(终于找到了获取有效_signature的方法)博客搬家系列(六)-爬取今日头条文章(二)
(终于找到了获取有效_signature的方法)博客搬家系列(六)-爬取今日头条文章(二)
一.前情回顾
博客搬家系列(六)-爬取今日头条文章:https://blog.csdn.net/rico_zhou/article/details/83619564
上回我们说到了使用java htmlunit爬取今日头条的文章列表难度很大,关键在于_signature这个参数的加密算法,经过百度查询也发现了大家大多数都是使用Python selenium来获取,但是需要安装浏览器和浏览器驱动,这不是我们想要的,并且我们也测试出了以下几点,
1.使用网上找到的转化版js是可以获取到_signature的,但是只能在浏览器中打开此html获取的才能用,而使用htmlunit爬取本地html文件得到的却不能使用。
2.直接执行今日头条的TAC.sign()方法获取到的参数依然无法使用,由于每次获取的参数都是不一样的,也无法判断到底是缺少什么东西。
基于以上两点我们开始今天的尝试(其实就是昨天的事儿,不甘心那!)
二.整体分析
首先上一下此html:
基于上面分析的第二点,我们暂时是可以看看这个算法到底是怎样(核心代码来源于网上,暂时忘了url找到后后补上),本人js水,大概也就注意到了以下几点:
1.直接将js部分用nodejs执行肯定是不行的,因为代码中出现了window对象,且使用了window.Function构建动态函数,没办法,不会将其构造成纯js运行,那么我们的目标就是将直接打开html获取的参数param1,和使用htmlunit读取本地html文件获取的参数param2比对,找出其中的规律,让其一样或者都生效(param1是生效的)。
2.根据代码中构建函数t=window.Function,我们找到了两个相关的使用地方:
function e(e, a, r) {
return ((b[e] = t("x,y", "return x " + e + " y")))(r, a);
}
function a(e, a, r) {
return (k[r] || (k[r] = t("x,y", "return new x[y](" + Array(r + 1).join(",x[++y]").substr(1) + ")")))(e, a);
}说实话,只知道是构建函数但是具体干嘛的还是不知道,咋办呢?那就console.log()输出一下呗,改一下:
function e(e, a, r) {
console.log(2222222+" "+e)
console.log(3333333+" "+a)
console.log(4444444+" "+r)
var aa=((b[e] = t("x,y", "return x " + e + " y")))(r, a);
return aa
//return (b[e] || (b[e] = t1))(r, a)
}
function a(e, a, r) {
console.log(2222222+" "+e)
console.log(3333333+" "+a)
console.log(4444444+" "+r)
var kk=(k[r] || (k[r] = t("x,y", "return new x[y](" + Array(r + 1).join(",x[++y]").substr(1) + ")")))(e, a);
console.log(5555555+" "+kk)
return kk;
}经过多次打开运行验证,发现函数e运行了很多次,而且也看不出啥规律,但是函数a却只运行了一次
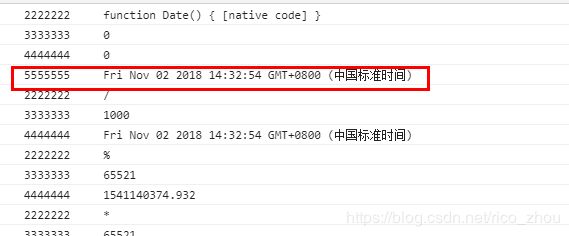
注意是55555开头的,显然这是时间戳,而且只出现一次,那么我就先将其写死,毕竟这个是可以自行获取不再需要加密了,
function a(e, a, r) {
console.log(2222222+" "+e)
console.log(3333333+" "+a)
console.log(4444444+" "+r)
var kk=(k[r] || (k[r] = t("x,y", "return new x[y](" + Array(r + 1).join(",x[++y]").substr(1) + ")")))(e, a);
console.log(5555555+" "+kk)
//先将其写死
kk='Fri Nov 02 2017 10:41:59 GMT+0800 (中国标准时间)'
return kk;
}再次运行
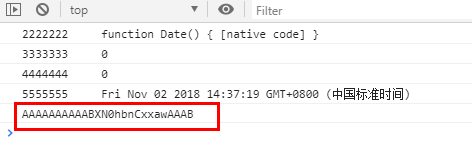
结果:AAAAAAAAAABXN0hbnCxxawAAAB
多次运行,发现参数没有变化,而且参数变得简洁了,改变一下时间值发现还是没有变化,说明此参数的变化是只跟user_id,max_behot_time有关系,若固定则参数值固定,至于为什么没改之前却一直变化,大概是k这个函数变化吧,不管了,那么先看看能不能用,将对应的user_id和max_behot_time带入,发现确实可以使用,此时欣喜若狂,既然页面的参数param1固定了而且也可以使用了,那就和使用htmlunit获取的参数param2好比对了,
赶紧使用htmlunit读取一下本地刚刚的html
public static void test3() throws Exception {
String urlOne = "file:///C:/Users/rzhou6/Desktop/toutiao/newd.html";
// 模拟浏览器操作
// 创建WebClient
WebClient webClient = new WebClient(BrowserVersion.CHROME);
// 关闭css代码功能
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setCssEnabled(false);
// 如若有可能找不到文件js则加上这句代码
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
HtmlPage page2 = webClient.getPage(urlOne);
System.out.println(page2.asText());
}
结果:AAAAAAAAAAAYyN2oFg9xawAAAB
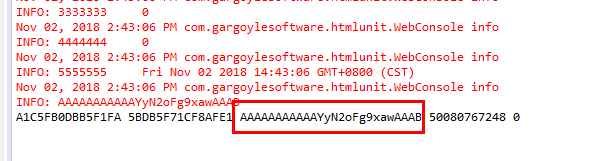
简单比对一下
param1:AAAAAAAAAABXN0hbnCxxawAAAB(有效)
param2:AAAAAAAAAAAYyN2oFg9xawAAAB(无效)
中间的几位不同,为了能找到规律,那就得多测试,选择不同的user_id,每个id不同的页面请求,并将其参数分割,数据如下:
//同一id 101528687217 2,3,4页,网页可行,htmlunit本地文件不可行
1539419885
>AAAAAAAAAA BXN0hbnC x FHA AAAB
>AAAAAAAAAA AYyN2oFg 9 FHA AAAB
1537250643
>AAAAAAAAAA BXN0hbnC x Mew AAAB
>AAAAAAAAAA AYyN2oFg 9 Mew AAAB
1536065316
>AAAAAAAAAA BXN0hbnC w -ig AAAB
>AAAAAAAAAA AYyN2oFg 8 -ig AAAB
usrid 50080767248
1540553612
>AAAAAAAAAA BXN0hbnC x 2Gg AAAB
>AAAAAAAAAA AYyN2oFg 9 2Gg AAAB
1540133733
>AAAAAAAAAA BXN0hbnC w ipA AAAB
>AAAAAAAAAA AYyN2oFg 8 ipA AAAB
1539776774
>AAAAAAAAAA BXN0hbnC x RsQ AAAB
>AAAAAAAAAA AYyN2oFg 9 RsQ AAAB
1539406769
>AAAAAAAAAA BXN0hbnC z Swg AAAB
>AAAAAAAAAA AYyN2oFg . Swg AAAB
1538986022
>AAAAAAAAAA BXN0hbnC z qDw AAAB
>AAAAAAAAAA AYyN2oFg . qDw AAAB
1538388819
>AAAAAAAAAA BXN0hbnC y jAg AAAB
>AAAAAAAAAA AYyN2oFg - jAg AAAB
上一行为页面浏览器获取的参数param1,下面的是使用htmlunit读取html获取的参数param2,多方比对发现,不管是不是同id或者第几页,所有有效的param1中间部分BXN0hbnC,在参数param2中都变成了AYyN2oFg,好办,那我们只要反向替换一下即可,接下来就只有第19位字符不一样,接下来的都是一样的,猜测加密算法中对max_behot_time的值进行加密然后获取新值,暂时我们是可以发现x对应9,w对应8,z对应.,y对应-,其他的暂时未知,只要我们知道了第19位字符的对应规律就能反向替换,最终通过htmlunit读取本地html就能获取到有效的参数_signature,现在更改一下html文件,我们循环一下max_behot_time看看参数第19位都有哪些值出现

for(var i=1000000000;i<1000001000;i++){
getHoney(user_id,i);
}注意i值不要过大,循环次数不要过多,不然容易卡死,
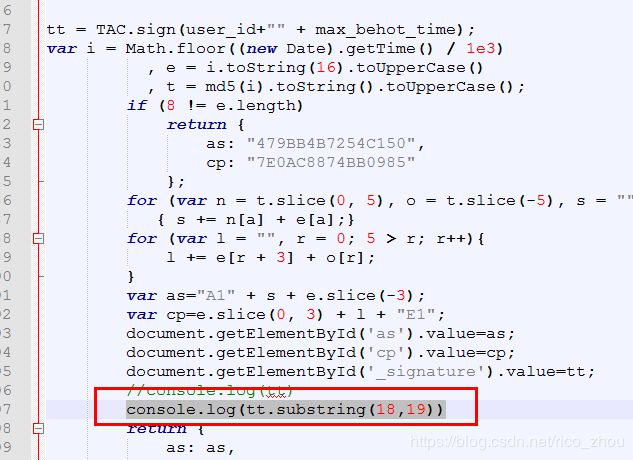
运行
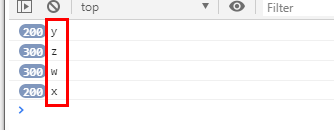
多次改变i初始值发现,只有y,z,w,x这四个值出现那么我们只需要替换他即可
接下来写代码
/**
* @date Oct 31, 2018 3:59:49 PM
* @Desc 获取文章list请求url
* @param blogMove
* @param num
* @param max_behot_time
* @return
* @throws IOException
* @throws MalformedURLException
* @throws FailingHttpStatusCodeException
*/
public static String getTouTiaoListUrl(Blogmove blogMove, int num, String max_behot_time)
throws Exception {
String oneUrl = "https://www.toutiao.com/c/user/article/?page_type=1&user_id=%s&max_behot_time=%s&count=20&as=%s&cp=%s&_signature=%s";
String user_id = blogMove.getMoveUserId();
// System.out.println(user_id);
String as = "";
String cp = "";
String _signature = "";
//更改文件
updateHtmlFile("C:/Users/rzhou6/Desktop/toutiao/newd.html",user_id,max_behot_time);
String urlOne = "file:///C:/Users/rzhou6/Desktop/toutiao/newd.html";
// 模拟浏览器操作
// 创建WebClient
WebClient webClient = new WebClient(BrowserVersion.CHROME);
// 关闭css代码功能
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setCssEnabled(false);
// 如若有可能找不到文件js则加上这句代码
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
HtmlPage page2 = webClient.getPage(urlOne);
System.out.println(page2.asText());
// 执行js
as = page2.getElementById("as").asText();
cp = page2.getElementById("cp").asText();
_signature = page2.getElementById("_signature").asText();
System.out.println(_signature);
_signature = getRightSign(_signature);
System.out.println(as);
System.out.println(cp);
System.out.println(_signature);
oneUrl = String.format(oneUrl, user_id, max_behot_time, as, cp, _signature);
System.out.println(oneUrl);
return oneUrl;
}
/**
* @date Nov 2, 2018 12:36:27 PM
* @Desc
* @param string
* @param max_behot_time
* @param user_id
*/
private static void updateHtmlFile(String string, String user_id, String max_behot_time) {
String html=FileUtils.getFileToString(string);
Document doc = Jsoup.parse(html);
Element imgTags = doc.getElementById("user_id");
imgTags.attr("value",user_id);
Element imgTags2 = doc.getElementById("max_behot_time");
imgTags2.attr("value",max_behot_time);
//写入文件
new File(string).delete();
FileUtils.appendFile(string, doc.html());
}
/**
* @date Nov 2, 2018 12:24:42 PM
* @Desc
* @param _signature
* @return
*/
private static String getRightSign(String _signature) {
// w:8,x:9,y:-,z:.
// >AAAAAAAAAA BXN0hbnC y jAQ AAAB
// >AAAAAAAAAA AYyN2oFg - jAQ AAAB
String s = _signature.substring(18, 19);
String ss = _signature.substring(19, 22);
if ("8".equals(s)) {
s = "w";
} else if ("9".equals(s)) {
s = "x";
} else if ("-".equals(s)) {
s = "y";
} else if (".".equals(s)) {
s = "z";
}
return "AAAAAAAAAABXN0hbnC" + s + ss + "AAAB";
}
经验证发现,所得的url均可用
PS:其中最后一步出现了不小的波折,在使用htmlunit时突然获取的参数跟测试时不一样了,规律也不一样,但是代码是完全一样的啊,经过对比,发现了是jar包版本的问题,真是奇怪,也没有任何冲突,总之获取的就是不一样,大概这也是期初两个参数获取不一样的原因吧,毕竟htmlunit是模拟而不是实实在在浏览器,htmlunit使用2.27版本即可,使用2.32版本获取的参数规律不再是上文所说了。
PPS:最后又发现了问题,虽然获取的url浏览器是完全可以获取到json数据的,但是htmlunit发送此get请求时,居然偶尔可行,偶尔不行,估计是今日头条的反爬又有限制了,不过没关系,获取了正确的url害怕取不到数据?
欢迎交流学习!
完整源码请见github:https://github.com/ricozhou/blogmove