体中常见的各种语义关系的本质,并发现本体结构中可能存在的问题决策(例如,is-a有时用于表示某个类的元级特征,或者用于代替is-a-part-of,或用于表示术语可能具有多个含义)。这种方法的缺点是需要熟悉上述概念(如刚性)的经过培训的人类专家进行人工干预;专家应该使用适当的元数据标签来注释本体的概念,从而可以自动检查某些类型的错误。
MAEDCHE和STAAB(2002)提出了几种比较两种本体关系方面的方法。虽然这在某种程度上是这种方法的缺点,但一个重要的积极方面是,一旦定义了黄金标准,两个本体的比较可以完全自动进行。给定层次结构中的术语c的语义联合体是其所有超概念和子概念的集合。给定两个层次结构H1,H2,术语t可以表示H1中的一些概念c1和H2中的概念c2。然后,可以计算表示来自H2中c1的cotopy的概念的项集合,以及表示来自c2的cotopy的概念的项集合;这两个集合的重叠可以用来衡量术语t在两个层次结构H1和H2中的作用有多么相似。然后可以计算出在两个层次结构中出现的所有术语的平均值;这是H1和H2之间相似性的度量。类似的想法也可用于比较除了a-a之外的其他关系。
5 CONTEXT-LEVEL EVALUATION
有时,本体是可以相互引用的更大的本体集合的一部分(例如,一个本体可以使用在另一个本体中声明的类或概念),例如在web上或在本体的一些机构库内。该上下文可以用于以各种方式评估本体。例如,DING等人的Swoogle搜索引擎。 (2004)使用语义Web文档之间的交叉引用来定义图形,然后以类似于Google Web搜索引擎使用的PageRank的方式计算每个本体的分数。在PATEL等人的OntoKhoj门户中也使用了类似的方法。 (2003年)。并非所有“链接”或本体之间的引用都被视为相同。例如,如果一个本体从另一个本体定义一个类的子类,则该引用可能被认为比一个本体仅使用另一个本体的类作为某个关系的域或范围更重要。
或者,评估的背景可由人类专家提供;例如,SUPEKAR(2005)提出使用元数据来增强本体,例如其设计策略,其他人如何使用它,以及本体用户提供的“同行评审”。然后可以使用合适的搜索引擎来对该元数据执行查询,并且将帮助用户决定使用存储库中的许多本体中的哪一个。
6 APPLICATION-BASED EVALUATION
通常,本体将用于某种应用或任务。应用程序的输出或其在给定任务上的性能可能更好或更差,部分取决于其中使用的本体。因此,人们可能会争辩说,良好的本体论是一种有助于所讨论的应用程序在给定任务上产生良好结果的本体论。因此,可以简单地通过将其插入应用程序并评估应用程序的结果来评估本体。这是优雅的,因为应用程序的输出可能是已经存在相对简单且无问题的评估方法的东西。例如,PORZEL AND MALAKA(2004)描述了一种场景,其中本体及其关系(都是-a和其他)主要用于确定两个概念的含义有多紧密相关。该任务是语音识别问题,其中对任务的最终输出的评估相对简单(将句子的建议解释与人类提供的金标准进行比较)。
基于应用程序的本体评估方法也有几个缺点:(1)我们看到本体在特定任务中以特定方式使用时是好还是坏,但很难概括这一观察结果; (2)本体论只是申请的一小部分,其对结果的影响可能相对较小和间接; (3)比较不同的本体只有在它们都可以插入同一个应用程序时才有可能。
7 DATA-DRIVEN EVALUATION
还可以通过将本体与关于本体所涉及的问题域的现有数据(通常是文本文档的集合)进行比较来评估本体。例如,PATEL等人。 (2003)展示了如何确定本体是否涉及特定主题,并将本体分类为主题目录:一个从本体中提取文本数据(例如概念和关系的名称)并将其用作输入文本分类模型(使用标准机器学习算法训练)。
同样,BREWSTER等。 (2004)使用潜在语义分析从文档语料库中提取了一组相关的特定领域术语。然后可以使用域特定术语与本体中出现的术语(例如,作为概念的名称)之间的重叠量来测量本体和语料库之间的拟合。
对于包含大量事实信息的广泛本体(例如Cyc,参见例如www.cyc.com),文档也可以用作关于外部世界的“事实”的来源,并且评估检查是否这些事实也可以从本体论中得出。
8 MULTIPLE-CRITERIA APPROACHES
另一系列本体评估方法涉及从一组给定的本体中选择一个好的本体(或一小部分有希望的本体),并将这个问题视为一个决策问题。为了帮助我们评估本体,我们可以使用基于定义多个决策标准或属性的方法;对于每个标准,评估本体并给出数值分数。然后将本体的总分计算为其每个标准分数的加权和。在许多其他环境中使用类似策略来选择最佳候选者(例如,招标,拨款申请等)。缺点是可能需要人工专家的大量手动参与。实际上,本体评估的一般问题已被推迟或降级为如何评估关于个体评估标准的本体论的问题。从积极的方面来看,这些方法使我们能够结合第2节中讨论的大多数水平的标准。
BURTON-JONES等。 (2004)提出了这种类型的方法,有十个简单的标准:合法性(即句法错误的频率),丰富性(形式语言中有多少可用的语法特征实际上被本体使用),可解释性(做出这些术语)本体中使用的也出现在WordNet中?),一致性(本体中有多少概念涉及不一致),清晰度(本体中使用的术语在WordNet中有多少含义?),全面性(本体中的概念数量) ,相对于整个本体库的平均值),准确性(本体中虚假语句的百分比),相关性(涉及标记为对用户/代理有用或可接受的语法特征的语句数),权限(多少其他本体使用来自本体的概念),历史(相对于库/存储库中的其他本体,已经对该本体进行了多少次访问)。
福克斯等人。 (1998)提出了另一套标准,然而这些标准更倾向于人工评估和本体评估。 LOZANO-TELLO和GÓMEZPÉREZ(2004)定义了一套更为详细的117项标准,以三级框架组织。
9 CONCLUSIONS AND FUTURE WORK
本体评估仍然是本体支持的计算和语义Web领域中的一个重要的开放问题。 本体评估没有单一的最佳或首选方法; 相反,选择合适的方法必须取决于评估的目的,使用本体的应用,以及我们试图评估的本体的哪个方面。 我们认为,该领域未来的工作应特别注重自动化本体评估,这是自动化本体处理技术健康发展的必要前提,可用于解决诸如本体学习,人口,调解,匹配等诸多问题。 上