纯命令行环境, 虚拟机配置集群
-
本机环境
windows 10
 image.png
image.png - 集群配置:master + slave1 + slave2, 三台机器均为 1核心 2GB 内存 20GB硬盘, master 可以配置小内存点,slave是工作节点需要大点
准备
- 新建虚拟机, 最低配置 1核心 2GB 内存 20GB硬盘
- 安装 Cento OS7系统, 选择 '最简安装' 降低系统负担;给root用户设密码
本文只讨论单root用户的情况,所以没有任何权限的问题(实际上这是不安全的
- 修改主机名
# hostname // 查看当前主机
localhost.admin
# hostname master // 修改主机名为master
# exit // 登出
- 重新登入
-
联网
5.1 通过ifconfig 确定虚拟机的网卡, ens33 (lo 是本地回环)
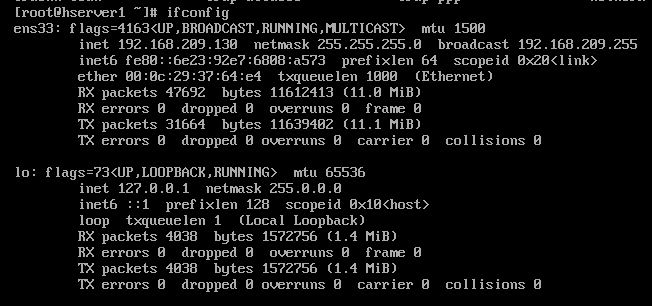 image.png
image.png
5.2 键入命令
# vi /etc/sysconfig/network-scripts/ifcfg-ens33 // 取决于自己的网卡
设置 ONBOOT=yes
# service network restart
- 通过pscp软件把JDK和Hadoop的压缩包传入, 解压, 配置JDK(略)
Master 安装Hadoop
- 创建一些目录供 Hadoop 程序使用。可能变的很大,最好选一些分配磁盘空间较多的挂载点下的路径
mkdir -p /root/hadoop/tmp
mkdir -p /root/hadoop/var
mkdir -p /root/hadoop/dfs/name
mkdir -p /root/hadoop/dfs/data
- 改 $HADOOP_HOME/etc/hadoop/ 中的几个配置文件. 相关配置具体含义及作用不属于本文讨论范围, 请参考其它相关文档。
2.1 core-site.xml // Hadoop整体的一些参数配置
hadoop.tmp.dir
/usr/local/hadoop-3.1.2/tmp
fs.default.name
hdfs://test-1:9000
2.2 hdfs-site.xml // HDFS模块的配置
dfs.name.dir
/usr/local/hadoop-3.1.2/dfs/name
dfs.data.dir
/usr/local/hadoop-3.1.2/dfs/data
dfs.replication
2
dfs.permissions
false
2.3 mapred-site.xml // MapReduce模块的配置
假设我的Hadoop 路径是 /usr/local/hadoop-3.0.0-beta1, 下同
mapred.job.tracker
test-1:49001
mapred.local.dir
/usr/local/hadoop-3.1.2/var
mapreduce.framework.name
yarn
yarn.app.mapreduce.am.env
/usr/local/hadoop-3.1.2
mapreduce.map.env
/usr/local/hadoop-3.1.2
mapreduce.reduce.env
/usr/local/hadoop-3.1.2
yarn.app.mapreduce.am.env
HADOOP_MAPRED_HOME=${HADOOP_HOME}
mapreduce.map.env
HADOOP_MAPRED_HOME=${HADOOP_HOME}
mapreduce.reduce.env
HADOOP_MAPRED_HOME=${HADOOP_HOME}
2.4 yarn-site.xml // YARN模块的配置, 很重要, 稍微不注意就跑不起来。比如说内存,最简单的 wordcount 都需要超过 1GB 内存,所以低于了就跑不了。具体请参考 YARN中内存和CPU两种资源的调度和隔离
yarn.resourcemanager.hostname
test-1
The address of the applications manager interface in the RM.
yarn.resourcemanager.address
${yarn.resourcemanager.hostname}:8032
The address of the scheduler interface.
yarn.resourcemanager.scheduler.address
${yarn.resourcemanager.hostname}:8030
The http address of the RM web application.
yarn.resourcemanager.webapp.address
${yarn.resourcemanager.hostname}:8088
The https adddress of the RM web application.
yarn.resourcemanager.webapp.https.address
${yarn.resourcemanager.hostname}:8090
yarn.resourcemanager.resource-tracker.address
${yarn.resourcemanager.hostname}:8031
The address of the RM admin interface.
yarn.resourcemanager.admin.address
${yarn.resourcemanager.hostname}:8033
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.log-aggregation-enable
true
yarn.nodemanager.vmem-check-enabled
false
yarn.nodemanager.resource.memory-mb
2048
yarn.nodemanager.resource.cpu-vcores
1
yarn.nodemanager.vmem-check-enabled
false
2.5 hadoop-env.sh
补一行
export JAVA_HOME=YOUR_JAVA_HOME_PATH
2.6 works // 工作节点配置
将里面的localhost删除, 改为
test-2
test-3
2.7 sbin/start-dfs.sh sbin/stop-dfs.sh
在空白位置补
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
2.8 sbin/start-yarn.sh sbin/stop-yarn.sh
在空白位置补
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
- 执行命令
在 namenode 上执行 hdfs namenode -format
然后进入 sbin 目录下
./start-all.sh
正常的话,根据配置文件不同,可能细微差别
NameNode 是 MR 的 master 节点,DataNode 是 worker;NodeManager 是 YARN 在工作节点上的,ResourceManger 是主节点。
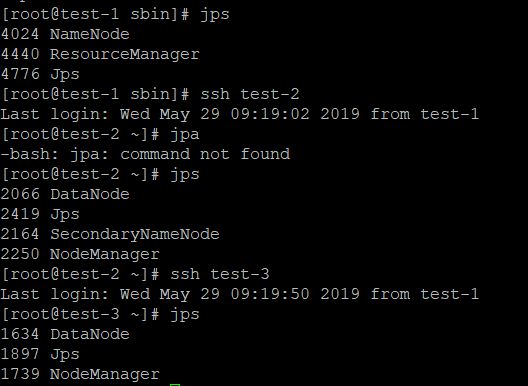
HDFS的管理介面, YARN 的管理介面
可以根据跑 demo 然后看报不报错,报什么错再改。
- 配置静态ip
3.1 在VMware 的虚拟网络编辑器中 查看

3.2 # vi /etc/sysconfig/network-scripts/ifcfg-ens33 // 取决于自己的网卡
// 重点
BOOTPROTO=static //取消DHCP
IPADDR=192.168.209.130 //任意指定IPV4地址, 但要在子网内
GATEWAY=192.168.209.2 //输入在 3.1中看见的
NETMASK=255.255.255.0 //输入在 3.1中看见的
DNS1=223.5.5.5 //阿里DNS
DNS2=223.6.6.6 //阿里DNS
最终如下
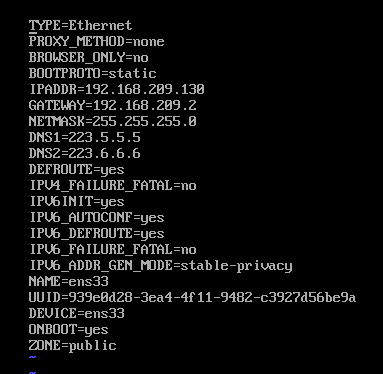
输入ifconfig 查看是否成功修改
-
配置环境变量 #vi /etc/profile
 image.png
image.png
不要忘了 source /etc/profile
Slave
- 克隆两台虚拟机, 完整克隆, 打开
- [Slave两台都要]修改hostname
- [Slave两台都要]修改自己的IP
- [Slave两台都要], # vi /etc/hosts
 image.png
image.png
配置免密ssh
- [Master, Slave1, Slave2]
ssh-keygen -t rsa -P '' //敲回车就行, 保证公匙一致
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys // 把自己的公匙写入authorized_keys
- [Master, Slave1, Slave2]
互相拷贝
// master
ssh-copy-id root@slave1
ssh-copy-id root@slave2
// slave1
ssh-copy-id root@master
ssh-copy-id root@slave2
// slave2
ssh-copy-id root@master
ssh-copy-id root@slave1
- 测试均免密通过才算配置正确, 否则一定要检查原因并排除
ssh root@localhost
ssh root@other_server
启动
[Master]
hdfs namenode -format
/usr/local/hadoop-3.0.0.beta1/sbin/start-all.sh
WEB管理界面

可能问题
- 防火墙没关
systemctl stop firewalld.service
systemctl disable firewalld
- SELinux没关
- 执行mapreduce任务报错
# hadoop classpath // 找到hadoop的classpath
# vi yarn-site.xml
// 在里面补
yarn.application.classpath
XXXX
参考 http://www.jianshu.com/p/b49712bbe044