数据收集-scrapy爬虫框架(二)
scrapy爬虫框架
- 模拟登陆
- 模拟登陆的方法
- scrapy携带cookies直接获取需要登陆后的页面
- 重写start_rquests方法
- 发送post请求
- 管道使用
- 方法
- 文件修改
- 在settings中能够开启多个管道
- 注意点
- 中间件使用
- 使用方法
- 随机User-Agent的下载中间件
- 代理ip使用
- 中间件中selenium使用
- scrapy_redis
- 分布式爬取
- 运行dmoz爬虫,观察现象
- scrapy_redis的原理分析
- 分布式步骤
- 补充总结
- 分布式代码案例补充
模拟登陆
模拟登陆的方法
- requests模块实现模拟登陆
- 直接携带cookies请求页面
- 找url地址,发送post请求存储cookie
- selenium模拟登陆
- 找到对应的input标签,输入文本点击登陆
- scrapy的模拟登陆
- 直接携带cookies
- 找url地址,发送post请求存储cookie
scrapy携带cookies直接获取需要登陆后的页面
- cookie过期时间很长,常见于一些不规范的网站
- 能在cookie过期之前把所有的数据拿到
- 配合其他程序使用,比如其使用selenium把登陆之后的cookie获取到保存到本地,scrapy发送请求之前先读取本地cookie
重写start_rquests方法
携带cookies登陆github
# -*- coding: utf-8 -*-
import scrapy
class Git1Spider(scrapy.Spider):
name = 'git1'
allowed_domains = ['github.com']
start_urls = ['https://github.com/QIKAIDESHENG/']
#重写start_re
def start_requests(self):
url=self.start_urls[0]
temp='_octo=GH1.1.343375846.1592104544; _ga=GA1.2.492559135.1592104764; _gat=1; tz=Asia%2FShanghai; _device_id=201c322d3b8b89b42c2e458c9890507a; has_recent_activity=1; user_session=EYDxg3kELetjNE-FnJybkEI1d53BhtyqyXuWF363HscapAYA; __Host-user_session_same_site=EYDxg3kELetjNE-FnJybkEI1d53BhtyqyXuWF363HscapAYA; logged_in=yes; dotcom_user=QIKAIDESHENG; _gh_sess=ArwonYQL%2FsGIXzmbFwJWBzyVZ3fE8USozF3N08YwZIawA6lbBy1yJ9Lt%2BwNPMZOjM5RCkGgypZJmAoIL3LdjsssNGH0d2SgtF1lBW6HLh5NZoCkX'
cookies={data.split('=')[0]: data.split('=')[-1] for data in temp.split(';')}
yield scrapy.Request(
url=url,
callback=self.parse,
cookies=cookies
)
def parse(self, response):
print(response.xpath('/html/head/title'))
- scrapy中cookie不能够放在headers中,在构造请求的时候有专门的cookies参数,能够接受字典形式的coookie
- 在setting中设置ROBOTS协议、USER_AGENT
发送post请求
可以通过scrapy.Request()指定method、body参数来发送post请求;通常使用scrapy.FormRequest()来发送post请求
import scrapy
class Git2Spider(scrapy.Spider):
name = 'git2'
allowed_domains = ['github.com']
start_urls = ['https://github.com/login']
def parse(self, response):
#从登陆页面响应中解析出post数据
token = response.xpath("//input[@name='authenticity_token']/@value").extract_first()
utf8 = response.xpath("//input[@name='utf8']/@value").extract_first()
commit = response.xpath("//input[@name='commit']/@value").extract_first()
post_data={
"authenticity_token": token,
"utf8": utf8,
"commit": commit,
"login": "QIKAIDESHENG",
"password": "***"
}
print(post_data)
#针对登陆url发送post请求
yield scrapy.FormRequest(
url='http://github.com/session',
callback=self.after_login,
formdata=post_data
)
def after_login(self,response):
yield scrapy.Request('https://github.com/QIKAIDESHENG/',callback=self.check_login)
def check_login(self,response):
print(response.xpath('/html/head/title').extract_first())
在settings.py中通过设置COOKIES_DEBUG=TRUE 能够在终端看到cookie的传递传递过程
管道使用
方法
- pipeline中常用的方法:
- process_item(self,item,spider):
- 管道类中必须有的函数
- 实现对item数据的处理
- 必须return item
- open_spider(self, spider): 在爬虫开启的时候仅执行一次
- close_spider(self, spider): 在爬虫关闭的时候仅执行一次
文件修改
import json
from pymongo import MongoClient
class WangyiPipeline:
def open_spider(self,spider):
if spider.name=='job':
self.file=open('wangyi.json','w')
def process_item(self, item, spider):
if spider.name == 'job':
item=dict(item)
str_data=json.dumps(item,ensure_ascii=False)+',\n'
self.file.write(str_data)
return item
def close_spider(self,spider):
if spider.name == 'job':
self.file.close()
class Wangyi2Pipeline:
def open_spider(self,spider):
if spider.name == 'job2':
self.file=open('wangyi2.json','w')
def process_item(self, item, spider):
if spider.name == 'job2':
item=dict(item)
str_data=json.dumps(item,ensure_ascii=False)+',\n'
self.file.write(str_data)
return item
def close_spider(self,spider):
if spider.name == 'job2':
self.file.close()
class MongoPipeline:
def open_spider(self,spider):
self.client=MongoClient('127.0.0.1',27017) #实例化mongoclient
self.db=self.client['wahhh']
self.col=self.db['wangyi']
def process_item(self,item,spider):
data=dict(item)
self.col.insert(data)
return item
def close_spider(self,spider):
self.file.close()
开启管道
ITEM_PIPELINES = {
'wangyi.pipelines.WangyiPipeline': 300,
'wangyi.pipelines.Wangyi2Pipeline': 301,
'wangyi.pipelines.MongoPipeline': 301,
}
在settings中能够开启多个管道
- 不同的pipeline可以处理不同爬虫的数据,通过spider.name属性来区分
- 不同的pipeline能够对一个或多个爬虫进行不同的数据处理的操作,比如一个进行数据清洗,一个进行数据的保存
- 同一个管道类也可以处理不同爬虫的数据,通过spider.name属性来区分
注意点
- pipeline在setting中键表示位置(即pipeline在项目中的位置可以自定义),值表示距离引擎的远近,越近数据会越先经过:权重值小的优先执行
- 有多个pipeline的时候,process_item的方法必须return item,否则后一个pipeline取到的数据为None值
- pipeline中process_item的方法必须有,否则item没有办法接受和处理
- process_item方法接受item和spider,其中spider表示当前传递item过来的spider
中间件使用
- scrapy运行流程中所在位置不同分为:
- 下载中间件
- 爬虫中间件
- 中间的作用:预处理request和response对象
- 对header以及cookie进行更换和处理
- 使用代理ip等
- 对请求进行定制化操作
- 通常使用下载中间件
使用方法
- process_request(self, request, spider):
- 当每个request通过下载中间件时,该方法被调用。
- 返回None值:没有return也是返回None,该request对象传递给下载器,或通过引擎传递给其他权重低的process_request方法
- 返回Response对象:不再请求,把response返回给引擎
- 返回Request对象:把request对象通过引擎交给调度器,此时将不通过其他权重低的process_request方法
- process_response(self, request, response, spider):
- 当下载器完成http请求,传递响应给引擎的时候调用
- 返回Resposne:通过引擎交给爬虫处理或交给权重更低的其他下载中间件的process_response方法
- 返回Request对象:通过引擎交给调取器继续请求,此时将不通过其他权重低的process_request方法
- 在settings.py中配置开启中间件,权重值越小越优先执行
随机User-Agent的下载中间件
1.在middleware.py 中定义中间件类
2. 在中间件类中重写处理请求或者响应方法
3. 在setting文件中开启中间件使用
middleware.py
from Douban.settings import USER_AGENT_LIST
class RandomUserAgent:
def process_request(self,request,spider):
# print(request.headers)
ua=random.choice(USER_AGENT_LIST)
request.headers['User-Agent']=ua
setting.py
USER_AGENT_LIST=[
"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0",
]
DOWNLOADER_MIDDLEWARES = {
'Douban.middlewares.RandomUserAgent': 543,
}
代理ip使用
- 代理添加的位置:request.meta中增加proxy字段
- 获取一个代理ip,赋值给request.meta[‘proxy’]
- 代理池中随机选择代理ip
- 代理ip的webapi发送请求获取一个代理ip
middlewares.py
from Douban.settings import PROXY_LIST
class RandomProxy(object):
def process_request(self,request,spider):
proxy=random.choice(PROXY_LIST)
print(proxy)
#收费ip认证
if 'user_passwd' in proxy:
#对账号密码进行加密
b64_up=base64.b64encode(proxy['user_passwd'])
# 设置认证
request.header['Proxy-Authorization']='Basic ' +b64_up.decode()
# 设置代理
request.meta['proxy']=proxy['ip_port']
else:
request.meta['proxy'] = proxy['ip_port']
settings
PROXY_LIST=[
{"ip_port":"110.243.10.133:9999"},
{"ip_port":"58.253.155.194:9999"},
{"ip_port":"122.5.177.122:9999"},
{"ip_port":"118.25.35.202:9999"}
]
# Obey robots.txt rules
# ROBOTSTXT_OBEY = True #见到尽量关闭
DOWNLOADER_MIDDLEWARES = {
'Douban.middlewares.RandomProxy': 543,
}
中间件中selenium使用

第三个url需要渲染等待页面加载,再爬取数据。
middleware.py #需要渲染等待的页面设置
class SeleniumMiddleware(object):
def process_request(self, request, spider):
url = request.url
if 'daydata' in url:
driver = webdriver.Chrome()
driver.get(url)
time.sleep(3)
data = driver.page_source #渲染之后的源码
driver.close() #关闭
# 创建响应对象
res = HtmlResponse(url=url, body=data, encoding='utf-8', request=request)
return res
ssettings.py
DOWNLOADER_MIDDLEWARES = {
# 'AQI.middlewares.MyCustomDownloaderMiddleware': 543,
'AQI.middlewares.SeleniumMiddleware': 543,
}
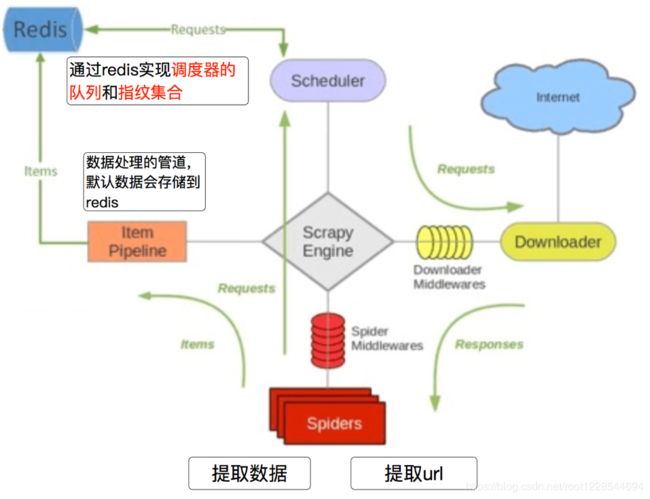
scrapy_redis
分布式爬取
- 分布式就是不同的节点(服务器,ip不同)共同完成一个任务
- scrapy_redis是scrapy框架的基于redis的分布式组件
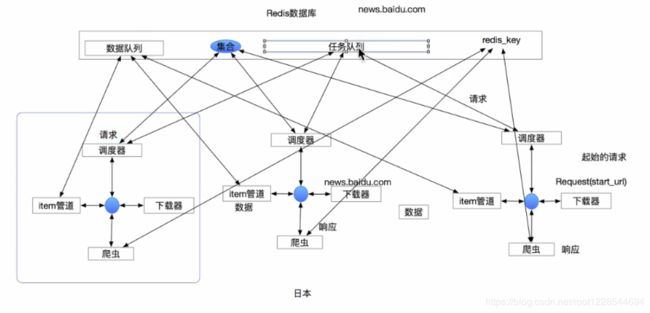
- scrapy_redis的作用:通过持久化请求队列和请求的指纹集合来实现:
- 断点续爬
- 分布式快速抓取
- scrapy_redis的流程
- 在scrapy_redis中,所有的待抓取的request对象和去重的request对象指纹都存在所有的服务器公用的redis中
- 所有的服务器中的scrapy进程公用同一个redis中的request对象的队列
- 所有的request对象存入redis前,都会通过该redis中的request指纹集合进行判断,之前是否已经存入过
- 在默认情况下所有的数据会保存在redis中
-下载github的demo代码
clone github scrapy-redis源码文件
git clone https://github.com/rolando/scrapy-redis.git
运行dmoz爬虫,观察现象
1.settings添加redis的地址,程序才能够使用redis
REDIS_URL = "redis://127.0.0.1:6379"
#或者使用下面的方式
# REDIS_HOST = "127.0.0.1"
# REDIS_PORT = 6379
2.redis中多了三个键:

3. 中止进程后再次运行dmoz爬虫
继续执行程序,会发现程序在前一次的基础之上继续往后执行,domz爬虫是一个基于url地址的增量式的爬虫
scrapy_redis的原理分析
- RedisPipeline # 管道类
- RFPDupeFilter # 指纹去重类
- Scheduler # 调度器类
- SCHEDULER_PERSIST # 是否持久化请求队列和指纹集合
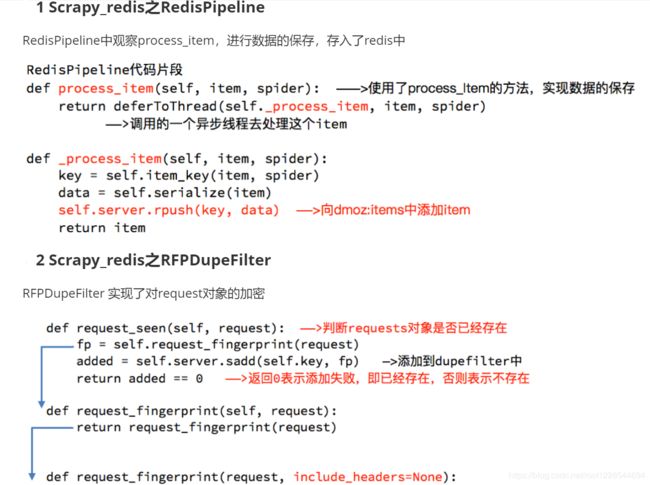


request对象入队的条件:
- request的指纹不在集合中
- request的dont_filter为True,即不过滤
- start_urls中的url地址会入队,因为他们默认是不过滤
分布式步骤
1.编写普通爬虫
创建项目-明确目标-创建爬虫-保存内容
2.改造成分布式爬虫
2.1 改造爬虫
2.1.1导入scrapy_redis中分布式爬虫
2.1.2继承类
2.1.3注释start_urls和allowed_domains
2.1.4设置redis_key获取start_urls
2.1.5设置init获取允许的域
2.2 改造配置文件
copy scrapy_redis配置参数
补充总结
- scrapy_redis流程和实现原理
- 在scrapy框架流程的基础上,把存储request对象放到了redis的有序集合中,利用该有序集合实现了请求队列
- 并对request对象生成指纹对象,也存储到同一redis的集合中,利用request指纹避免发送重复的请求
- request对象进入队列的条件
- request的指纹不在集合中
- request的dont_filter为True,即不过滤
- request指纹的实现
- 请求方法
- 排序后的请求地址
- 排序并处理过的请求体或空字符串
- 用hashlib.sha1()对以上内容进行加密
- scarpy_redis实现增量式爬虫、布式爬虫
- 对setting进行如下设置
- DUPEFILTER_CLASS = “scrapy_redis.dupefilter.RFPDupeFilter”
- SCHEDULER = “scrapy_redis.scheduler.Scheduler”
- SCHEDULER_PERSIST = True
- ITEM_PIPELINES = {‘scrapy_redis.pipelines.RedisPipeline’: 400,}
- REDIS_URL = “redis://127.0.0.1:6379” # 请正确配置REDIS_URL
- 爬虫文件中的爬虫类继承RedisSpider类
- 爬虫类中redis_key替代了start_urls
- 启动方式不同
- 通过scrapy crawl spider启动爬虫后,向redis_key放入一个或多个起始url(lpush或rpush都可以),才能够让scrapy_redis爬虫运行
- 对setting进行如下设置
分布式代码案例补充
京东图书爬取并改写分布式案例,注意:提取价格价格在另一网页,提取商品,商品有单品和套装都需要提取。此案例是19年四月。20年网站已简化,在一个页面就能提取出来。19年案例仅提供爬虫分析思路
book.py
import scrapy
from JD.items import JdItem
import json
# ----1 导入分布式爬虫类
from scrapy_redis.spiders import RedisSpider
# ----2 继承分布式爬虫类
class BookSpider(RedisSpider):
name = 'book'
# ----3 注销start_urls&allowed_domains
# # 修改允许的域
# allowed_domains = ['jd.com', 'p.3.cn']
# # 修改起始的url
# start_urls = ['https://book.jd.com/booksort.html']
# ----4 设置redis-key
redis_key = 'py21'
# ----5 设置__init__
def __init__(self, *args, **kwargs):
domain = kwargs.pop('domain', '')
self.allowed_domains = list(filter(None, domain.split(',')))
super(BookSpider, self).__init__(*args, **kwargs)
def parse(self, response):
# 获取所有图书大分类节点列表
big_node_list = response.xpath('//*[@id="booksort"]/div[2]/dl/dt/a')
for big_node in big_node_list[:1]:
big_category = big_node.xpath('./text()').extract_first()
big_category_link = response.urljoin(big_node.xpath('./@href').extract_first())
# 获取所有图书小分类节点列表
small_node_list = big_node.xpath('../following-sibling::dd[1]/em/a')
for small_node in small_node_list[:1]:
temp = {}
temp['big_category'] = big_category
temp['big_category_link'] = big_category_link
temp['small_category'] = small_node.xpath('./text()').extract_first()
temp['small_category_link'] = response.urljoin(small_node.xpath('./@href').extract_first())
# 模拟点击小分类链接
yield scrapy.Request(
url=temp['small_category_link'],
callback=self.parse_book_list,
meta={"py21": temp}
)
def parse_book_list(self, response):
temp = response.meta['py21']
book_list = response.xpath('//*[@id="plist"]/ul/li/div')
# print(len(book_list))
for book in book_list:
item = JdItem()
item['big_category'] = temp['big_category']
item['big_category_link'] = temp['big_category_link']
item['small_category'] = temp['small_category']
item['small_category_link'] = temp['small_category_link']
#书的分类有单品和套装,都需要提取出来
item['bookname'] = book.xpath('./div[3]/a/em/text()|./div/div[2]/div[2]/div[3]/a/em/text()').extract_first().strip()
item['author'] = book.xpath('./div[4]/span[1]/span/a/text()|./div/div[2]/div[2]/div[4]/span[1]/span[1]/a/text()').extract_first().strip()
item['link'] = book.xpath('./div[1]/a/@href|./div/div[2]/div[2]/div[1]/a/@href').extract_first()
#价格在另一个页面,需要特殊处理,提取价格 。
# 获取图书编号
skuid = book.xpath('.//@data-sku').extract_first()
# skuid = book.xpath('./@data-sku').extract_first()
# print("skuid:",skuid)
# 拼接图书价格低至
pri_url = 'https://p.3.cn/prices/mgets?skuIds=J_' + skuid
yield scrapy.Request(url=pri_url,callback=self.parse_price,meta={'meta_1':item})
def parse_price(self, response):
item = response.meta['meta_1']
dict_data = json.loads(response.body)
item['price'] = dict_data[0]['p']
yield item
scrapy-redis中的settings中复制,修改example
SPIDER_MODULES = ['JD.spiders']
NEWSPIDER_MODULE = 'JD.spiders'
USER_AGENT = 'scrapy-redis (+https://github.com/rolando/scrapy-redis)'
# 设置重复过滤器的模块
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 设置调取器,scrap_redis中的调度器具备与数据库交互的功能
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 设置当爬虫结束的时候是否保持redis数据库中的去重集合与任务队列
SCHEDULER_PERSIST = True
#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderPriorityQueue"
#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderQueue"
#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderStack"
ITEM_PIPELINES = {
# 'JD.pipelines.ExamplePipeline': 300,
# 当开启该管道,该管道将会把数据存到Redis数据库中
'scrapy_redis.pipelines.RedisPipeline': 400,
}
# 设置redis数据库
REDIS_URL = "redis://172.16.123.223:6379"
# LOG_LEVEL = 'DEBUG'
# Introduce an artifical delay to make use of parallelism. to speed up the
# crawl.
DOWNLOAD_DELAY = 1
20年
import scrapy
from JD.items import JdItem
class BookSpider(scrapy.Spider):
name = 'book'
allowed_domains = ['jd.com']
start_urls = ['https://book.jd.com/booksort.html']
def parse(self, response):
# 获取所有图书大分类列表结点
big_node_list=response.xpath('//*[@id="booksort"]/div[2]/dl/dt/a')
for big_node in big_node_list[:1]:
big_category=big_node.xpath('./text()').extract_first()
big_category_link=response.urljoin(big_node.xpath('./@href').extract_first())
# 获取所有图书小分类-----取兄弟结点
small_node_list=big_node.xpath('../following-sibling::dd[1]/em/a')
for small_node in small_node_list[:1]:
temp={}
temp['big_category']=big_category
temp['big_category_link']=big_category_link
temp['small_category']=small_node.xpath('./text()').extract_first()
temp['small_category_link']=response.urljoin(small_node.xpath('./@href').extract_first())
# print(temp)
# 模拟点击小分类连接
yield scrapy.Request(
url=temp['small_category_link'],
callback=self.parse_book_list,
meta={"temp":temp}
)
def parse_book_list(self,response):
temp=response.meta['temp']
book_list=response.xpath('//*[@id="J_goodsList"]/ul/li/div')
print(len(book_list))
for book in book_list:
item=JdItem()
item['big_category']=temp['big_category']
item['big_category_link']=temp['big_category_link']
item['small_category']=temp['small_category']
item['small_category_link']=temp['small_category_link']
item['bookname']=book.xpath('./div[3]/a/em/text()').extract_first()
item['price']=book.xpath('./div[2]/strong/i/text()').extract_first()
item['link']=book.xpath('./div[3]/a/@href').extract_first()
yield item