mysql学习笔记(持续更新中)
MySql学习笔记
文章目录
- **MySql学习笔记**
- 显示数据库及表
- 显示当前使用的数据库列表
- 显示当前使用的数据库表列表
- 数据库的新建和删除
- 新建数据库
- 删除数据库
- 选择数据库
- 当前当前所在数据库
- 查看当前数据库表的状态
- mysql的数据类型
- 数值类型
- 日期时间型
- 字符串类型
- 数据库表的新建和删除
- 新建数据库表
- 为表添加约束
- 主关键字
- 外关键子
- 检查约束
- 默认值
- 自增列
- 显示所有元素
- 查看表结构
- 清空表数据
- 修改表结构
- 添加列
- 删除列
- 修改类型(修改列)
- 添加主键
- 删除主键
- 添加一个列的唯一属性
- 修改自增列
- 外键的添加和删除
- 增加外键
- 删除外键
- 默认值的修改和删除
- 修改默认值:
- 删除默认值:
- 修改字符集(编码)
- 设置存储引擎
- 数据操作
- 插入数据
- 插入一条数据
- 一次插入多条数据
- 注意
- 更新数据
- 注意
- Example
- 表单查询
- 基础查询
- 高级查询where
- 条件查询
- 通配符
- %(多个字符匹配)
- _(单个字符匹配)
- 限制
- 获取前 几 行记录
- 从第 m 行开始, 取出 n 行, 包含第 m 行
- 排序(order by)
- 升序(默认为升序)
- 降序
- 综合排序
- 分组(group by)
- 嵌套查询
- 多表查询
- 连表
- 企业通用方法
- Mysql JOIN 语法
- 语法总结
- 删除数据
- 语法总结
- 更新(修改) update
- 语法总结
- 删除 delete
- 语法总结
- 删除表,表将消失
- 语法总结
- 复制表结构
- 语法总结
- MySql索引
- 索引的作用
- MySQL中常见索引有:
- 普通索引
- 功能
- 建立方法
- 创建表的同时创建索引
- 单独创建索引
- 查看索引
- 删除索引
- 唯一索引
- 功能
- 建立方法
- 创建表和唯一索引
- 创建唯一索引
- 删除唯一索引
- 主键索引
- 功能
- 建立方法
- 创建表和创建主键
- 组合索引
- 功能
- 一些相关的操作实例
- B树索引类型的联合索引使用限制
- 有效使用方式
- SQl 执行
- 索引过多的缺点
- MySQL 安全控制
- 用户管理
- 创建用户
- 删除用户
- 修改用户
- 修改密码
- 第一种方法
- 第二种方法
- 第三种方法(忘记密码时,必须使用此方法修改密码):
- 使用注意:
- 权限管理
- 授权并设置密码
- 取消权限
- 查看授权信息
- 查看生效的授权信息
- **关于权限**
- **关于数据库和表**
- **关于用户和 IP**
- **Example**
- **立刻生效**
- MySQL 备份
- 备份概述
- 备份的种类
- 在线与离线备份
- MySQL 逻辑备份 mysqldump
- 逻辑备份特点
- 特点
- 用法
- 日常用法
- 优势
- 恢复
- MySQL 物理备份: Innobackupex 和 xtrabackup(热备)
- 安装与安装
- 使用 `YUM` 方式安装
- 下载对应版本的软件包,在本地安装
- 卸载
- 80 版本安装方法
- 报错解决
- 日常操作
- 备份
- 全备
- 增量备份
- 启用压缩备份
- 创建加密备份
- 部分备份
- 在本地执行备份,并且备份到远程服务器
- 操作步骤
- 1. 建立`DB1` 到 `BK1` 的信任关系
- 2. 在 `DB1` 中安装支持多线程压缩和压缩算法的软件
- 3. 在 `DB1` 中执行备份命令
- 在本地执行备份,并且备份到远程服务器
- 操作步骤
- 1. 建立`DB1` 到 `BK1` 的信任关系
- 2. 在 `DB1` 中安装支持多线程压缩和压缩算法的软件
- 3. 在 `DB1` 中执行备份命令
显示数据库及表
显示当前使用的数据库列表
-
show databases;
显示当前使用的数据库表列表
-
show tables;
数据库的新建和删除
新建数据库
-
create database DatabaseName;
删除数据库
-
drop database test01;
选择数据库
-
use DatabaseName;
当前当前所在数据库
-
select database();
查看当前数据库表的状态
-
show table status;
mysql的数据类型
数值类型
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-57G9RbNt-1582008065208)(C:\Users\void\AppData\Roaming\Typora\typora-user-images\image-20200213125849343.png)]
日期时间型
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iiDUbz9i-1582008065209)(C:\Users\void\AppData\Roaming\Typora\typora-user-images\image-20200213130033000.png)]
字符串类型
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uWoFehYM-1582008065209)(C:\Users\void\AppData\Roaming\Typora\typora-user-images\image-20200213130130719.png)]
数据库表的新建和删除
新建数据库表
-
CREATE TABLE table_name (column_name column_type);
为表添加约束
主关键字
- 约束的概念和作用(约束就是检查官,检查数据是否有重复的内容)
- 主键约束作用:保证实体完整性
- PRIMARY KEY是检查两条表中的语句是否有重复
外关键子
- 外键约束作用,保证引用完整性
- references关键字的意思是引用的意思。
检查约束
- 检查约束作用,保证域完整性(其取值范围)
- cheek关键字的意思是要规定其取值范围。输入时超过范围错误。
默认值
- 作用:保证域完整性
- DEFAULT 关键字的默认值
自增列
- 作用:保证实体完整性
- AUTO_INCREMENT是自增列的关键字
显示所有元素
-
select *from tb1;
查看表结构
-
describe tb1;
清空表数据
-
delete from studentstable;
修改表结构
添加列
-
alter table 表名 add 列名 类型
删除列
-
alter table 表名 drop column 列名
修改类型(修改列)
-
alter table 表名 modify column 列名 类型;
添加主键
-
alter table 表名 add primary key(列名);
删除主键
-
alter table 表名 drop primary key;
添加一个列的唯一属性
-
在定义完列之后直接使用 UNIQUE 关键字指定唯一约束,语法规则如下:
<字段名> <数据类型> UNIQUE -
在修改表时添加唯一约束的语法格式为:
ALTER TABLE <数据表名> ADD CONSTRAINT <唯一约束名> UNIQUE(<列名>);
修改自增列
//修改自增属性的列,必须具备主键的属性。
alter table 表名 modify column id int AUTO_INCREMENT;
外键的添加和删除
向从表对一个字段增加外键属性时,从表中的这个字段必须已经存在,且不能有数据。
增加外键
alter table 从表 add constraint 外键名称(形如:FK_从表_主表) foreign key 从表(从表的列名) references 主表(主键列名);
删除外键
alter table 表名 drop foreign key 外键名称
注意
从表的的外键列的属性必须主表的主键列名属性一致。
默认值的修改和删除
修改默认值:
ALTER TABLE testalter_tbl ALTER i SET DEFAULT 1000;
删除默认值:
ALTER TABLE testalter_tbl ALTER i DROP DEFAULT;
修改字符集(编码)
修改数据库字符集:
ALTER DATABASE db_name DEFAULT CHARACTER SET character_name [COLLATE ...];
把表默认的字符集和所有字符列(CHAR,VARCHAR,TEXT)改为新的字符集:
ALTER TABLE tbl_name CONVERT TO CHARACTER SET character_name [COLLATE ...]
例如:
ALTER TABLE logtest CONVERT TO CHARACTER SET utf8 COLLATE utf8_general_ci;
查看数据库字符集:
SHOW CREATE DATABASE db_name;
查看表字符集:
SHOW CREATE TABLE tbl_name;
设置存储引擎
MySQL 5.7中
ENGINE = INNODB是数据库默认的
- 配置文件
my.cnf中指定数据库服务器默认存储引擎
default-storage-engine=InnoDB
- 创建新表时,可以通过向语句添加ENGINE表选项来 指定要使用的存储引擎
CREATE TABLE t3 (i INT) ENGINE = MEMORY
- 修改一个表的存储引擎
ALTER TABLE t ENGINE = InnoDB;
数据操作
插入数据
插入一条数据
insert into 表 (列名,列名...) values (值,值,值...)
一次插入多条数据
insert into 表 (列名,列名...) values (值,值,值...),(值,值,值...)
注意
- 按“行”插入
- “字段”和“值”之间,一一对应
- 值的形式:数字直接写,字符串和时间加单引号,但如果是函数值,则不能加引号
- auto_increment, timestamp等字段无需插入
更新数据
update 表名 set 字段名1=值表达式1,字段名2=值表达式2,....[where条件] [order排序] [limit限定];
注意
- 以“行”为单位进行的,可以指定只更新其中的部分字段
- 其他限定遵循
insert语法
Example
#新建数据库
create database School;
#选择数据库
use School;
#新建表
create table calss(
id int not null auto_increment,
name varchar(10),
primary key (id)
);
create table teacher(
id int not null auto_increment,
name varchar(10),
age int default 0,
phone char(11) default '照片',
primary key (id)
);
create table student(
id int auto_increment primary key ,
name varchar(10),
age int,
class_id int,
foreign key (class_id)references calss(id)
);
create table class2teacher(
id int auto_increment primary key ,
class_id int,
teacher_id int,
foreign key (class_id) references calss(id),
foreign key (teacher_id)references teacher(id)
);
#插入数据
insert into calss(name)values
('云计算1810'),
('云计算1901'),
('云计算1902');
insert into teacher(name, age, phone) values
('奇哥', 18, '13733878989'),
('强哥', 28, '15633878989'),
('磊哥', 30, '13933878989'),
('闫老师', 18, '13633878989');
insert into student(name, age, class_id) values
('黛玉', 18, 3),
('钦文', 19, 3),
('马邦德', 30, 1),
('九筒', 48, 1),
('六子', 36, 2),
('汤师爷', 18, 2),
('麻匪', 18,2),
('黛玉', 18,2);
insert into class2teacher(class_id,teacher_id) values
(1,1),(1,2),(2,1),(2,2),(2,3),(3,1),(3,3);
表单查询
基础查询
select * from 表;
select * from 表 where 查询条件;
select 字段名 as 查询别名 from 表 where 查询条件;
高级查询where
条件查询
select * from student where id > 1 and name != '王麻子' and age = 18;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qmmqawJm-1582008065210)(C:\Users\void\AppData\Roaming\Typora\typora-user-images\image-20200215144156268.png)]
select * from student where id between 5 and 16;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0CrWNNOY-1582008065211)(C:\Users\void\AppData\Roaming\Typora\typora-user-images\image-20200215144612908.png)]
select * from student where id in (1,3,5);
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6FpEktPG-1582008065211)(C:\Users\void\AppData\Roaming\Typora\typora-user-images\image-20200215144817919.png)]
select * from student where not id in (1,3,5);
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TPHq4jcP-1582008065212)(C:\Users\void\AppData\Roaming\Typora\typora-user-images\image-20200215145008450.png)]
select * from student where id % 2 != 0;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-x5F5zLiU-1582008065213)(C:\Users\void\AppData\Roaming\Typora\typora-user-images\image-20200215145159005.png)]
select * from student where not id % 2 != 0;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4Ab628yk-1582008065214)(C:\Users\void\AppData\Roaming\Typora\typora-user-images\image-20200215145253480.png)]
select * from calss where id in (select id from student);
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-APw4O5vt-1582008065215)(C:\Users\void\AppData\Roaming\Typora\typora-user-images\image-20200215145510027.png)]
通配符
%(多个字符匹配)
select * from student where name like'sha%';
_(单个字符匹配)
select * from student where name like 'shar_'
限制
获取前 几 行记录
select * from student limit 5;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sQGMWX42-1582008065215)(C:\Users\void\AppData\Roaming\Typora\typora-user-images\image-20200215150821183.png)]
从第 m 行开始, 取出 n 行, 包含第 m 行
select * from student limit 0,6;
select * from student limit 6 offset 0;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-C4wY5WTe-1582008065216)(C:\Users\void\AppData\Roaming\Typora\typora-user-images\image-20200215151126392.png)]
排序(order by)
升序(默认为升序)
select * from student order by age asc; select * from student order by age;[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jpmdME7o-1582008065216)(C:\Users\void\AppData\Roaming\Typora\typora-user-images\image-20200215152703973.png)]
降序
select * from student order by age desc;[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QA5HBdZM-1582008065217)(C:\Users\void\AppData\Roaming\Typora\typora-user-images\image-20200215152848252.png)]
综合排序
select * from student order by age desc,class_id asc;[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6iXN1ZOl-1582008065218)(C:\Users\void\AppData\Roaming\Typora\typora-user-images\image-20200215153110740.png)]
分组(group by)
select * from student group by age;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WSiqvi3F-1582008065218)(C:\Users\void\AppData\Roaming\Typora\typora-user-images\image-20200215154001972.png)]
注意:
分组成功后只会去显示其分组后的第一条记录
select * from student group by class_id,age;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PzOBHFtY-1582008065220)(C:\Users\void\AppData\Roaming\Typora\typora-user-images\image-20200215194344460.png)]
select * from student where age>19 group by age order by age;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fsLytaiV-1582008065222)(C:\Users\void\AppData\Roaming\Typora\typora-user-images\image-20200215194813226.png)]
注意:
group by 必须在where之后,order by之前
select age,id,count(*),sum(age),max(age),min(age) from student group by age,id;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-M9DO7OKg-1582008065223)(C:\Users\void\AppData\Roaming\Typora\typora-user-images\image-20200215195506645.png)]
select * from student group by age having max(id) <10;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5F7luTOJ-1582008065224)(C:\Users\void\AppData\Roaming\Typora\typora-user-images\image-20200215200035331.png)]
嵌套查询
select * from(select name from student where age>18 and age < 25 order by id desc limit 2 )as tt;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9w0C0Dvi-1582008065225)(C:\Users\void\AppData\Roaming\Typora\typora-user-images\image-20200215200307035.png)]
多表查询
连表
企业通用方法
-
查询到 每个班级的所有学员的姓名
select calss.name,student.name from calss,student where student.class_id=class_id; -
查询到 云计算1901班级的所有学员的姓名
select calss.name,student.name from calss,student where student.class_id='云计算1901' and student.class_id=class_id;
-
查询到 马邦德 是哪个班级的
select student.name as user,calss.name as users from student,calss where student.name='马邦德' and student.class_id=class_id; -
查询老师 奇哥 都负责哪些班级
select t.name,c.name from teacher as t ,calss as c,class2teacher c2t where t.name='奇哥' and c2t.teacher_id=t.id and c2t.class_id=c.id;
Mysql JOIN 语法
-
表的连接- 无对应关系则不显示
select A.name,B.name from calss as A,teacher as B where A.id=B.id;建立链接,对应关系的连在一起,无对应关系的不会显示
-
内连接- 无对应关系则不显示
select A.name,B.name from calss as A inner join teacher as B where A.id=B.id;以上两种方式得到结果相同
-
左连接- 左边的表(A)所有显示,如果右边的表(B)中无对应关系,则值为null
select A.name,B.name from calss as A left join teacher AS B on A.id=b.id; -
右连接-右边的(B)表所有显示,如果左边的表(A)中无对应关系,则值为 NULL
SELECT A.name,B.name from calss as A right join teacher as B on a.name=B.id;
语法总结
/*无对应关系则不显示*/
select A.class_name, B.name
from class as A, teacher as B
Where A.id = B.class_id
/* 内连接 无对应关系则不显示*/
select A.class_name, B.name
from class as A inner join teacher as B
on A.id = B.class_id
/* 左连接 左边的表(A)所有显示,如果右边的表(B)中无对应关系,则值为null*/
select A.class_name, B.name
from class as A left join teacher as B
on A.id = B.class_id
/* 右连接 右边的(B)表所有显示,如果左边的表(A)中无对应关系,则值为 NULL*/
select A.name, B.name
from class as A right join teacher as B
on A.id = B.class_id
删除数据
语法总结
delete from 表名 [where 条件] [order by 排序的字段 [desc 取反]] [limit 限定的行数];
- “以行为单位”删除
- 删除语句中,where条件如果不写,则就删除了所有数据
- order排序子句用于设定删除数据的先后顺序
- limit限定子句用于限定在设定的顺序情况下删除指定的某些行
drop 直接删掉表
truncate 删除表中数据,再插入时自增长id又从1开始
delete 删除表中数据,可以加where字句, 增长 id 会继续增长。
(1)DELETE语句执行删除的过程是每次从表中删除一行,并且同时将该行的删除操作作为事务记录在日志中保存以便进行进行回滚操作。TRUNCATE TABLE则一次性地从表中删除所有的数据并不把单独的删除操作记录记入日志保存,删除行是不能恢复的。并且在删除的过程中不会激活与表有关的删除触发器。执行速度快。
(2) 表和索引所占空间。当表被TRUNCATE后,这个表和索引所占用的空间会恢复到初始大小,而DELETE操作不会减少表或索引所占用的空间。drop语句将表所占用的空间全释放掉。
(3) 一般而言,drop > truncate > delete
(4) 应用范围。TRUNCATE只能对TABLE;DELETE可以是table和view(视图)
(5)TRUNCATE和DELETE只删除数据,而DROP则删除整个表(结构和数据)。
(6)truncate与不带where的delete:只删除数据,而不删除表的结构(定义)drop语句将删除表的结构被依赖的约束(constrain),触发器(trigger)索引(index);依赖于该表的存储过程/函数将被保留,但其状态会变为:invalid。
(7)delete语句为DML(data maintain Language),这个操作会被放到rollback segment中,事务提交后才生效。如果有相应的tigger,执行的时候将被触发。
(8)truncate、drop是DLL(data define language),操作立即生效,原数据不放到 rollback segment中,不能回滚
(9) 在没有备份情况下,谨慎使用drop与truncate。要删除部分数据行采用delete且注意结合where来约束影响范围。回滚段要足够大。要删除表用drop;若想保留表而将表中数据删除,如果于事务无关,用truncate即可实现。如果和事务有关,或老师想触发trigger,还是用delete。
(10)Truncate table表名 速度快,而且效率高,因为:
truncate table 在功能上与不带 WHERE 子句的DELETE语句相同:二者均删除表中的全部行。但TRUNCATE TABLE比DELETE速度快,且使用的系统和事务日志资源少。DELETE语句每次删除一行,并在事务日志中为所删除的每行记录一项。TRUNCATE TABLE通过释放存储表数据所用的数据页来删除数据,并且只在事务日志中记录页的释放。
(11)TRUNCATE TABLE删除表中的所有行,但表结构及其列、约束、索引等保持不变。新行标识所用的计数值重置为该列的种子。如果想保留标识计数值,请改用DELETE。如果要删除表定义及其数据,请使用DROP TABLE 语句。
(12) 对于由FOREIGN KEY约束引用的表,不能使用TRUNCATE TABLE,而应使用不带WHERE子句的DELETE语句。由于TRUNCATE TABLE不记录在日志中,所以它不能激活触发器。
更新(修改) update
语法总结
update 表名 set 字段名1=值表达式1,字段名2=值表达式2,....[where条件] [order排序] [limit限定];
以“行”为单位进行的,可以指定只更新其中的部分字段
其他限定遵循insert语法
删除 delete
语法总结
清空表的内容,表本身还在。
delete from 表名 /*自增列的值继续递增,可以加 where 子句*/
truncate table 表名 /*自增列的值重新从 1 开始*/
/*删除表中的所有数据,自增列的值继续递增*/
delete from tb1;
/*删除表中的某些数据,被删除的数据的自增列的值将不会再次出现,自增列的值继续递增*/
delete from tb1 where id < 20;
删除表,表将消失
语法总结
drop table 表名 /*整个表将不复存在*/
复制表结构
语法总结
-- 清空表数据
TRUNCATE [TABLE] 表名
-- 复制表结构
CREATE TABLE 表名 LIKE 要复制的表名
-- 复制表结构和数据
CREATE TABLE 表名 [AS] SELECT * FROM 要复制的表名
-- 检查表是否有错误
CHECK TABLE tbl_name [, tbl_name] ... [option] ...
-- 优化表
OPTIMIZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ...
-- 修复表
REPAIR [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ... [QUICK] [EXTENDED] [USE_FRM]
-- 分析表
ANALYZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name]
MySql索引
索引的作用
索引用于快速查找具有特定列值的行。如果没有索引,MySQL必须从第一行开始,然后读取整个表以查找相关行。表越大,成本越高。如果表中有相关列的索引,MySQL可以快速确定要在数据文件中间寻找的位置,而无需查看所有数据。这比按顺序读取每一行要快得多。
类似于字典中的目录,查找字典内容时可以根据目录查找到数据的存放位置,然后直接获取即可。
本质上是告诉数据库的存储引擎如何快速找到我们所要的数据。所以 MySQL 的索引是在 MySQL 的存储引擎层实现的,而不是在其服务器层实现。
MySQL中常见索引有:
普通索引
功能
普通索引仅有一个功能:加速查询
建立方法
创建表的同时创建索引
create table t1(
id int not null auto_increment primary key,
name varchar(32),
email varchar(64),
extra text,
index ix_name(name)
/*添加索引到列名 name, 索引名为 ix_name*/
)
单独创建索引
create index index_name on 表名称(列名称)
Example
create index index_name on student(name);
查看索引
show index from 表名称;
Example
show index from student;
删除索引
DROP INDEX index_name on 表名称;
Example
DROP INDEX index_name on student;
唯一索引
功能
加速查询 和 唯一约束(可含null)
建立方法
创建表和唯一索引
create table t2(
id int not null auto_increment primary key,
name varchar(32),
email varchar(64),
unique index ix_name (name)
);
创建唯一索引
create unique index 索引名 on 表名(列名);
删除唯一索引
ALTER TABLE 表名 DROP INDEX 索引名;
主键索引
功能
加速查询 和 唯一约束(不可含null)
当一个列被创建为主键是,它就会被赋予主机索引的属性。
建立方法
创建表和创建主键
create table t3(
id int ,
name varchar(32) ,
email varchar(64) ,
primary key(name)
);
组合索引
功能
联合索引是将n个列联合成一个索引,其应用场景为:频繁的同时使用 n 个列来进行查询,如:where name = ‘shark’ and age = 18。
一些相关的操作实例
create table studens(
id int not null auto_increment primary key,
name varchar(32) not null,
age int not null,
)
create index idx_name_age on students(name,age);
如上创建联合索引之后,查询时可以这么用:
-
name and age – 使用索引
where name='shark' and age=18; -
name – 使用索引
where name='shark';
B树索引类型的联合索引使用限制
-
匹配最左前缀的查询
对于联合索引的使用上需要注意,
where自己的第一个条件的列名必须是组合索引列的最左边的那个。
有效使用方式
where name='shark';
where name='shark' and age>18;
where name = 'shark' and (age >18 or age = 10);
注意:
对于同时搜索n个条件时,组合索引的性能好于多个单一索引合并。
- 匹配列前缀查询
name like 'shark%'
- 匹配范围值查询
name > 'a' and name < 'c'
不可以使用 not in 和 <>
当有 3 列组成的索引时, 使用这个联合索引时,所有的字段不能跳过。
order_sn, order_name,order_date
where order_sn = ‘8998’ and order_date = ‘20191010’;
只能使用到 order_sn 这一个字段度索引,不能使用的 order_sn, order_date 的联合索引
SQl 执行
explain select name from t1 where name='shark'\G
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KNq0PRtV-1582008065225)(C:\Users\void\AppData\Roaming\Typora\typora-user-images\image-20200216131134764.png)]
索引过多的缺点
- 增加写的压力
- 增加 MySQL 查询优化器的选择时间。
MySQL 安全控制
DCL(Data Control Language 数据库控制语言)
用于数据库授权、角色控制等操作
-
GRANT授权,为用户赋予访问权限 -
REVOKE取消授权,撤回授权权限
用户管理
创建用户
create user '用户名'@'客户端来源IP地址' identified by '密码';
删除用户
drop user '用户名'@'客户端来源IP地址';
修改用户
rename user '用户名'@'客户端来源IP地址' to '新用户名'@'客户端来源IP地址' ;
修改密码
第一种方法
set password for '用户名'@'IP地址'=Password('新密码')
第二种方法
alter user '用户名'@'客户端来源IP地址' identified by '新密码';
第三种方法(忘记密码时,必须使用此方法修改密码):
UPDATE mysql.user SET authentication_string=password('QFedu123!') WHERE user='root' and host='localhost';
使用注意:
用户权限相关数据保存在mysql数据库的user表中,所以也可以直接对其进行操作(不建议)
权限管理
授权并设置密码
grant 权限 on 数据库.表 to '用户'@'客户端来源IP地址' identified by '密码';
取消权限
revoke 权限 on 数据库.表 from '用户'@'客户端来源IP地址'
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Eg6BUrQD-1582008065226)(C:\Users\void\Desktop\11414906-cc6bf8a4095296ef.webp)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-O96Vmyw9-1582008065227)(C:\Users\void\Desktop\11414906-b35c753b7ca23306.webp)]
查看授权信息
show grants for '用户'@'客户端来源IP地址';
查看生效的授权信息
针对所有库和表的权限,比如 *.* 。 去 mysql.user 中查看
select * from mysql.user where user='shark'\G
针对具体到库的权限,比如db_name.* 。 去 mysql.db 中查看
select * from mysql.db where user='shark'\G
针对具体表的授权,在 mysql.tables_priv 中查看
select * from mysql.tables_priv where user='shark'\G
假如是 MySQL8.x
CREATE USER '你的用户名'@'localhost' IDENTIFIED BY '你的密码';
#创建新的用户
GRANT ALL PRIVILEGES ON 你的数据库名.* TO '你的用户名'@'localhost';
#把刚刚创建的数据库的管理权限给予刚刚创建的MySQL用户
FLUSH PRIVILEGES;
#刷新权限,使用设置生效
关于权限
参考官方文档
all privileges 除grant外的所有权限
select 仅查权限
select,insert 查和插入权限
...
usage 无访问权限
alter 使用alter table
alter routine 使用alter procedure和drop procedure
create 使用create table
create routine 使用create procedure
create temporary tables 使用create temporary tables
create user 使用create user、drop user、rename user和revoke all privileges
create view 使用create view
delete 使用delete
drop 使用drop table
execute 使用call和存储过程
file 使用select into outfile 和 load data infile
grant option 使用grant 和 revoke
index 使用index
insert 使用insert
lock tables 使用lock table
process 使用show full processlist
show databases 使用show databases
show view 使用show view
update 使用update
reload 使用flush
shutdown 使用mysqladmin shutdown(关闭MySQL)
super 使用change master、kill、logs、purge、master和set global。还允许mysqladmin调试登陆
replication client 服务器位置的访问
replication slave 由复制从属使用
关于数据库和表
对于目标数据库以及内部其他:
数据库名.* 数据库中的所有
数据库名.表 指定数据库中的某张表
数据库名.存储过程 指定数据库中的存储过程
*.* 所有数据库
关于用户和 IP
用户名@IP地址 用户只能在此 IP 下才能访问
用户名@192.168.1.% 用户只能在此 IP 段下才能访问(通配符%表示任意)
用户名@%.shark.com
用户名@% 用户可以再任意IP下访问(默认IP地址为%)
Example
create user 'shark'@'%';
grant all privileges on *.* to 'shark'@'%' identified by '123';
立刻生效
/*将数据读取到内存中,从而立即生效。*/
flush privileges
也可以在创建用户的同时直接授权(mysql8.x 不可以)
grant select on *.* /*设置查询数据的权限在所有的库和表*/
to 'shark_2'@"%" /*指定用户名和来源 ip*/
identified by '123'; /*设置密码*/
MySQL 备份
备份概述
为何要备份
- 由于机器故障导致数据丢失
-
- 主从复制
- 集群
- 把原始数据备份到异地(其他机房或者其他城市)
- 由于人为的误操作导致的数据丢失
- 把原始数据备份到其他媒介上,脱离当前的系统,避免人为的误操作
备份的目的
- 保持数据一致性
- 保障数据可用性
备份的种类
- 物理备份 由目录的原始副本和存储数据库内容的文件组成。此类备份适用于需要在出现问题时快速恢复的大型重要数据库。
- 除数据库外,备份还可以包括任何相关文件,如日志或配置文件。
- 备份仅可移植到具有相同或类似硬件特征的其他计算机。
- 可以在MySQL服务器未运行时执行备份。如果服务器正在运行,则必须执行适当的锁定,以便服务器在备份期间不会更改数据库内容。
- 物理备份工具包括用于表的MySQL Enterprise Backup 的 mysqlbackup
InnoDB或任何其他表,或文件系统级命令(如cp, scp,tar, rsync) - MySQL Enterprise Backup还原
InnoDB以及它备份的其他表。 - 可以使用文件系统命令将在文件系统级别复制的文件复制回其原始位置。
-
- MySQL Enterprise Backup还原
InnoDB以及它备份的其他表。 - ndb_restore恢复
NDB表。 - 可以使用文件系统命令将在文件系统级别复制的文件复制回其原始位置。
- MySQL Enterprise Backup还原
-
- MySQL Enterprise Backup还原
InnoDB以及它备份的其他表。 - ndb_restore恢复
NDB表。 - 可以使用文件系统命令将在文件系统级别复制的文件复制回其原始位置。
- MySQL Enterprise Backup还原
-
- MySQL Enterprise Backup还原
InnoDB以及它备份的其他表。 - ndb_restore恢复
NDB表。 - 可以使用文件系统命令将在文件系统级别复制的文件复制回其原始位置。
- MySQL Enterprise Backup还原
-
- MySQL Enterprise Backup还原
InnoDB以及它备份的其他表。 - ndb_restore恢复
NDB表。 - 可以使用文件系统命令将在文件系统级别复制的文件复制回其原始位置。
- MySQL Enterprise Backup还原
- 逻辑备份 保存表示为逻辑数据库结构(
CREATE DATABASE,CREATE TABLE语句)和内容(INSERT语句或分隔文本文件)的信息。此类备份适用于较少量的数据,您可以在其中编辑数据值或表结构,或在不同的计算机体系结构上重新创建数据。
逻辑备份方法具有以下特征:
- 通过查询MySQL服务器来获取数据库结构和内容信息来完成备份。
- 备份比物理方法慢,因为服务器必须访问数据库信息并将其转换为逻辑格式。如果输出写在客户端,则服务器还必须将其发送到备份程序。
- 输出大于物理备份,特别是以文本格式保存时。
- 备份和还原粒度可在服务器级别(所有数据库),数据库级别(特定数据库中的所有表)或表级别中使用。无论存储引擎如何,都是如此。
- 备份不包括日志或配置文件,或其他不属于数据库的数据库相关文件。
- 以逻辑格式存储的备份与机器无关且具有高度可移植性。
- 在运行MySQL服务器的情况下执行逻辑备份。服务器未脱机。
- 逻辑备份工具包括mysqldump 程序和
SELECT ... INTO OUTFILE语句。这些适用于任何存储引擎,甚至MEMORY。 - 要恢复逻辑备份,可以使用mysql客户端处理SQL格式转储文件。要加载分隔文本文件,请使用
LOAD DATA INFILE语句或 mysqlimport客户端
在线与离线备份
在MySQL服务器运行时进行联机备份,以便可以从服务器获取数据库信息。服务器停止时会发生脱机备份。这种区别也可以描述为“ 热 ”与 “ 冷 ”备份; 一个“ 温暖 ”的备份是一个在服务器保持运行,但锁定,以防止当你从外部访问数据库文件修改数据。
MySQL 逻辑备份 mysqldump
逻辑备份特点
- 备份的是建表、建库、插入等操作所执行SQL语句(DDL DML DCL),适用于中小型数据库。
- 效率相对较低
在日常工作中,我们会使用 mysqldump 命令创建SQL格式的转储文件来备份数据库。或者我们把数据导出后做数据迁移,主从复制等操作。mysqldump是一个逻辑备份工具,复制原始的数据库对象定义和表数据产生一组可执行的SQL语句。 默认情况下,生成insert语句,也能生成其它分隔符的输出或XML格式的文件。
特点
- 自动记录position位置。
show master status\G;
- 可用性,一致性
锁表机制
用法
mysqldump -h 服务器 -u用户名 -p密码 数据库名 > 备份文件.sql
/*查看帮助*/
mysqldump --help
日常用法
备份所有库
// 先配置用户名和密码
shell> vi ~/.mysql_user
[mysqldump]
user=root
password=123
shell> mysqldump --defaults-file=~/.mysql_user -h172.16.153.10 --all-databases > `date +%FT%H_%M_%S`dump_all.sql
# 不包含 INFORMATION_SCHEMA,performance_schema,sys
备份指定的多个库
// 为了考虑篇幅,请自行添加指定用户名密码参数和指定服务器的参数
// --defaults-file=~/.mysql_user -hip
shell> mysqldump --databases db1 db2 db3 > `date +%FT%H_%M_%S`dump_all.sql
备份指定库的指定几个表
shell> mysqldump db1 t1 t3 t7 > dump.sql
备份时不锁表
备份时希望转储和刷新日志到恰好在同一时刻发生,适用于 InnoDB 引擎
shell> mysqldump --all-databases --single-transaction --flush-logs > `date +%FT%H_%M_%S`dump_all.sql
–flush-logs 在开始备份数据之前刷新MySQL服务器日志文件。
此选项需要 RELOAD权限。如果将此选项与选项结合使用 --all-databases,则会为每个转储的数据库刷新日志。会锁表。–single-transaction 是针对 InnoDB 引擎的表,不锁表,也称热备。
其他参数
-
–master-data=0|1|2
服务器的二进制日志必须打开
0 不记录二进制日志文件及位置:
1 以CHANGE MASTER TO 的方式记录位置,可用于恢复后直接启动从服务器:
2 以CHANGE MASTER TO 的方式记录位置,但默认被注释:
-
–dump-slave 用于在slave上dump数据,建立新的slave。因为我们在使用mysqldump时会锁表,所以大多数情况下,我们的导出操作一般会在只读备库上做,为了获取主库的Relay_Master_Log_File(二进制日志)和Exec_Master_Log_Pos(主服务器二进制日志中数据所处的位置),需要用到这个参数,不过这个参数只有在5.7以后的才会有
-
–no-data, -d 不导出任何数据,只导出数据库表结构
-
–lock-all-tables:锁定所有表 对MyISAM引擎的表开始备份前,先锁定所有表。
优势
mysqldump的优势:
- 可以查看或者编辑十分方便,它也可以灵活性的恢复之前的数据。
- 不关心底层的存储引擎,既适用于支持事务的,也适用于不支持事务的表。
- 不过它不能作为一个快速备份大量的数据或可伸缩的解决方案。如果数据库过大,即使备份步骤需要的时间不算太久,但有可能恢复数据的速度也会非常慢,因为它涉及的SQL语句插入磁盘I/O,创建索引等等。 对于大规模的备份和恢复,更合适的做法是物理备份,复制其原始格式的数据文件,可以快速恢复。
恢复
shell> mysql < dump.sql
或者,在mysql中,使用 source命令:
mysql> source dump.sql
如果文件是不包含CREATE DATABASE和 USE语句的单数据库转储 ,请首先创建数据库(如有必要):
shell> mysqladmin create db1
然后在加载转储文件时指定数据库名称:
shell> mysql db1 < dump.sql
或者,在mysql中创建数据库,将其选为默认数据库,然后加载转储文件:
mysql> CREATE DATABASE IF NOT EXISTS db1;
mysql> USE db1;
mysql>source dump.sql
Example
shell> mysql --defaults-file=~/.mysql_user < /backup/2016-12-08-04-mysql-all.sql
MySQL 物理备份: Innobackupex 和 xtrabackup(热备)
Percona XtraBackup是一款基于MySQL的热备份的开源实用程序,它可以备份5.1到5.7版本上InnoDB,XtraDB,MyISAM存储引擎的表, Xtrabackup有两个主要的工具:xtrabackup、innobackupex 。
原来的版本
(1)xtrabackup 只能备份InnoDB和XtraDB两种数据引擎的数据表,而不能备份MyISAM数据表
(2)innobackupex 则封装了 xtrabackup,是一个脚本封装,所以能同时备份处理innodb和myisam,但在处理myisam时需要加一个读锁。
新版本的变化
如果你安装了2.3之前版本的xtrabackup,那么在备份的过程中,你可能会用到两个常用的备份工具。
安装2.3版本之前的XtraBackup后,我们会得到两个主要的备份工具:
- xtrabackup
- innobackupex
xtrabackup是一个C程序。
innobackupex是一个perl脚本,它对xtrabackup这个C程序进行了封装,在备份innodb表时,此脚本会调用xtrabackup这个C程序。
如果使用xtrabackup这个C程序进行备份,则只能备份innodb和xtradb的表,不能备份myisam表。
如果使用innobackupex进行备份,则可以备份innodb或xtradb的表,同时也能够备份myisam表。
所以,一般在使用XtraBackup备份工具进行数据备份时,通常会选择使用innobackupex命令进行备份。
那么问题来了。
xtrabackup是一个C程序,innobackupex是一个perl脚本,当它们作为两个进程运行时,总是没有特别完美的方式让它们进行通讯,当它们作为一个整体进行工作时就不太尽如人意,如此情况,就导致了一些bug的出现,于是,官方决定使用C重写innobackupex,将它与xtrabackup这个C程序完美的整合在一起。这个想法在2.3版本的XtraBackup中实现。
官方手册解释
xtrabackup
一个已编译的C二进制文件,它提供了使用MyISAM,InnoDB和XtraDB表备份整个MySQL数据库实例的功能
而我们安装的就是2.4版本,此时,innobackupex的功能已经完全整合到了xtrabackup中,innobackupex不再是perl脚本了,但是,为了兼容之前用户的使用习惯,官方保留了innobackupex,它作为一个软连接,指向了xtrabackup,也就是说,在2.4版本中,不管我们使用innobackupex命令,还是xtrabackup命令,其实使用的都是这个xtrabackupC程序。虽然在实现上有所不同,但是在工作原理上,与之前的版本并没有什么不同。
下面我们用新的命令xtrabachup使用。
首先我们先来简单的了解一下xtrabackup 是怎么工作的。xtrabackup 基于innodb的crash-recovery(实例恢复)功能,先copy innodb的物理文件(这个时候数据的一致性是无法满足的),然后进行基于redo log进行恢复,达到数据的一致性。
安装与安装
使用 YUM 方式安装
地址
https://www.percona.com/downloads/XtraBackup/LATEST/
- 确保安装 EPEL 源
yum install https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
- 安装
libev
为了成功安装Percona XtraBackup libev包需要先安装。
yum install -y libev
- 安装Percona存储库
yum install https://repo.percona.com/yum/percona-release-latest.noarch.rpm
- 测试存储库的可用性
shell> yum list | grep percona
应该输出如下信息
...
percona-xtrabackup-20.x86_64 2.0.8-587.rhel5 percona-release-x86_64
percona-xtrabackup-20-debuginfo.x86_64 2.0.8-587.rhel5 percona-release-x86_64
percona-xtrabackup-20-test.x86_64 2.0.8-587.rhel5 percona-release-x86_64
percona-xtrabackup-21.x86_64 2.1.9-746.rhel5 percona-release-x86_64
percona-xtrabackup-21-debuginfo.x86_64 2.1.9-746.rhel5 percona-release-x86_64
percona-xtrabackup-22.x86_64 2.2.13-1.el5 percona-release-x86_64
percona-xtrabackup-22-debuginfo.x86_64 2.2.13-1.el5 percona-release-x86_64
percona-xtrabackup-debuginfo.x86_64 2.3.5-1.el5 percona-release-x86_64
percona-xtrabackup-test.x86_64 2.3.5-1.el5 percona-release-x86_64
percona-xtrabackup-test-21.x86_64 2.1.9-746.rhel5 percona-release-x86_64
percona-xtrabackup-test-22.x86_64 2.2.13-1.el5 percona-release-x86_64
...
- 安装软件
shell> yum install percona-xtrabackup-24
-
验证安装
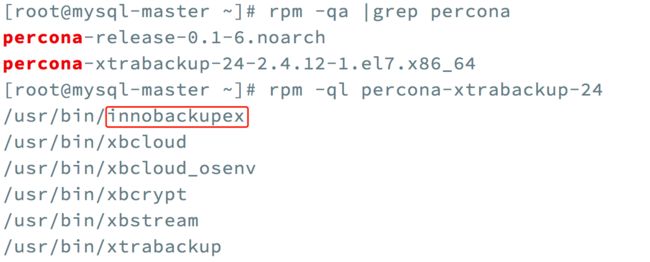
image.png
下载对应版本的软件包,在本地安装
点击 下载页面,选择对应版本后进行下载
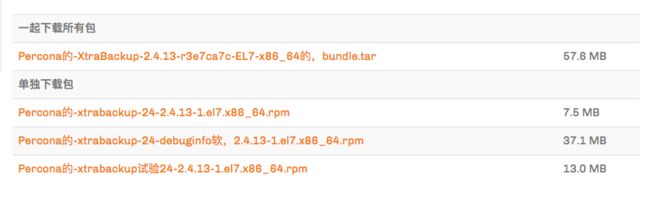
image.png
示例:
下载 2.4.4版本
wget https://www.percona.com/downloads/XtraBackup/Percona-XtraBackup-2.4.4/binary/redhat/7/x86_64/percona-xtrabackup-24-2.4.4-1.el7.x86_64.rpm
安装
yum localinstall percona-xtrabackup-24-2.4.4-1.el7.x86_64.rpm
注意:像这样手动安装软件包时,您需要确保解决所有依赖项并自行安装缺少的软件包。
卸载
yum remove percona-xtrabackup
80 版本安装方法
注意:
这个版本只支持 MySQL8.0的数据进行备份,不支持 MySQL8.0版本之前的数据进行备份。
# 安装仓库文件
yum install https://repo.percona.com/yum/percona-release-latest.noarch.rpm
# 启用仓库
percona-release enable-only tools release
#安装软件
yum install percona-xtrabackup-80
报错解决
来自 file:///etc/pki/rpm-gpg/RPM-GPG-KEY-percona 的无效 GPG 密钥:No key found in given key data
或者
源 "CentOS 7 - Percona" 的 GPG 密钥已安装,但是不适用于此软件包。请检查
源的公钥 URL 是否配置正确。
失败的软件包是:Percona-Server-shared-56-5.6.43-rel84.3.el7.x86_64
GPG 密钥配置为:file:///etc/pki/rpm-gpg/RPM-GPG-KEY-percona
修改仓库文件 percona-release.repo 不使用密钥认证
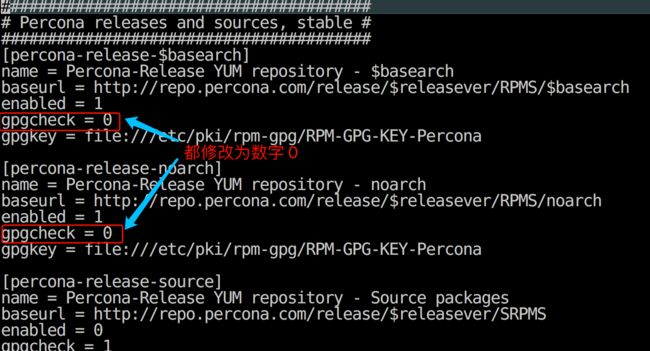
image.png
再次安装会看到如下报错信息
Transaction check error:
file /etc/my.cnf from install of Percona-Server-shared-56-5.6.43-rel84.3.el7.x86_64 conflicts with file from package mysql-community-server-5.7.25-1.el7.x86_64
错误概要
-------------
需要安装如下软件
yum install -y mysql-community-libs-compat
注意:
这个软件的源是mysql57-community
[mysql57-community]
name=MySQL 5.7 Community Server
baseurl=http://repo.mysql.com/yum/mysql-5.7-community/el/7/$basearch/
enabled=1
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-mysql
/etc/pki/rpm-gpg/RPM-GPG-KEY-mysql 文件内容如下:
点我传送门
- 再执行安装命令
yum install percona-xtrabackup-24
日常操作
条件:
- 在 MySQL 服务器本地安装 Xtrbackup 并执行相关操作。
- 给执行备份到用户进行相应的授权。
配置选项
配置选项可以在sh命令行中直接使用,也可以在 my.cnf 文件中配置
# my.cnf 文件的配置
[xtrabackup]
target_dir = /data/backups/mysql/ # 备份数据放置的位置
假如是编译安装的 mysql ,需要在配置文件my.cnf 中指定 socket 文件的路径。
[xtrabackup]
socket = /tmp/mysql.sock
备份
全备
下面的命令均假设没有在 my.cnf 中配置任何关于 xtrabackup 的选项
要执行备份需要指定 备份数据放置的位置,就是目录,假如目录不存在,则会自动创建;==注意这个目录不会被递归创建,仅仅会创建最后一级目录;==假如存在,就会直接开始备份,并且不会覆盖原来的数据。
- 开始备份
shell> xtrabackup --backup --user=root --password='123' --target-dir=/backups/full
# 备份完成后,可以看到备份时的LSN号,当下次进行增量备份时,xtrabackup就只备份大于此号的page即可。
- 查看备份文件
[root@mysql-master ~]# ls -lh /backups/full
总用量 13M
-rw-r----- 1 root root 487 8月 18 09:44 backup-my.cnf
-rw-r----- 1 root root 293 8月 18 09:44 ib_buffer_pool
-rw-r----- 1 root root 12M 8月 18 09:44 ibdata1
drwxr-x--- 2 root root 4.0K 8月 18 09:44 mysql
drwxr-x--- 2 root root 88 8月 18 09:44 one_db
drwxr-x--- 2 root root 8.0K 8月 18 09:44 performance_schema
drwxr-x--- 2 root root 58 8月 18 09:44 shark_db
drwxr-x--- 2 root root 8.0K 8月 18 09:44 sys
-rw-r----- 1 root root 115 8月 18 09:44 xtrabackup_checkpoints
-rw-r----- 1 root root 446 8月 18 09:44 xtrabackup_info
-rw-r----- 1 root root 2.5K 8月 18 09:44 xtrabackup_logfile
进入目录后,可以看到一些目录,这些目录与我们数据库的名称相同,没错,这些就是各个数据库的数据文件备份目录。
还有一个innodb的共享表空间文件,ibdata1,注意,如果想要使用xtrabackup备份众多数据库中的某一个,那么必须保证在创建这个数据库时,已经开启了innodb_file_per_table 参数,否则将无法单独备份数据库服务器中的某一个数据库。
除了刚才描述的这些数据文件,xtrabackup还为我们生成了一些文件,我们来看看这些文件都有什么用(不同版本的xtrabackup生成的文件可能不同)。
-
backup-my.cnf
此文件中包含了my.cnf中的一些设置信息,但是,并不是my.cnf中的所有信息都会包含在此文件中,此文件中只包含了备份时需要的信息。 -
xtrabackup_binlog_info
需要开启二进制日志
此文件中记录了备份开始时二进制日志文件的"位置(position)" -
xtrabackup_checkpoints
此文件中记录此次备份属于那种类型的备份,是全量还是增量,备份时起始的LSN号码,结束的LSN号码等信息。 -
xtrabackup_info
本次备份的概要信息,此文件中的信息还是比较全面的。 -
xtrabackup_logfile
记录了备份过程中的日志,在对数据进行prepare时需要通过日志将数据还原成一致的可用的数据。 -
准备恢复的数据
使用 xtrabackup --backup 选项进行备份后,并不能直接使用,首先需要准备它以便还原它。
如果您尝试使用这些数据文件启动 InnoDB,它将检测损坏并自行崩溃,以防止您在损坏的数据上运行。
因为备份出的数据是不一致的,我们需要将同时备份出的事务日志应用到备份中,才能得到一份完整、一致、可用的数据,xtrabackup称这一步操作为prepare,直译过来就是"准备"。
xtrabackup --prepare 步骤使文件在同一时刻内的数据完全一致
shell> xtrabackup --prepare --target-dir=/backups/full
如果你要备份的数据量巨大,那么备份时长会变长,期间备份的事务日志容量有可能会很大。那么,我们可以使用–use-memory选项,加速准备工作的完成,在不指定内存大小的情况下,准备工作默认会占用100MB的内存,如果服务器有一定的空闲内存,那么我们可以让xtrabackup使用指定大小的内存完成准备工作,以提升准备工作完成的速度,示例语句如下。
shell> xtrabackup --prepare --use-memory=512M --target-dir=/backups/full
准备备份时不建议中断xtrabackup进程,因为这可能会导致数据文件损坏,备份将无法使用。如果准备过程中断,则无法保证备份有效性。
准备备份数据完成后,应该会看到如下信息。
InnoDB: Starting shutdown...
InnoDB: Shutdown completed; log sequence number 13596200
180818 10:09:19 completed OK!
恢复
xtrabackup 在执行copyback时会读取数据库的my.cnf中的配置,但是如果my.cnf中没有配置datadir,那么–datadir选项必须存在,而且,datadir目录必须为空目录,其中不能存在数据,否则在执行上述命令时会报错,–copy-back选项对应的目录就是我们准备好的可用数据的目录。
为了能够正常的恢复数据,我们先确定数据库服务已经停止了,而且对应的数据目录中不存在数据,然后进行数据还原工作,删除数据目录中的文件与日志。
- 停止数据库的服务
- 清理环境
- 修改权限
- 启动数据库
shell> systemctl stop mysqld.service
shell> rm -rf /var/lib/mysql/*
shell> xtrabackup --copy-back --datadir=/var/lib/mysql --target-dir=/backups/full
# 下面为完成后的输出结果
180818 10:59:25 [01] ...done
180818 10:59:25 completed OK!
shell> chown mysql.mysql -R /var/lib/mysql
或者使用 rsync 命令
shell> rsync -avrP /data/backup/ /var/lib/mysql/
shell> chown mysql.mysql -R /var/lib/mysql
启动数据库
shell> systemctl start mysqld.service
innobackuper 命令实现
shell> innobackupex --defaults-file=/etc/my.cnf --host=192.168.1.146 --user=root --password=123 /backups/full
shell> nnobackupex --apply-log --use-memory=4G /backup/full/2018-08-17_15-53-11
shell> systemctl stop mysqld.service
shell> rm -rf /var/lib/mysql/*
shell> innobackupex --datadir=/var/lib/mysql --copy-back 2018-08-17_15-53-11
shell> chown mysql.mysql -R /var/lib/mysql
shell> systemctl start mysqld.service
全量备份思路总结
- 执行备份命令
- 指定 数据库的用户名和密码
- 指定 备份目录,注意只可以自动创建最后一级的目录
- 准备备份的数据
- 就是指: --prepare 参数, 保证数据的统一且完整性
- 停服务,并且把 mysql 的数据目录下的所有文件和文件夹清除。
/var/lib/mysql/此目录必须是空的
- 恢复数据
-
- 本质上就是拷贝备份的文件到指定的 mysql 数据目录下
- 修改 mysql 数据目录的属主和属组为 MySQL 服务器进程启动的用户,默认是 mysql
- 启动服务
增量备份
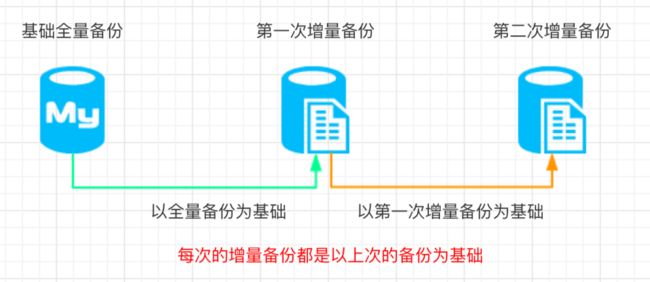
image.png
特点:每次备份,都对自上一次备份(注意是上一次,不是第一次)到此时备份之间有变化的文件,进行备份。所 以备份体积小,备份速度快,但是恢复的时候,需要按备份时间顺序,逐个备份版本进行恢复,恢复时持续的时间长。
无论xtrabackup和innobackupex工具支持增量备份,这意味着它们可以只复制自上次备份以来发生变化的数据。
您可以在每个完整备份之间执行许多增量备份,因此您可以设置备份过程,例如每周一次完整备份和每天增量备份,或每天完整备份和每小时增量备份。
增量备份有效,因为每个InnoDB页面都包含一个日志序列号或LSN。该LSN是整个数据库系统的版本号。每个页面的LSN显示它最近的更改。
当我们做过全量备份以后会在目录下产生xtrabackup_checkpoints的文件 这里面记录了lsn和备份方式,我们可以基于这次的全量做增量的备份。
shell> cat /data/backups/xtrabackup_checkpoints
backup_type = full-prepared
from_lsn = 0
to_lsn = 13593159
last_lsn = 13593168
compact = 0
recover_binlog_info = 0
增量备份实际上并不将数据文件与先前备份的数据文件进行比较。事实上,如果你知道它的LSN,你可以使用 xtrabackup --incremental-lsn来执行增量备份,而不需要先前的备份。增量备份只是读取页面并将其LSN与最后一个备份的LSN进行比较。但是,您仍需要完整备份来恢复增量更改;如果没有完整备份作为基础,增量备份将毫无用处。
创建增量备份
要进行增量备份,请像往常一样以完整备份开始, 使用下面的命令创建基础的全量备份。
shell> xtrabackup --backup --user=root --password=123 --target-dir=/backups/base
现在您已拥有完整备份,以后可以根据它进行增量备份。
向数据库中添加数据,以便于测试
mysql> select count(id) from shark_db.student;
+-----------+
| count(id) |
+-----------+
| 99213 |
+-----------+
1 row in set (0.04 sec)
mysql> insert into shark_db.student (name,age,phone) values('xiguatian',20,13149876789);
Query OK, 1 row affected (0.00 sec)
mysql> select count(id) from shark_db.student;
+-----------+
| count(id) |
+-----------+
| 99214 |
+-----------+
1 row in set (0.03 sec)
使用以下命令进行增量备份:
shell> xtrabackup --backup --user=root --password=123 --target-dir=/data/backups/inc1 --incremental-basedir=/backups/base
该/data/backups/inc1/目录现在应包含增量文件
ls -lh /data/backups/inc1/
总用量 116K
-rw-r----- 1 root root 487 8月 18 11:40 backup-my.cnf
-rw-r----- 1 root root 293 8月 18 11:40 ib_buffer_pool
-rw-r----- 1 root root 64K 8月 18 11:40 ibdata1.delta
-rw-r----- 1 root root 44 8月 18 11:40 ibdata1.meta
drwxr-x--- 2 root root 4.0K 8月 18 11:40 mysql
drwxr-x--- 2 root root 144 8月 18 11:40 one_db
drwxr-x--- 2 root root 8.0K 8月 18 11:40 performance_schema
drwxr-x--- 2 root root 88 8月 18 11:40 shark_db
drwxr-x--- 2 root root 8.0K 8月 18 11:40 sys
-rw-r----- 1 root root 120 8月 18 11:40 xtrabackup_checkpoints
-rw-r----- 1 root root 498 8月 18 11:40 xtrabackup_info
-rw-r----- 1 root root 2.5K 8月 18 11:40 xtrabackup_logfile
这个时候去查看增量备份的xtrabackup_checkpoints,会发现同样也记录了LSN 等信息
shell> cat /backups/inc1/xtrabackup_checkpoints
backup_type = incremental
from_lsn = 13596423
to_lsn = 13596628
last_lsn = 13596637
compact = 0
recover_binlog_info = 0
// 这也意味着你可以在增量的备份上继续增量的备份。
from_lsn是备份的起始LSN,对于增量,它必须与前一个/基本备份的to_lsn(如果它是最后一个检查点)相同。
上面的情况是,to_lsn (上一个检查点LSN)和last_lsn(上次复制的LSN)之间存在差异,这意味着在备份过程中服务器上存在一些流量
模拟增加数据
mysql> insert into shark_db.student (name,age,phone) values('xiguatian3',21,13149876789);
Query OK, 1 row affected (0.01 sec)
mysql> select count(id) from shark_db.student; +-----------+
| count(id) |
+-----------+
| 99215 |
+-----------+
1 row in set (0.03 sec)
现在可以使用此目录作为另一个增量备份的基础:
shell> xtrabackup --backup --user=root --password=123 --target-dir=/backups/inc2 --incremental-basedir=/backups/inc1
准备增量备份的数据
增量备份的步骤与完全备份的步骤不同。在完全备份中,执行两种类型的操作以使数据库保持一致:从日志文件中针对数据文件重播已提交的事务,并回滚未提交的事务。在准备增量备份时,必须跳过未提交事务的回滚,因为备份时未提交的事务可能正在进行中,并且很可能它们将在下一次增量备份中提交。您应该使用该 选项来阻止回滚阶段.
xtrabackup --apply-log-only
警告
如果不使用该 选项来阻止回滚阶段,那么增量备份将毫无用处。回滚事务后,无法应用进一步的增量备份。
要准备数据,需要从一开始就准备,现在回想一下我们都有那些备份
/backups/base
/backups/inc1
/backups/inc2
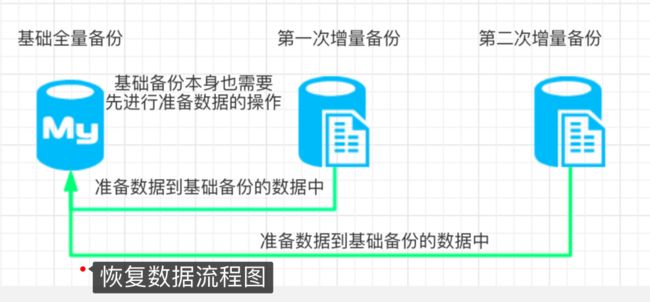
image.png
-
准备基础备份的数据
shell> xtrabackup --prepare --apply-log-only \ --target-dir=/backups/base ...省略... xtrabackup: starting shutdown with innodb_fast_shutdown = 1 InnoDB: Starting shutdown... InnoDB: Shutdown completed; log sequence number 13596441 InnoDB: Number of pools: 1 180818 11:56:55 completed OK!
注意:
即使已跳过回滚阶段,此备份实际上也可以按原样恢复。如果你恢复它并启动MySQL,InnoDB将检测到没有执行回滚阶段,它将在后台执行,因为它通常用于启动时的崩溃恢复。它会通知您数据库未正常关闭。
- 把第一次增量备份的数据合并到基础备份的数据中
shell> xtrabackup --prepare --apply-log-only --user=root --password=123 --target-dir=/backups/base --incremental-dir=/backups/inc1
- 再把第二次增量备份的数据也合并到基础备份的数据中
shell> xtrabackup --prepare --user=root --password=123 --target-dir=/backups/base --incremental-dir=/backups/inc2
注意: 最后一次操作不需要加 --apply-log-only 参数
- 停止 MySQL 服务,并删除数据目录和日志
shell> systemctl stop mysqld
shell> rm -rf /var/lib/mysql/*
- 开始恢复合并后的全部数据的数据库
shell> xtrabackup --copy-back --datadir=/var/lib/mysql --target-dir=/backups/base/
- 更改数据库目录的权限并启动数据库
shell> chown mysql.mysql -R /var/lib/mysql
shell> systemctl start mysqld
启用压缩备份
- 压缩备份使用
--compress
// 压缩备份
shell> xtrabackup --backup --compress --target-dir=/backups/compressed
// 可以同时启用 4 个线程进行压缩
shell> xtrabackup --backup --compress --compress-threads=4 --target-dir=/backups/compressed/
-
准备恢复数据
首先要解压备份文件
安装依赖的软件
shell> wget -d --user-agent="Mozilla/5.0 (Windows NT x.y; rv:10.0) Gecko/20100101 Firefox/10.0"http://www.quicklz.com/qpress-11-linux-x64.tar
shell> tar xvf qpress-11-linux-x64.tar
shell> cp qpress /usr/bin
使用压缩
shell> xtrabackup --decompress --target-dir=/backups/compressed/
// --parallel 参数可以和 --decompress 参数一起使用,可以实现同时解压多个文件
解压后就可以进行准备恢复的数据操作了
shell> xtrabackup --prepare --target-dir=/backups/compressed/
- 恢复数据并更改文件权限
shell> xtrabackup --copy-back --target-dir=/backups/full
shell> chown -R mysql:mysql /var/lib/mysql
创建加密备份
要创建加密的备份需要指定至少两个选项:
--encrypt=ALGORITHM目前支持的算法是:AES128,AES192和AES256--encrypt-key=ENCRYPTION_KEY使用适当长度的加密密钥。如果命令行无法控制访问机器,则不建议使用此选项,因此可以将密钥视为流程信息的一部分。--encrypt-key-file=KEYFILE可以从中读取适当长度的原始密钥的文件的名称。该文件必须是一个简单的二进制(或文本)文件,其中包含要使用的密钥。
- 产生一个加密密钥
[root@mysql-master /]# openssl rand -base64 24
2t3RHNrCZfBNuzdqxCTaI80PS6kkPNVP
// 或者创建一个密钥文件
shell> echo -n "2t3RHNrCZfBNuzdqxCTaI80PS6kkPNVP" >
/data/backups/keyfile
在某些情况下,文本文件可能包含CRLF,这将导致密钥大小增大,从而使其无效。建议的方法是使用以下命令创建文件:
echo -n "GCHFLrDFVx6UAsRb88uLVbAVWbK+Yzfs" > /backups/keyfile
- 创建加密的数据备份
xtrabackup --backup \
--target-dir=/backups \
--encrypt = AES256 \
--encrypt-key="2t3RHNrCZfBNuzdqxCTaI80PS6kkPNVP"
或者
--encrypt-key-file=/data/backups/keyfile
- 解密加密的备份数据
xtrabackup --decrypt=AES256 \
--encrypt-key="2t3RHNrCZfBNuzdqxCTaI80PS6kkPNVP" \
--target-dir=/backups/
或者
--encrypt-key-file=/backups/keyfile
剩余的操作和之前的恢复数据的操作一样
echo -n "GCHFLrDFVx6UAsRb88uLVbAVWbK+Yzfs" > /backups/keyfile
部分备份
xtrabackup支持在启用innodb_file_per_table选项时进行部分备份。创建部分备份有三种方法:
- 将表的名称与正则表达式匹配
- 在文件中提供它们的列表
- 提供数据库列表。
使用--tables 选项
- 创建部分备份
第一种方法是--tables选项。选项的值是一个正则表达式,它与表单中的完全限定的表名(包括数据库名称)相匹配.
比如,仅备份数据库 shark_db中的所有表
shell> xtrabackup --backup \
--user=root \
--password=123 \
--datadir=/var/lib/mysql \
--target-dir=/backups/shark_db_all \
--tables="^shark_db[.].* | ^mysql[.].*|^sys[.].*|^per.*|information_schema[.].*"
仅备份 shark_db.student 表
shell> xtrabackup --backup \
--user=root \
--password=123 \
--datadir=/var/lib/mysql \
--target-dir=/backups/shark_db.student \
--tables="^shark_db[.]student|^mysql[.].*|sys[.].*|^per.*|informatio_schema[.].*"
// 参考默认表名
| information_schema |
| mysql |
| performance_schema |
| sys |
+-----
使用 --tables-file 选项
该--tables-file选项指定一个文件,该文件可以包含多个表名,文件中每行一个表名。仅备份文件中指定的表。名称完全匹配,区分大小写,没有模式或正则表达式匹配。表格名称必须是databasename.tablename格式完全限定的。
shell> echo "mydatabase.mytable" > /tmp/tables.txt
shell> xtrabackup --backup --tables-file=/tmp/tables.txt
使用--databases和--databases-file选项
该--databases选项接受以空格分隔的要备份的数据库和表的列表.
该--databases-file选项指定一个文件,该文件可以包含databasename[.tablename]表单中的多个数据库和表,文件中每行一个元素名称。仅备份命名的数据库和表。名称完全匹配,区分大小写,没有模式或正则表达式匹配。
这两个选项和之前提到的--tables 和 --tables-file 选项是否方式几乎一致。
所不同的是:
talbes 仅可以指定具体的表。
databases 即可以指定数据库名,也可以指定某个数据库中的表。
2.恢复部分备份
在部分备份上使用–prepare选项时,您将看到有关不存在的表的警告。这是因为这些表存在于InnoDB内的数据字典中,但相应的.ibd文件不存在。它们未被复制到备份目录中。
==这些表将从数据字典中删除,当您还原备份并启动InnoDB时,它们将不再存在,==并且不会导致任何错误或警告打印到日志文件中。
因为你之前只备份了部分备份的数据而已,自然恢复的时候不能恢复没有备份的数据。
shell> xtrabackup --prepare --target-dir=/backups/shark_db_all
- 恢复备份文件
方法一:
shell> xtrabackup --copy-back \
--datadir=/var/lib/mysql \
--target-dir=/backups/shark_db_all
// 更改权限
shell> chown mysql.mysql /var/lib/mysql -R
方法二:
适用于没有对 mysql 服务器默认的数据库(msql/sys/performance_schema)备份的情况
a. 初始化数据库
shell> mysqld --initialize --user=mysql
b. 复制文件准备好的备份文件到 mysql 的数据库目录
shell> rsync -avrP /backups/shark_db_all/ /var/lib/mysql/
c. 修改相关文件权限
shell> chown mysql.mysql /var/lib/mysql -R
d. 启动数据库
shell> systemctl start mysqld
e. 找到数据库密码,并登录数据库
shell> grep password /var/log/mysqld.log
shell> mysql -uroot -p # 回车之后,输入在上一步找到的密码
f. 修改数据库密码
mysql> alter user 'root'@'localhost' identified by '123';
在本地执行备份,并且备份到远程服务器
假如目前 MySQL 服务器是 DB1
远程用于备份到服务器是 BK1
操作步骤
1. 建立DB1 到 BK1 的信任关系
shell> ssh-copy-id user@DK1
2. 在 DB1 中安装支持多线程压缩和压缩算法的软件
shell> yum install pigz # 支持多线程压缩
shell> wget -d --user-agent="Mozilla/5.0 (Windows NT x.y; rv:10.0) Gecko/20100101 Firefox/10.0"http://www.quicklz.com/qpress-11-linux-x64.tar
shell> tar xvf qpress-11-linux-x64.tar
shell> cp qpress /usr/bin
3. 在 DB1 中执行备份命令
xtrabackup --backup --user=mysqluser --password=password --stream=xbstream | ssh user@BK1 "cat - > /mysql_backup.tar.gz"
上面命令的意思是,把备份压缩后的文件以数据流的格式传输给 ssh ,并通过 ssh 传输给远程服务器 BK1, 备份后的文件名为 mysql_backup.tar.gz
--user和--password指定的是在 MySQL 服务上经过授权的用户和密码
--stream指定的是采用流格式进行同步压缩
恢复数据
- 先解压
压缩的时候是使用下xb格式的数据流压缩的,所以解压的时候,也需要使用xb工具解压文件到本地硬盘。
mkdir -p /data/xb
xbstream -x < mysql_backup.tar.gz -C /data/xb
- 之后再安装之前的步骤恢复数据
-databases-file选项指定一个文件,该文件可以包含databasename[.tablename]`表单中的多个数据库和表,文件中每行一个元素名称。仅备份命名的数据库和表。名称完全匹配,区分大小写,没有模式或正则表达式匹配。
这两个选项和之前提到的--tables 和 --tables-file 选项是否方式几乎一致。
所不同的是:
talbes 仅可以指定具体的表。
databases 即可以指定数据库名,也可以指定某个数据库中的表。
2.恢复部分备份
在部分备份上使用–prepare选项时,您将看到有关不存在的表的警告。这是因为这些表存在于InnoDB内的数据字典中,但相应的.ibd文件不存在。它们未被复制到备份目录中。
==这些表将从数据字典中删除,当您还原备份并启动InnoDB时,它们将不再存在,==并且不会导致任何错误或警告打印到日志文件中。
因为你之前只备份了部分备份的数据而已,自然恢复的时候不能恢复没有备份的数据。
shell> xtrabackup --prepare --target-dir=/backups/shark_db_all
- 恢复备份文件
方法一:
shell> xtrabackup --copy-back \
--datadir=/var/lib/mysql \
--target-dir=/backups/shark_db_all
// 更改权限
shell> chown mysql.mysql /var/lib/mysql -R
方法二:
适用于没有对 mysql 服务器默认的数据库(msql/sys/performance_schema)备份的情况
a. 初始化数据库
shell> mysqld --initialize --user=mysql
b. 复制文件准备好的备份文件到 mysql 的数据库目录
shell> rsync -avrP /backups/shark_db_all/ /var/lib/mysql/
c. 修改相关文件权限
shell> chown mysql.mysql /var/lib/mysql -R
d. 启动数据库
shell> systemctl start mysqld
e. 找到数据库密码,并登录数据库
shell> grep password /var/log/mysqld.log
shell> mysql -uroot -p # 回车之后,输入在上一步找到的密码
f. 修改数据库密码
mysql> alter user 'root'@'localhost' identified by '123';
在本地执行备份,并且备份到远程服务器
假如目前 MySQL 服务器是 DB1
远程用于备份到服务器是 BK1
操作步骤
1. 建立DB1 到 BK1 的信任关系
shell> ssh-copy-id user@DK1
2. 在 DB1 中安装支持多线程压缩和压缩算法的软件
shell> yum install pigz # 支持多线程压缩
shell> wget -d --user-agent="Mozilla/5.0 (Windows NT x.y; rv:10.0) Gecko/20100101 Firefox/10.0"http://www.quicklz.com/qpress-11-linux-x64.tar
shell> tar xvf qpress-11-linux-x64.tar
shell> cp qpress /usr/bin
3. 在 DB1 中执行备份命令
xtrabackup --backup --user=mysqluser --password=password --stream=xbstream | ssh user@BK1 "cat - > /mysql_backup.tar.gz"
上面命令的意思是,把备份压缩后的文件以数据流的格式传输给 ssh ,并通过 ssh 传输给远程服务器 BK1, 备份后的文件名为 mysql_backup.tar.gz
--user和--password指定的是在 MySQL 服务上经过授权的用户和密码
--stream指定的是采用流格式进行同步压缩
恢复数据
- 先解压
压缩的时候是使用下xb格式的数据流压缩的,所以解压的时候,也需要使用xb工具解压文件到本地硬盘。
mkdir -p /data/xb
xbstream -x < mysql_backup.tar.gz -C /data/xb
- 之后再安装之前的步骤恢复数据