协程调度器 Coroutine源码分析
最近准备对一个小巧但又不失精妙和整体的脉络的协程调度器动手了,为了能够深入的理解协程的调度机制和原理,特意分析了一个协程调度器的源码:coroutine
1.Coroutine源码分析
#pragma
//协程的四种不同的状态
#define COROUTINE_DEAD 0
#define COROUTINE_READY 1
#define COROUTINE_RUNNING 2
#define COROUTINE_SUSPEND 3
struct schedule; //调度器结构体
//协程执行函数
typedef void (*coroutine_func)(struct schedule *, void *ud);
//调度器的创建初始化和关闭
struct schedule * coroutine_open(void);
void coroutine_close(struct schedule *);
//协程创建到让出cpu挂起的整过程
int coroutine_new(struct schedule *, coroutine_func, void *ud);
void coroutine_resume(struct schedule *, int fd);
int coroutine_status(struct schedule *, int fd);
int coroutine_running(struct schedule *);
void coroutine_yield(struct schedule *);
#include "coroutine.h"
#include #include "coroutine.h"
#include 执行结果:
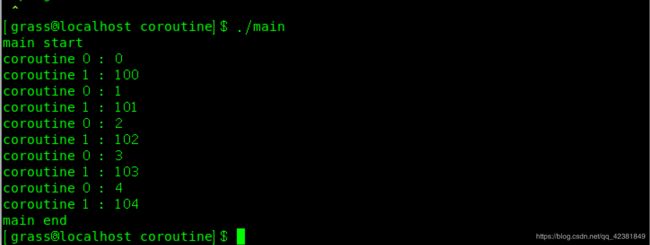
从结果可以看出,协程依照调度器的调度策略依次执行,打印上图的结果。
2. 协程功能函数宏观分析
关于头文件coroutine.h,宏观上的实现就是这几个函数。首先,调用coroutine_open创建协程调度器,然后coroutine_new创建协程,coroutine_yield与coroutine_resume实现协程cpu资源的释放与获取,协作完成协程间的调度过程。还有获取协程的状态信息的API如coroutine_status与coroutine_running。具体的细节,我们稍后详细分析。
3. 协程核心函数的详细分析
3.1 ucontext库
协程的切换显然需要保存上下文环境,我们这里用到了ucontext这个库,具体实现如下
typedef struct ucontext { //上下文结构体
struct ucontext *uc_link; // 该上下文执行完时要恢复的上下文
sigset_t uc_sigmask;
stack_t uc_stack; //协程的栈
mcontext_t uc_mcontext;
...
} ucontext_t;
int getcontext(ucontext_t *ucp); //将当前上下文保存到ucp
int setcontext(const ucontext_t *ucp); //切换到上下文ucp
void makecontext(ucontext_t *ucp, void (*func)(), int argc, ...); //修改上下文入口函数
int swapcontext(ucontext_t *oucp, ucontext_t *ucp); //保存当前上下文到oucp,切换到上下文ucp
依赖getcontext、setcontext、makecontext、swapcontext这几个上下文函数以及上下文结构体ucontext,共同完成协程上下文保存和切换的相关工作。
3.2 coroutine_resume函数
void
coroutine_resume(struct schedule * S, int id) {
assert(S->running == -1);
assert(id >=0 && id < S->cap);
struct coroutine *C = S->co[id];
if (C == NULL)
return;
int status = C->status;
switch(status) {
case COROUTINE_READY: //如果状态是ready也就是第一次创建
getcontext(&C->ctx); //获取当前上下文
C->ctx.uc_stack.ss_sp = S->stack; //将协程栈设置为调度器的共享栈
C->ctx.uc_stack.ss_size = STACK_SIZE; //设置栈容量 使用时栈顶栈底同时指向S->stack+STACK_SIZE,栈顶向下扩张
C->ctx.uc_link = &S->main; //将返回上下文设置为调度器的上下文,协程执行完后会返回到main上下文
S->running = id; //设置调度器当前运行的协程id
C->status = COROUTINE_RUNNING; //设置协程状态
uintptr_t ptr = (uintptr_t)S;
makecontext(&C->ctx, (void (*)(void)) mainfunc, 2, (uint32_t)ptr, (uint32_t)(ptr>>32));//重置上下文执行mainfunc
swapcontext(&S->main, &C->ctx); //保存当前上下文到main,跳转到ctx的上下文
break;
case COROUTINE_SUSPEND: //如果状态时暂停也就是之前yield过
memcpy(S->stack + STACK_SIZE - C->size, C->stack, C->size); //将协程之前保存的栈拷贝到调度器的共享栈
S->running = id;
C->status = COROUTINE_RUNNING;
swapcontext(&S->main, &C->ctx); //同上
break;
default:
assert(0);
}
}
在这里,值得注意的是,此协程库调度器的共享栈大小为1M,协程的私有栈根据运行状态变化。resume时将私有栈拷贝到S->stack中,yield时将已使用的栈拷贝到协程的私有栈中。程序运行使用的是共享栈。
resume就是协程的调度操作,而调度的实现细节,包括1. 上下文切换以及 2. 协程栈的切换。这两项操作保证了协程运行的环境。相应的发生协程切换对应的调度器的状态信息如running,status,都要相应的发生变化。
C->ctx.uc_stack.ss_sp = S->stack; //将协程栈设置为调度器的共享栈
C->ctx.uc_stack.ss_size = STACK_SIZE; //设置栈容量,使用时栈顶栈底同时指向S->stack+STACK_SIZE,栈顶向下扩张
使用共享栈的优缺点,优点就是可以根据实际的情况分配空间,不会造成提前分配固定的空间而空间的浪费,缺点就是栈之间的拷贝会损耗性能。可根据实际情况选择不同的策略。
3.3 _save_stack函数
static void
_save_stack(struct coroutine *C, char *top) { //top为栈底
char dummy = 0; //这里定义一个char变量,dummy地址为栈顶
assert(top - &dummy <= STACK_SIZE); //dummy地址减栈底地址为当前使用的栈大小
if (C->cap < top - &dummy) { //如果当前协程栈大小小于已用大小,重新分配
free(C->stack);
C->cap = top-&dummy;
C->stack = malloc(C->cap);
}
C->size = top - &dummy;
memcpy(C->stack, &dummy, C->size); //将共享栈拷贝到协程栈
}
_save_stack函数用来保存发生"中断调用"(yield)协程的私有栈。值得注意的是,此函数使用了tips。定义一个局部变量dummy,此时dummy的地址是栈顶,根据参数top栈底地址就能够计算出当前协程的私有栈大小,以便于充分的利用空间资源。用memcpy将共享栈保存到私有栈中,即可保存“执行栈的状态”。
4. 总结与思考
从这个程序中,我们能在以下几个方面对协程进行思考。
1)为什么要引入协程,以及协程的定义
基于传统的多线程异步网络框架,多线程异步回调让程序逻辑复杂、调试困难。此外,线程的创建、上下文切换、系统调用等花销都不少,此处就不在展开。于是,便引入了协程的概念。协程,是基于线程的更小的执行单元实体,只具有1. 协程控制块 2. 执行函数 3. 执行栈 等较少资源,因此协程的创建和切换十分快。另外,协程的调度是由用户态的协程库来实现的,是在用户态实现的,协程的调度不需要系统调用切换到内核态。在一个线程的协程组中只能有一个协程占有cpu资源,故协程不存在资源的互斥访问问题。只有当前的cpu释放或者调度时,其他协程才能够获得cpu资源。关于调用(resume)的等级关系可以分为对称协程与非对称协程(我的另外一篇博客详细讲解了)。总结一下,协程是线程划分的更小的执行体,具有创建快、切换快、程序逻辑清晰等优点。
2)协程的作用
我的理解就是,协程就是将线程的业务逻辑进一步划分为更小的逻辑单元,把以前线程通过异步回调机制实现的高并发转化成多个同步执行的协程。注意,这里的同步是指协程在协程组中协程通过调度(resume)和挂起(yield)实现的。协程最根本的作用就是,解决了多线程异步回调机制的复杂性和效率的不可控因素。清晰、明了、“直观”的实现业务逻辑,有效且实用。
3)如何实现协程的,协程的关键
携程库的调度器的机制和协程的上下文切换是协程的关键,我们可以结合代码分析一下。
4)协程的应用(初步的思考)
协程清晰以及高效率让其拥有广阔的应用场所。博主正在读的实践的非常高效率的经典和流行的协程库如下,可以分享给大家:
libco is a coroutine library which is widely used in wechat back-end service. It has been running on tens of thousands of machines since 2013.
Go-style concurrency in C++11
https://github.com/before25tofree/Coroutine