数据收集-scrapy爬虫框架(三)
scrapy爬虫框架
- scrapy_splash组件
- 环境安装
- scarpy中使用splash
- 结论
- 日志信息
- 日志信息
- scrapy的常用配置
- scrapyd部署
- 安装
- 启动
- 项目部署
- 管理scrapy项目
- 其他webapi
- Gerapy
- Install
- Setting and Start
- Manage scrapy project by the settings of Gerapy
- Relationship between Gerapy and Scrapyd
- Crawlspider
- new project
- key points
- other things
- summary
- Coding
- scrapy_redis和scrapy_splash配合使用
- Summary
scrapy_splash组件
- 使用scrapy-splash最终拿到的response相当于是在浏览器全部渲染完成以后的网页源代码。
- scrapy-splash能够模拟浏览器加载js,并返回js运行后的数据
splash官方文档
环境安装
- splash的dockerfile
可以直接使用splash的docker镜像
安装并启动docker服务 - 获取splash的镜像
安装docker的基础上pull取splash的镜像
sudo docker pull scrapinghub/splash
- 验证是否安装成功
运行splash的docker服务,并通过浏览器访问8050端口验证安装是否成功
-
前台运行 sudo docker run -p 8050:8050 scrapinghub/splash
-
后台运行 sudo docker run -d -p 8050:8050 scrapinghub/splash
-
注意: 解决获取镜像超时:修改docker的镜像源
以ubuntu18.04为例
- 创建并编辑docker的配置文件
sudo vi /etc/docker/daemon.json
- 写入国内docker-cn.com的镜像地址配置后保存退出
{
"registry-mirrors": ["https://registry.docker-cn.com"]
}
- 重启电脑或docker服务后重新获取splash镜像
- 关闭splash服务
需要先关闭容器后,再删除容器
sudo docker ps -a
sudo docker stop CONTAINER_ID
sudo docker rm CONTAINER_ID
- python中安装
pip install scrapy-splash
scarpy中使用splash
1 创建项目创建爬虫
scrapy startproject test_splash
cd test_splash
scrapy genspider no_splash baidu.com
scrapy genspider with_splash baidu.com
2 完善settings.py配置文件
在settings.py文件中添加splash的配置以及修改robots协议
# 渲染服务的url
SPLASH_URL = 'http://127.0.0.1:8050'
# 下载器中间件
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
# 去重过滤器
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
# 使用Splash的Http缓存
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
3 不使用splash
在spiders/no_splash.py中完善
import scrapy
class NoSplashSpider(scrapy.Spider):
name = 'no_splash'
allowed_domains = ['baidu.com']
start_urls = ['https://www.baidu.com/s?wd=一人之下']
def parse(self, response):
with open('no_splash.html', 'w') as f:
f.write(response.body.decode())
4 使用splash
import scrapy
from scrapy_splash import SplashRequest # 使用scrapy_splash包提供的request对象
class WithSplashSpider(scrapy.Spider):
name = 'with_splash'
allowed_domains = ['baidu.com']
start_urls = ['https://www.baidu.com/s?wd=一人之下']
def start_requests(self):
yield SplashRequest(self.start_urls[0],
callback=self.parse_splash,
args={'wait': 10}, # 最大超时时间,单位:秒
endpoint='render.html') # 使用splash服务的固定参数
def parse_splash(self, response):
with open('with_splash.html', 'w') as f:
f.write(response.body.decode())
5 分别运行两个爬虫
scrapy crawl no_splash
scrapy crawl with_splash
结论
- splash类似selenium,能够像浏览器一样访问请求对象中的url地址
- 能够按照该url对应的响应内容依次发送请求
- 并将多次请求对应的多次响应内容进行渲染
- 最终返回渲染后的response响应对象
日志信息
日志信息

scrapy的常用配置

scrapy_redis配置

scrapy_splash配置
SPLASH_URL = 'http://127.0.0.1:8050'
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'

scrapyd部署
scrapyd是一个用于部署和运行scrapy爬虫的程序,它允许你通过JSON API来部署爬虫项目和控制爬虫运行,scrapyd是一个守护进程,监听爬虫的运行和请求,然后启动进程来执行它们
json api本质就是post请求的webapi
安装
scrapyd服务:
pip install scrapyd
scrapyd客户端:
pip install scrapyd-client
启动
- 在scrapy项目路径下 启动scrapyd的命令:sudo scrapyd 或 scrapyd
- 启动之后就可以打开本地运行的scrapyd,浏览器中访问本地6800端口可以查看scrapyd的监控界面
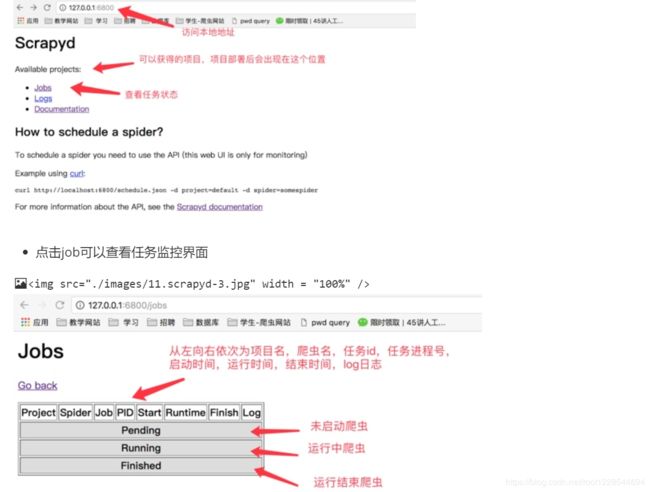
项目部署
编辑需要部署的项目的scrapy.cfg文件
[deploy:部署名(部署名可以自行定义)]
url = http://localhost:6800/
project = 项目名(创建爬虫项目时使用的名称)

部署项目到scrapyd
- 在scrapy项目路径下执行:
scrapyd-deploy 部署名(配置文件中设置的名称) -p 项目名称
管理scrapy项目
- 启动项目:
- curl http://localhost:6800/schedule.json -d project=project_name -d spider=spider_name
- 关闭爬虫:
- curl http://localhost:6800/cancel.json -d project=project_name -d job=jobid
注意;curl是命令行工具,如果没有则需要额外安装
使用requests模块控制scrapy项目
import requests
# 启动爬虫
url = 'http://localhost:6800/schedule.json'
data = {
'project': 项目名,
'spider': 爬虫名,
}
resp = requests.post(url, data=data)
# 停止爬虫
url = 'http://localhost:6800/cancel.json'
data = {
'project': 项目名,
'job': 启动爬虫时返回的jobid,
}
resp = requests.post(url, data=data)
其他webapi
- curl http://localhost:6800/listprojects.json (列出项目)
- curl http://localhost:6800/listspiders.json?project=myspider (列出爬虫)
- curl http://localhost:6800/listjobs.json?project=myspider (列出job)
- curl http://localhost:6800/cancel.json -d project=myspider -d job=tencent (终止爬虫,该功能会有延时或不能终止爬虫的情况,此时可用kill -9杀进程的方式中止)
Gerapy
Gerapy 是一款 分布式爬虫管理框架
- 更方便地控制爬虫运行
- 更直观地查看爬虫状态
- 更实时地查看爬取结果
- 更简单地实现项目部署
- 更统一地实现主机管理
Install
1.执行如下命令,等待安装完毕
pip3 install gerapy
2.验证gerapy是否安装成功
在终端中执行 gerapy
Setting and Start
1.新建一个项目
gerapy init
执行完该命令之后会在当前目录下生成一个gerapy文件夹,进入该文件夹,会找到一个名为projects的文件夹
2.对数据库进行初始化(在gerapy目录中操作),执行如下命令
gerapy migrate
对数据库初始化之后会生成一个SQLite数据库,数据库保存主机配置信息和部署版本等
3.启动 gerapy服务
gerapy runserver
此时启动gerapy服务的这台机器的8000端口上开启了Gerapy服务,在浏览器中输入http://localhost:8000就能进入Gerapy管理界面,在管理界面就可以进行主机管理和界面管理
Manage scrapy project by the settings of Gerapy
-
配置主机
1.添加scrapyd主机
需要添加 IP、端口,以及名称,点击创建即可完成添加,点击返回即可看到当前添加的 Scrapyd 服务列表,创建成功后,可以在列表中查看已经添加的服务
2.执行爬虫,就点击调度.然后运行. (前提是: 我们配置的scrapyd中,已经发布了爬虫.) -
配置Projects
1.将scarpy项目直接放到 /gerapy/projects下.
2.可以在gerapy后台看到有个项目
3.点击部署点击部署按钮进行打包和部署,在右下角可以输入打包时的描述信息,类似于 Git 的 commit 信息,然后点击打包按钮,即可发现 Gerapy 会提示打包成功,同时在左侧显示打包的结果和打包名称。
4.选择一个站点,点击右侧部署,将该项目部署到该站点上
5.成功部署之后会显示描述和部署时间
6.来到clients界面,找到部署该项目的节点,点击调度
7.在该节点中的项目列表中找到项目,点击右侧run运行项目
Relationship between Gerapy and Scrapyd
使用scrapyd是可以调用scrapy进行爬虫. 只是需要使用命令行开启爬虫
curl http://127.0.0.1:6800/schedule.json -d project=工程名 -d spider=爬虫名
在gerapy中配置了scrapyd后,不需要使用命令行,可以通过图形化界面直接开启爬虫。
Crawlspider
crawlspider能够匹配满足条件的url地址,组装成Reuqest对象后自动发送给引擎,同时能够指定callback函数
crawlspider爬虫可以按照规则自动获取连接
new project
1 创建crawlspider爬虫:
scrapy genspider -t crawl job 163.com
2 spider中默认生成的内容如下:
class JobSpider(CrawlSpider):
name = 'job'
allowed_domains = ['163.com']
start_urls = ['https://hr.163.com/position/list.do']
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
i = {}
#i['domain_id'] = response.xpath('//input[@id="sid"]/@value').extract()
#i['name'] = response.xpath('//div[@id="name"]').extract()
#i['description'] = response.xpath('//div[@id="description"]').extract()
return i
和普通的scrapy.spider的区别

key points

other things

summary

Coding
scrapy_redis和scrapy_splash配合使用
- 重写dupefilter去重类
from __future__ import absolute_import
from copy import deepcopy
from scrapy.utils.request import request_fingerprint
from scrapy.utils.url import canonicalize_url
from scrapy_splash.utils import dict_hash
from scrapy_redis.dupefilter import RFPDupeFilter
def splash_request_fingerprint(request, include_headers=None):
""" Request fingerprint which takes 'splash' meta key into account """
fp = request_fingerprint(request, include_headers=include_headers)
if 'splash' not in request.meta:
return fp
splash_options = deepcopy(request.meta['splash'])
args = splash_options.setdefault('args', {})
if 'url' in args:
args['url'] = canonicalize_url(args['url'], keep_fragments=True)
return dict_hash(splash_options, fp)
class SplashAwareDupeFilter(RFPDupeFilter):
"""
DupeFilter that takes 'splash' meta key in account.
It should be used with SplashMiddleware.
"""
def request_fingerprint(self, request):
return splash_request_fingerprint(request)
"""以上为重写的去重类,下边为爬虫代码"""
from scrapy_redis.spiders import RedisSpider
from scrapy_splash import SplashRequest
class SplashAndRedisSpider(RedisSpider):
name = 'splash_and_redis'
allowed_domains = ['baidu.com']
# start_urls = ['https://www.baidu.com/s?wd=13161933309']
redis_key = 'splash_and_redis'
# lpush splash_and_redis 'https://www.baidu.com'
# 分布式的起始的url不能使用splash服务!
# 需要重写dupefilter去重类!
def parse(self, response):
yield SplashRequest('https://www.baidu.com/s?wd=13161933309',
callback=self.parse_splash,
args={'wait': 10}, # 最大超时时间,单位:秒
endpoint='render.html') # 使用splash服务的固定参数
def parse_splash(self, response):
with open('splash_and_redis.html', 'w') as f:
f.write(response.body.decode())
- scrapy_redis和scrapy_splash配合使用的配置
# 渲染服务的url
SPLASH_URL = 'http://127.0.0.1:8050'
# 下载器中间件
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
# 使用Splash的Http缓存
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
# 去重过滤器
# DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
# DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 指纹生成以及去重类
DUPEFILTER_CLASS = 'test_splash.spiders.splash_and_redis.SplashAwareDupeFilter' # 混合去重类的位置
SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 调度器类
SCHEDULER_PERSIST = True # 持久化请求队列和指纹集合, scrapy_redis和scrapy_splash混用使用splash的DupeFilter!
ITEM_PIPELINES = {'scrapy_redis.pipelines.RedisPipeline': 400} # 数据存入redis的管道
REDIS_URL = "redis://127.0.0.1:6379" # redis的url