并行程序设计报告(MPI并行计算π,实现mandelbrot集)
代码的github地址
一.熟悉MPI并行程序设计环境
1.硬件
电脑:HP暗夜精灵
内存:4G
处理器:ntel® Core™ i5-6300HQ CPU @ 2.30GHz × 4
显卡:NVIDIA 960M
2.软件
系统:Ubuntu 16.04LTS
MPI版本:MPICH2
二.计算 π \pi π
1.问题描述
已知 π \pi π计算公式: π = ∫ 0 1 4 1 + x 2 d x \pi=\int_{0}^{1}{\frac{4}{1+x^2}}dx π=∫011+x24dx已知有如下两种算法求其数值积分:
- 1.用梯形面积进行数值计算
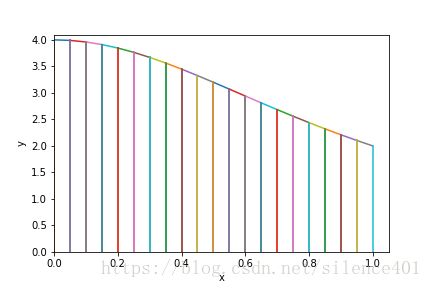
- 2.用矩形面积进行数值计算
2.程序概要设计(用梯形法计算)
MPI_Bcast(&n,1,MPI_INT,0,MPI_COMM_WORLD);//把n广播给所有进程
MPI_Barrier(MPI_COMM_WORLD);
init_size=1.0/n;//把图形分为n个梯形,每个梯形的高为1/n
for(int i=rank+1;i<=n;i+=proc_num)//每个进程计算n/proc_num个梯形
{
x1=init_size*(i);
x2=init_size*(i-1);
x1=4/(1+x1*x1);
x2=4/(1+x2*x2);
part_sum=part_sum+x1+x2;//把梯形的上底和下底计算到部分和中
}
temp_pi=init_size*part_sum/2;//计算该进程所计算的梯形面积和
//归约函数,对所有进程所计算的面积求和即是pi值
MPI_Reduce(&temp_pi,&cal_pi,1,MPI::DOUBLE,MPI::SUM,0,MPI_COMM_WORLD);
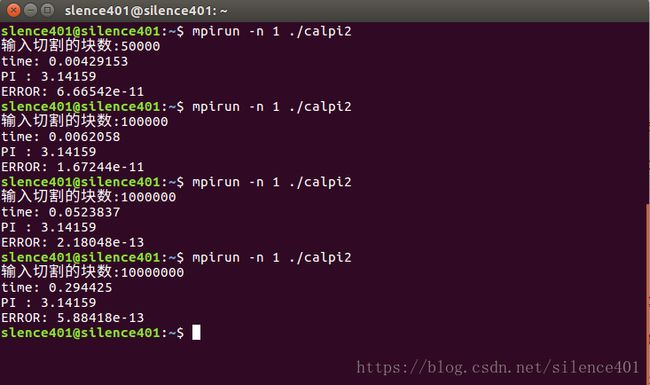
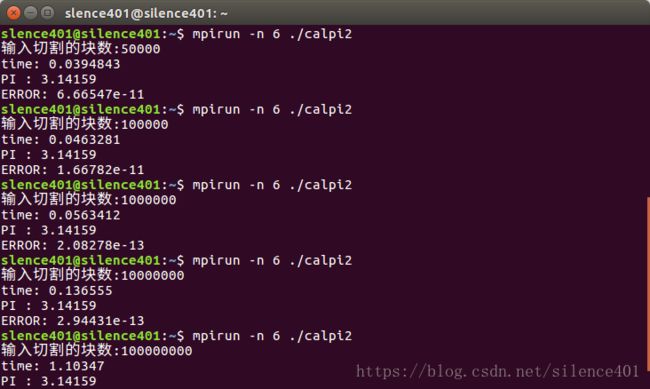
3.实验结果及其分析
| 分割块数 | 50000 | 100000 | 1000000 | 10000000 | 100000000 |
|---|---|---|---|---|---|
| 无并行(运行时间 s) | 0.00429 | 0.00620 | 0.05238 | 0.29442 | 2.79347 |
| 两个进程并行(运行时间 s) | 0.00074 | 0.00145 | 0.01370 | 0.13708 | 1.38299 |
| 三个进程并行(运行时间 s) | 0.00052 | 0.00098 | 0.00936 | 0.08995 | 0.92909 |
| 四个进程并行(运行时间 s) | 0.00040 | 0.00074 | 0.00743 | 0.07731 | 0.77368 |
| 五个进程并行(运行时间 s) | 0.02835 | 0.03105 | 0.05499 | 0.12929 | 1.19763 |
| 六个进程并行(运行时间 s) | 0.03948 | 0.04632 | 0.05634 | 0.13655 | 1.10347 |
部分结果截图如下:
结果分析:
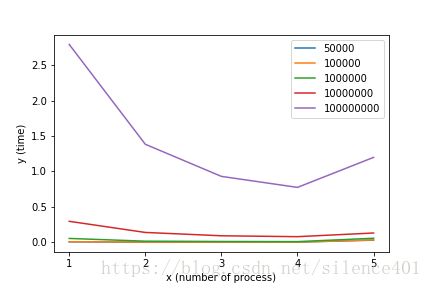
| 分割块数 | 50000 | 100000 | 1000000 | 10000000 | 100000000 |
|---|---|---|---|---|---|
| 无并行(加速比) | 1 | 1 | 1 | 1 | 1 |
| 两个进程并行(加速比) | 5.79 | 4.27 | 3.82 | 2.14 | 2.01 |
| 三个进程并行(加速比) | 8.25 | 6.33 | 5.59 | 3.27 | 3.01 |
| 四个进程并行(加速比) | 10.73 | 8.38 | 7.05 | 3.80 | 3.61 |
| 五个进程并行(加速比) | 0.15 | 0.20 | 0.95 | 5.35 | 2.33 |
| 六个进程并行(加速比) | 0.11 | 0.13 | 0.92 | 2.15 | 2.53 |
从上图可知,在我的计算机上当开四个进程时性能达到最大,因为我的计算机是四核的可以做到四个进程真正的并行 .当数据两较小时,无并行的比并行的更快的主要原因是计算量小的时候MPI通信的时间占了进程时间开销的大部分.
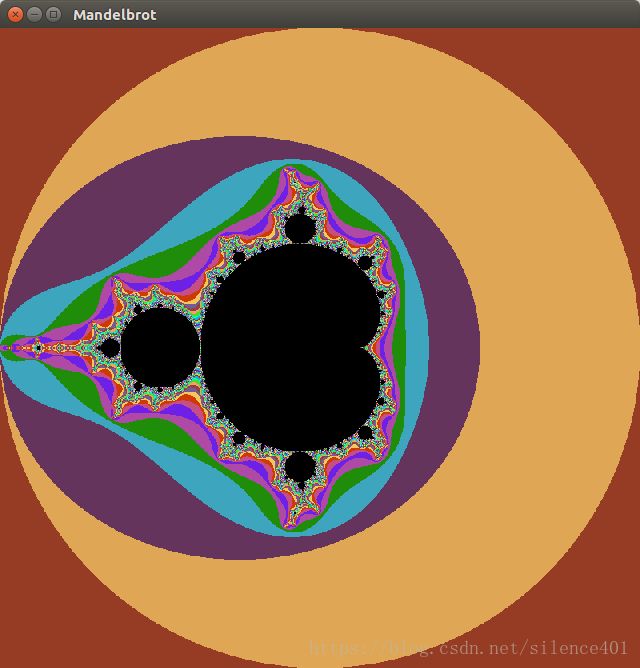
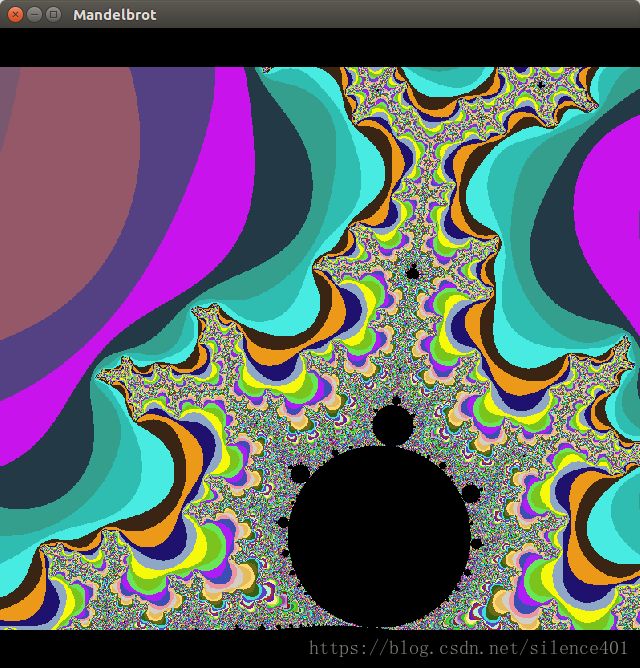
##三.Mandelbrot集##
1.问题描述
曼德勃罗特集是人类有史以来做出的最奇异,最瑰丽的几何图形,曾被称为"上帝的指纹". 这个点集均出自公式 z n + 1 = z n 2 + c z_{n+1}=z_n^2+c zn+1=zn2+c,所有使得无限迭代后的结果能保持有限数值的复数c的集合构成曼德勃罗特集.假定迭代一定次数后的复数即为曼德勃罗特数,计算一定区间的曼德勃罗特集,并根据数字不同的迭代次数给该点设为不同的颜色.滑动鼠标,即可计算一定区域的曼德勃罗特集并显示出来
2.程序概要设计
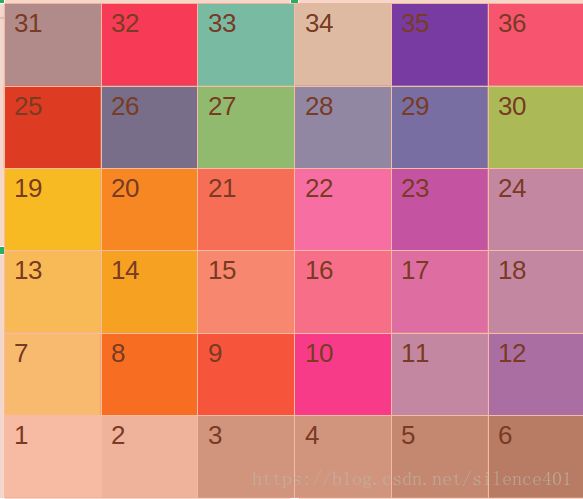
把区域分为 n ∗ n n*n n∗n的区域按顺序依次分给空闲的进程
//定义Zn+1=Zn^2+c的运算
ComplexNumber f(ComplexNumber z, ComplexNumber c)
{
ComplexNumber result;
result.real=c.real+z.real*z.real-z.imag*z.imag;
result.imag=c.imag+z.imag*z.real+z.real*z.imag;
return result;
}
//定义曼德勃罗特的计算步骤,并在recv数组中记录该点迭代的次数
void Mandelbrot(double Xmin,double dx, int xloop, int xfrom, double Ymin, double dy, int yloop, int yfrom)
{
int x, y, k;
ComplexNumber c, z;
for (x=0; x // 对于一个进程如果接收到了再计算的命令,就计算分配给他的区域的曼德勃罗特集,区域信息存在info结构体中
if (Redo == status.MPI_TAG)
{
MPI_Recv(&info,1,AreaType,0,Redo,MPI_COMM_WORLD,&status);
int txfrom=(info.xloop%slave_num)*info.sub_xloop;
double tymin=(info.xloop/slave_num)*info.Yarea/slave_num+info.Ymin;
int tyfrom=(info.xloop/slave_num)*info.sub_yloop;
Mandelbrot(txmin,info.dx,info.sub_xloop,txfrom,tymin,info.dy,info.sub_yloop,tyfrom);
MPI_Send(&info.xloop,1,MPI_INT,0,Over,MPI_COMM_WORLD);
MPI_Send(recv,PIXEL_NUM,MPI_SHORT,0,Over,MPI_COMM_WORLD);
printf("send from slave %d\n", rank-1);
}
//opengl的闲时回调函数,主进程一直再执行该函数,接受子进程的数据,当接受到一个进程发来的数据时,
主进程判断还有无未计算的区域,如果有就分配给该进程
void Idle()
{
//printf("34");
static int recved = 0;
int pos;
int i, j, x, y;
int xfrom, yfrom;
int flag, slave_rank;
MPI_Status status;
MPI_Iprobe(MPI_ANY_SOURCE,Over,MPI_COMM_WORLD, &flag, &status);
if (!flag) return;
MPI_Recv(&pos,1,MPI_INT,status.MPI_SOURCE,Over,MPI_COMM_WORLD,&status);
MPI_Recv(recv,PIXEL_NUM,MPI_SHORT,status.MPI_SOURCE,Over,MPI_COMM_WORLD,&status);
if (slave_num*slave_num== ++recved)
{
recved = 0;
end_time = MPI_Wtime();
printf("wall clock time = %f\n", end_time-start_time);
}
slave_rank = status.MPI_SOURCE-1;
printf("recieve from slave %d\n", slave_rank);
i = slave_rank;
xfrom = (pos%slave_num)*info.sub_xloop;
yfrom = (pos/slave_num)*info.sub_yloop;
for(x=0; x3实验.结果及其分析