关于VXLAN与异构云之间的集成 ( by quqi99 )
关于VXLAN与异构云之间的集成 ( by quqi99 )
作者:张华 发表于:2013-06-25
版权声明:可以任意转载,转载时请务必以超链接形式标明文章原始出处和作者信息及本版权声明
( http://blog.csdn.net/quqi99 )
我们知道,IBM最近收购了SoftLayer公司,SoftLayer是一个有些年头的数据中心,以前没有云的概念,所以它主要是通过裸机来提供服务,后来有了CloudStack就开始用CloudStack,今后也将支持OpenStack。那么SoftLayer看起来更像一个API网关,在CloudStack和OpenStack两类云中部署虚机。但是今天上午我一直在想一个需求,即使它通过API网关可以在两类云中部署虚机,但两类云中的虚机从网络上不能互通啊。所以我一直在想能不能通过SDN像OpenDaylight之间的技术解决这个问题。
我之前听说过VXLAN这个名词,但仅仅是知道这么个名词而已,它究竟是干什么的我并不清楚。在下午的google search中,居然发现VXLAN就是来解决我这类需求的。原来是有这类技术的,呵呵想法撞车了看来我专利的想法泡汤了。
那么我们来谈谈VXLAN的技术本质是什么呢?
1)首先它和SDN的思想一样通过重新自定义帧格式,采用基于2.5层UDP的socket走3层将这种自定义的2层帧跨数据中心传过去再解析出来。
2)在这种自定义帧中可以加入原有的VLAN和tenant的概念来隔离网络,这个vlan的大小可以轻易突破0-4094的限制。
3)这样的好处是虚机可以跨数据中心迁移。
4) VMware是通过这种软件的VXLAN方式来解决这类问题;Cisco玩硬件的它当然通过硬件的方式来解决,但原理是一样的也是Mac in IP的方式;微软又搞了一个标准NVGRE,一样的故事,但区别在于VXLAN是VMware更私有的封装,NVGRE的封装采用了标准的GRE遂道,但GRE的性能可能是一个问题。
5) IBM也有类似的产品Dove, Dove的遂道协议是私有的,但它使用VXLAN的帧格式进行封装,这意味着它可以支持任何VXLAN的底层网络硬件。Dove的那个虚拟交换机名称叫DVS5000v, 参考http://www.ileader.com.cn/html/2012/11/28/57227.htm

underlay网络,物理底层网络的作用,就是提供一个IP矩阵(类似fan),它的职责是提供所有物理设备之间的单播IP可达性。(服务器,存储设备,路由器或者交换机),一个理想化的底层网络,可以提供网络中任意一点之间的低延迟,无阻塞和高带宽连接。它不需要保存任何租户的信息,只包含物理机的IP前缀或MAC地址。但处于边缘的物理网关路由器或交换机是一个特殊,它需要包含租户的MAC或者IP地址信息。
overlay网络,在underlay网络之上创建具有两层包头的虚拟overlay网络实现NAT与隔离。使用动态的“通道”网,保证虚拟服务器之间的连通性。如vxlan, mpls over gre/udp等。虚拟路由器会包含每一个租户的信息,会针对每一个虚拟网络构建单独的路由转发信息(也叫路由实例),它并不保存所有的IP和MAC,它只保存和这个虚拟网络相关的虚机的IP前缀(在L3 overlay网络)或者MAC地址(在L2 overlay网络).
下面是VXLAN的网络组成:
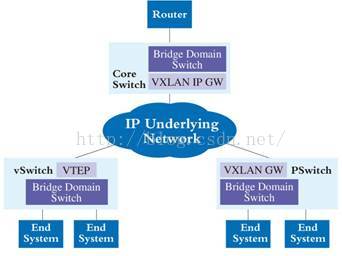
VTEP是直接与EndSystem连接的设备,负责原始以太报文的VXLAN封装和解封装,形态可以是虚拟交换机,也可以是物理交换机。
VXLAN GW(二层)除了具备VTEP的功能外,还负责VLAN报文与VXLAN报文之间的映射和转发,主要以物理交换机为主。
VXLAN IP GW(三层)具有VXLAN GW的所有功能,此外,还负责处理不同VXLAN之间的报文通信,同时也是数据中心内部服务向往发布业务的出口,主要以高性能物理交换机为主。
相同VXLAN VM之间互访流程:
a, 单播报文在VTEP处查找目的MAC地址,确定对应的VTEP主机IP地址。
b, 根据目的和源VTEP主机IP地址封装VXLAN报文头后发送给IP核心网
c, IP核心内部根据路由转发该UDP报文给目的VTEP
d, 目的VTEP解封装VXLAN报文头后按照目的MAC转发报文给目的VM
不同VXLAN VM之间需要互访,必须经过VXLAN IP GW完成,在VXLAN IP GW上配置VXLAN Maping表项进行转发,报文封装模式同同一VXLAN内VM一致;
VXLAN VM与VLAN VM之间互访,通过VXLAN GW来完成,VXLAN报文先通过VXLAN内部转发模式对报文进行封装,目的IP为VXLAN GW,在VXLAN GW把VXLAN报文解封装后,匹配二层转发表项进行转发,VLAN到VXLAN的访问流程正好相反。
关于openflow,它并不是像传统网络那样一层层剥包抽取出MAC在L2层转发,抽取出IP在L3层转发。它是根据:端口号、VLAN、L2/L3/L4信息的10个关键字在控制器层通过字符串匹配进行转发的,所以openflow并不是传统上的L2层设备。特别是,对于L3设备,各类IGP/EGP路由也是运行在OpenFlow Controller之上的。它处理L2层的转发好理解,它怎么和L3层的这些路由设置打交道呢,它怎么与运行VLAN、MPLS,以及BGP、OSPF 和IS-IS等路由协议的传统以太网交换机和谐共存呢?
这里有一篇论文http://cseweb.ucsd.edu/~vahdat/papers/b4-sigcomm13.pdf , 目前的OpenFlow能够实现对L2-L4层字段的转发。由于OpenFlow是通过软件实现对整个网络的控制,因此包括BGP协议这些所谓的“控制”功能,理论上都是能够在控制器上通过软件方式实现的,不过目前尚没有看到这样的软件,因为传统的路由信息表和控制器管理的全局网络信息之间需要如何转换,都是跟特定的控制器相关的,而不同的控制器存储的网络全局信息有可能是不一样的。觉得根源在于目前SDN的北向接口还未标准化,各个控制器的API标准未统一。
谷歌的这篇论文(https://www.opennetworking.org/images/stories/downloads/sdn-resources/customer-case-studies/cs-googlesdn.pdf),其实它里面就实现了BGP协议,不过它不是直接通过控制器软件实现,而是通过Quagga实现对BGP报文的处理从而生成RIB,然后通过控制器Onix上开发的软件RAP实现RIB(路由转发表)前缀到NIB(openflow转发表的名字)的转换。OpenFlow交换机没有任何“控制”功能,所有的控制逻辑都在控制器上实现,明白这一点就很好理解它怎么和L3层交互了。通过OpenFlow实现两个数据中心L2层网络互通,貌似能够通过FlowVisor实现(FlowVisor是用来管理多个openflow控制器的),不过会增加网络部署的复杂度了. 可参考这篇文章《Inside Google's Software-Defined Network,http://www.networkcomputing.com/data-networking-management/inside-googles-software-defined-network/240154879)

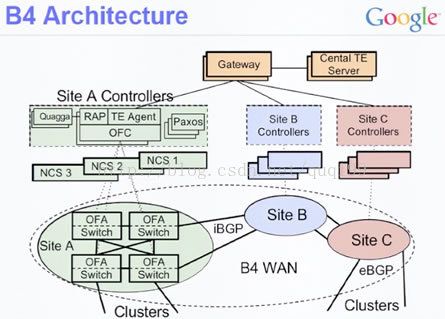
对上图的相关解释如下:
1, Network Controller Servers (NCSs)
2, ISIS是类似于OSPF的一种基于路径状态的内部路由协议
3, Paxos是一个分布式一致性算法的协议
4, Quagga是一个实现了像RIP,OSPF, BGP等动态路由算法的软件,它可以动态地学习BGP报文生成路由规则表RIB
5, RAP是google基于google的openflow controls (Onix,也即上面的NCSs)的一个软件,用于将RIB生成NIB(openflow的转发表),这样openflow switch根据它作转发。
不过上面的路由转发完全不同于传统的包转发,而是基于流转发的,那么具体到openstack中,它怎么和l3-agent协作呢?还是另起灶炉?
再科普一下BGP的两种邻居IBGP和EBGP:
BGP在路由器上运行主要有两种邻居:IBGP(Internal BGP)和EBGP(External BGP)。如果两个交换BGP报文的对等体属于同一个自治系统,那么这两个对等体就是IBGP对等体(Internal BGP),如果两个交换BGP报文的对等体属于不同的自治系统,那么这两个对等体就是EBGP对等体 (External BGP)。

如上图所示,RTB和RTD为IBGP对等体,RTA和RTB是EBGP对等体。
虽然BGP是运行于自治系统之间的路由协议,但是一个AS的不同边界路由器之间也要建立BGP连接,只有这样才能实现路由信息在全网的传递,如RTB和RTD,为了建立AS100和AS300之间的通信,我们要在它们之间建立IBGP连接。
IBGP对等体之间不一定是物理上直连的,但必须保证逻辑上全连接。(TCP连接能够建立即可)。为了IBGP对等体路由通告的可靠性,我们一般都是采用loopback接口建立IBGP邻居关系,同时必须指定路由更新报文的源接口。
peer { group-name | peer-address } connect-interface interface-name
一般的路由器(包括Quidway系列路由器)都默认要求EBGP对等体之间是有物理上的直连链路,同时他们一般也提供改变这个缺省设置的配置命令。允许同非直连相连网络上的邻居建立EBGP连接。
peer { group-name | peer-address } ebgp-max-hop [ ttl ]
EBGP的邻居要求必须是直连的(除非做了特别的配置),
而IBGP不必非要是直连的(因为它使用TCP协议且单播),这样RTB通过EBGP收到RTA的路由信息之后,只会将这些路由信息发往RTD,RTD到发给RTE。
我的一些关于SDN的暂不清晰的不成熟想法:
1)基于sFlow的VXLAN流量分析工具?
2) 基于OpenVswitch中的VXLAN的三层来做WAN的异构云(像openstack和cloudstack)的集成,再上之上整一个TE(Traffic Engine),参见谷歌的论文,
Inter-Datacenter WAN with centralized TE using SDN and OpenFlow,https://www.opennetworking.org/images/stories/downloads/sdn-resources/customer-case-studies/cs-googlesdn.pdf
或者用Dove ?
3)具有网络感知能力的应用能够根据需要对逻辑网络进行动态定义的应用
4)流量工程ECMP, 怎么能实现GRE遂道的多路径传输?
5)VXLAN之类的流量可视化工具?
6) 在openstack neutron中集成VXLAN网关?
7) 基于vxlan的异构云集成?目前openstack有vxlan插件,但云一般有三层网络(虚机用的服务网络,物理机用的管理网络,外网网络),现有的vxlan插件应该是将两端的物理机的管理网络IP作为遂道的端点的,但如果跨数据中心的话,我觉得应该再给物理机分一个浮动IP作为遂道端点, 但是浮动IP是加在网络结节上的,可行吗?想法未验证)
也附一篇文章,有关 OpenFlow/SDN 的小总结 http://richardzhao.me/?p=775
附录,
1)OpenVswitch使用GRE的命令:
ovs-vsctl add-port br0 tep0 -- set interface tep0 type=internal
ifconfig tep0 192.168.1.11 netmask 255.255.255.0
ovs-vsctl add-int br2 gre0 -- set interface gre1 type=gre options:remote_ip=192.168.1.11
ovs-vsctl add-int br2 gre0 -- set interface gre1 type=gre options:remote_ip=192.168.1.10
2) linux bridge中的vxlan
brctl addbr br.4090
ip link add vxlan4090 type vxlan id 4090 group 239.1.1.1 dev eth0
ip link set vxlan4090 up
ip link set br.4090 up
brctl addif br.4090 vxlan4090
然后将虚机的tap设备插入到上述网桥即可.
3) OpenVswitch中使用VXLAN的命令:
ovs-vsctl add-int br2 vx1 -- set interface vx1 type=vxlan options:remote_ip=192.168.1.10
ovs-vsctl add-int br2 vx1 -- set interface vx1 type=vxlan options:remote_ip=192.168.1.11
参见资料:http://blog.scottlowe.org/2013/05/07/using-gre-tunnels-with-open-vswitch/

像GRE,VXLAN这类overlay的遂道都有一个很大的重要,它在虚拟层面将L2层打通了,如果再采用广播来做ARP的话可能会造成广播风暴,所以可以采用ARP Proxy的方式自己用程序实现cache来给虚机提供ip到mac的映射。另一方面也可以使用其他overlay的技术,如STT,它不使用广播,它也是一种mac over ip的协议,和vxlan, nvgre类似,都是把二层的帧封装在一个ip报文的payload中,在ip报文的payload中,除了虚拟网络的二层包以外,还要把构造的一个tcp头(这样硬件网卡误以为它是一个TCP包,这样就会用硬件来分片了,这是STT的最大优点),和一个stt头加在最前面。见:http://tools.ietf.org/html/draft-davie-stt-01, NTT与VXLAN的区别见:http://blog.ipspace.net/2012/03/do-we-really-need-stateless-transport.html