HBase建立二级索引的一些解决方案
HBase的一级索引就是rowkey,我们只能通过rowkey进行检索。如果我们相对hbase里面列族的列列进行一些组合查询,就需要采用HBase的二级索引方案来进行多条件的查询。
常见的二级索引方案有以下几种:
1.MapReduce方案
2.ITHBASE方案
3.IHBASE方案
4.Coprocessor方案
5.Solr+hbase方案
MapReduce方案
IndexBuilder:利用MR的方式构建Index
优点:并发批量构建Index
缺点:不能实时构建Index
举例:
原表:
row 1 f1:name zhangsan
row 2 f1:name lisi
row 3 f1:name wangwu索引表:
row zhangsan f1:id 1
row lisi f1:id 2
row wangwu f1:id 3Demo:
package IndexDouble;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
import org.apache.commons.collections.map.HashedMap;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.HConnection;
import org.apache.hadoop.hbase.client.HConnectionManager;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.MultiTableOutputFormat;
import org.apache.hadoop.hbase.mapreduce.TableInputFormat;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.util.GenericOptionsParser;
public class IndexBuilder {
private String rootDir;
private String zkServer;
private String port;
private Configuration conf;
private HConnection hConn = null;
private IndexBuilder(String rootDir,String zkServer,String port) throws IOException{
this.rootDir = rootDir;
this.zkServer = zkServer;
this.port = port;
conf = HBaseConfiguration.create();
conf.set("hbase.rootdir", rootDir);
conf.set("hbase.zookeeper.quorum", zkServer);
conf.set("hbase.zookeeper.property.clientPort", port);
hConn = HConnectionManager.createConnection(conf);
}
static class MyMapper extends TableMapper{
//记录了要进行索引的列
private Map indexes = new
HashMap();
private String familyName;
@Override
protected void map(ImmutableBytesWritable key, Result value,
Context context) throws IOException, InterruptedException {
//原始表列
Set keys = indexes.keySet();
//索引表的rowkey是原始表的列,索引表的列是原始表的rowkey
for (byte[] k : keys){
//获得新建索引表的表名
ImmutableBytesWritable indexTableName = indexes.get(k);
//Result存放的是原始表的数据
//查找到内容 根据列族 和 列 得到原始表的值
byte[] val = value.getValue(Bytes.toBytes(familyName), k);
if (val != null) {
//索引表
Put put = new Put(val);//索引表行键
//列族 列 原始表的行键
put.add(Bytes.toBytes("f1"),Bytes.toBytes("id"),key.get());
context.write(indexTableName, put);
}
}
}
//真正运行Map之前执行一些处理。
@Override
protected void setup(Context context) throws IOException,
InterruptedException {
//通过上下文得到配置
Configuration conf = context.getConfiguration();
//获得表名
String tableName = conf.get("tableName");
//String family = conf.get("familyName");
//获得列族
familyName = conf.get("columnFamily");
//获得列
String[] qualifiers = conf.getStrings("qualifiers");
for (String qualifier : qualifiers) {
//建立一个映射,为每一个列创建一个表,表的名字tableName+"-"+qualifier
//原始表的列 索引表新建表名
indexes.put(Bytes.toBytes(qualifier),
new ImmutableBytesWritable(Bytes.toBytes(tableName+"-"+qualifier)));
}
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
String rootDir = "hdfs://hadoop1:8020/hbase";
String zkServer = "hadoop1";
String port = "2181";
IndexBuilder conn = new IndexBuilder(rootDir,zkServer,port);
String[] otherArgs = new GenericOptionsParser(conn.conf, args).getRemainingArgs();
//IndexBuilder: TableName,ColumnFamily,Qualifier
if(otherArgs.length<3){
System.exit(-1);
}
//表名
String tableName = otherArgs[0];
//列族
String columnFamily = otherArgs[1];
conn.conf.set("tableName", tableName);
conn.conf.set("columnFamily", columnFamily);
//列 可能存在多个列
String[] qualifiers = new String[otherArgs.length-2];
for (int i = 0; i < qualifiers.length; i++) {
qualifiers[i] = otherArgs[i+2];
}
//设置列
conn.conf.setStrings("qualifiers", qualifiers);
@SuppressWarnings("deprecation")
Job job = new Job(conn.conf,tableName);
job.setJarByClass(IndexBuilder.class);
job.setMapperClass(MyMapper.class);
job.setNumReduceTasks(0);//由于不需要执行reduce阶段
job.setInputFormatClass(TableInputFormat.class);
job.setOutputFormatClass(MultiTableOutputFormat.class);
Scan scan = new Scan();
TableMapReduceUtil.initTableMapperJob(tableName,scan,
MyMapper.class, ImmutableBytesWritable.class, Put.class, job);
job.waitForCompletion(true);
}
}
创建原始表
hbase(main):002:0> create 'studentinfo','f1'
0 row(s) in 0.6520 seconds
=> Hbase::Table - studentinfo
hbase(main):003:0> put 'studentinfo','1','f1:name','zhangsan'
0 row(s) in 0.1640 seconds
hbase(main):004:0> put 'studentinfo','2','f1:name','lisi'
0 row(s) in 0.0240 seconds
hbase(main):005:0> put 'studentinfo','3','f1:name','wangwu'
0 row(s) in 0.0290 seconds
hbase(main):006:0> scan 'studentinfo'
ROW COLUMN+CELL
1 column=f1:name, timestamp=1436262175823, value=zhangsan
2 column=f1:name, timestamp=1436262183922, value=lisi
3 column=f1:name, timestamp=1436262189250, value=wangwu
3 row(s) in 0.0530 seconds创建索引表
hbase(main):007:0> create 'studentinfo-name','f1'
0 row(s) in 0.7740 seconds
=> Hbase::Table - studentinfo-name执行结果

ITHBASE方案
优点:ITHBase(Indexed Transactional HBase)是HBase的一个事物型的带索引的扩展。
缺点:需要重构hbase,几年没有更新。
http://github.com/hbase-trx/hbase-transactional-tableindexed
IHBASE方案
**优点:**IHBase(Indexed HBase)是HBase的一个扩展,用干支持更快的扫描。
缺点:需要重构hbase。
原理:在Memstore满了以后刷磁盘时,IHBase会进行拦截请求,并为这个memstore的数据构建索引,索引另一个CF的方式存储在表内。scan的时候,IHBase会结合索引列中的标记,来加速scan。
http://github.com/ykulbak/ihbase
Coprocessor方案
HIndex–来自华为的HBase二级索引
http://github.com/Huawei-Hadoop/hindex
The solution is 100% Java, compatible with Apache HBase 0.94.8, and is open sourced under ASL.
Following capabilities are supported currently.
1.multiple indexes on table,
2.multi column index,
3.index based on part of a column value,
4.equals and range condition scans using index, and
5.bulk loading data to indexed table (Indexing done with bulk load).
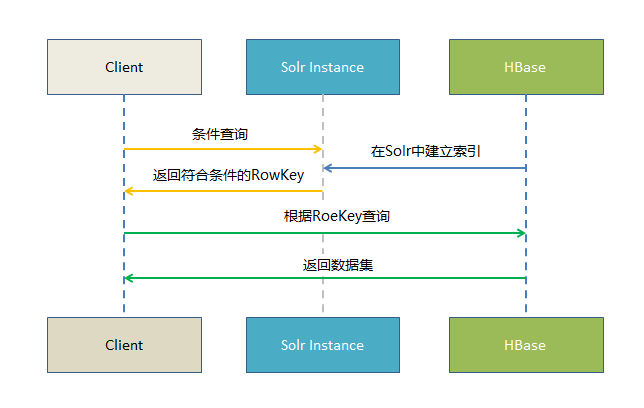
Solr+hbase方案
Solr是一个独立的企业级搜索应用服务器,它对并提供类似干Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。
Solr是一个高性能,采用Java5开发,基干Lucene的全文搜索服务器。同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能节理界面,是一款非常优秀的全文搜索引擎。
HBase无可置疑拥有其优势,但其本身只对rowkey支持毫秒级的快速检索,对于多字段的组合查询却无能为力。
基于Solr的HBase多条件查询原理很简单,将HBase表中涉及条件过滤的字段和rowkey在Solr中建立索引,通过Solr的多条件查询快速获得符合过滤条件的rowkey值,拿到这些rowkey之后在HBASE中通过指定rowkey进行查询。