序列化和反序列化、以及反序列化注入问题要点
所有你想要的东西都标着价格
序列化的实体是个对象,结果也是个对象,并非是格式化文本,你在记事本里看到的购物信息保存记录,其实不是对象序列化的结果,而是对象输出的格式化文本,真正的序列化对象是看不懂的。
序列化的应用场景
在实际使用对象序列化时,
- 一种应用场景是将对象序列化到持久化存储(本地硬盘),我们此时不想做文件解析,也不想有人读懂这个持久化文件,当我们需要时,可以直接采用反序列化将保存的文件生成为对象;
- **另一种应用场景是在网络传输过程中,此时对象会在不同主机上传播,序列化会将对象转成码流由对端进行解析,这个解析过程不需要人参与。 **
普通字符串是经过解析后的对象,有对象到字符串要加入解析逻辑,人才能看懂。
序列化的结果是个只有JAVA虚拟机认识的文件,人不参与,只是用于保存对象或传输。
简单说,像一篇文章里提到的那样,“”当你想从一个jvm中调用另一个jvm的对象时,你就可以考虑使用序列化了。序列化的作用就是为了不同jvm之间共享实例对象的一种解决方案。”
JDK中序列化和反序列化API
java.io.ObjectOutputStream代表对象输出流,它的writeObject(Object obj)方法可对参数指定的obj对象进行序列化,把得到的字节序列写到一个目标输出流中。
java.io.ObjectInputStream代表对象输入流,它的readObject()方法从一个源输入流中读取字节序列,再把它们反序列化为一个对象,并将其返回。
只有实现了Serializable接口或Externalizable接口的类的对象才能被序列化。
对象序列化包括如下步骤:
1) 创建一个对象输出流,它可以包装一个其他类型的目标输出流,如文件输出流,字节数组输出流;
2) 通过对象输出流的writeObject()方法写对象。
对象反序列化的步骤如下:
1) 创建一个对象输入流,它可以包装一个其他类型的源输入流,如文件输入流,字节数组输入流;
2) 通过对象输入流的readObject()方法读取对象。
默认序列化机制
如果仅仅只是让某个类实现Serializable接口,而没有其它任何处理的话,则就是使用默认序列化机制。使用默认机制,在序列化对象时,不仅会序列化当前对象本身,还会对该对象引用的其它对象也进行序列化,同样地,这些其它对象引用的另外对象也将被序列化,以此类推。所以,如果一个对象包含的成员变量是容器类对象,而这些容器所含有的元素也是容器类对象,那么这个序列化的过程就会较复杂,开销也较大。
SerialVersionUID的作用
简单来说,Java的序列化机制是通过在运行时判断类的serialVersionUID来验证版本一致性的。在进行反序列化时,JVM会把传来的字节流中的serialVersionUID与本地相应实体(类)的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常。(InvalidCastException)
强烈建议在一个可序列化类中显示的定义serialVersionUID,为它赋予明确的值。
问题一:假设有A端和B端,如果2处的serialVersionUID不一致,会产生什么错误呢?
答案如下:
1)先执行测试类SerialTest,然后修改serialVersion值(或注释掉serialVersion并编译),再执行测试类DeserialTest,报错:
java.io.InvalidClassException: com.test.serializable.Serial; local class incompatible: stream classdesc serialVersionUID = 1, local class serialVersionUID = 11
2)A端和B端都没显示的写serialVersionUID,实体类没有改动(如果class文件(类名,方法明等)没有发生变化(增加空格,换行,增加注释,等等),).序列化,反序列化正常.
问题二:假设2处serialVersionUID一致,如果A端增加一个字段,B端不变,会是什么情况呢?
答案二: 序列化,反序列化正常,A端增加的字段丢失(被B端忽略).
问题五:假设2处serialVersionUID一致,如果B端减少一个字段,A端不变,会是什么情况呢?
答案:与问题二类似,序列化,反序列化正常,B端字段少于A端,A端多的字段值丢失(被B端忽略).
问题三:假设2处serialVersionUID一致,如果B段增加一个字段,A端不变,会是什么情况呢?
问题四:假设2处serialVersionUID一致,如果A端减少一个字段,B端不变,会是什么情况呢?(与问题三类似,四答案:序列化,反序列化正常,B端字段多余A端,B端多出的字段被赋予对应类型的默认值)
答案三: 序列化,反序列化正常,B端新增加的int字段被赋予了默认值0.
这里有一篇写的很通俗易懂关于serialVersionUID的介绍
transient关键字的作用
在实际开发过程中,我们常常会遇到这样的问题,这个类的有些属性需要序列化,而其他属性不需要被序列化,打个比方,如果一个用户有一些敏感信息(如密码,银行卡号等),为了安全起见,不希望在网络操作(主要涉及到序列化操作,本地序列化缓存也适用)中被传输,这些信息对应的变量就可以加上transient关键字。换句话说,这个字段的生命周期仅存于调用者的内存中而不会写到磁盘里持久化。
java 的transient关键字为我们提供了便利,你只需要实现Serilizable接口,将不需要序列化的属性前添加关键字transient,序列化对象的时候,这个属性就不会序列化到指定的目的地中。
Externalizable接口的作用
它是Serializable接口的子类,有时我们不希望序列化那么多,可以使用这个接口,这个接口的writeExternal()和readExternal()方法可以指定序列化哪些属性;
序列化需要主要的问题:
1.序列化时,只对对象的状态进行保存,而不管对象的方法;
2.当一个父类实现序列化,子类自动实现序列化,不需要显式实现Serializable接口;
3.当一个对象的实例变量引用其他对象,序列化该对象时也把引用对象进行序列化;
4.并非所有的对象都可以序列化,,至于为什么不可以,有很多原因了,比如:
安全方面的原因,比如一个对象拥有private,public等field,对于一个要传输的对象,比如写到文件,或者进行rmi传输 等等,在序列化进行传输的过程中,这个对象的private等域是不受保护的。
反序列化的注入漏洞问题
1.WebLogic, WebSphere, JBoss, Jenkins, and OpenNMS等java应用都曾受过该漏洞影响。Apache Commons Collections这样的基础库非常多的Java应用都在用,一旦编程人员误用了反序列化这一机制,使得用户输入可以直接被反序列化,就能导致任意代码执行,这是一个极其严重的问题,WebLogic等存在此问题的应用可能只是冰山一角。
2.首先拿到一个漏洞应用,需要找到一个接受外部输入的序列化对象的接收点,即反序列化漏洞的触发点。我们可以通过审计源码中对反序列化函数的调用(例如readObject())来寻找,也可以直接通过对应用交互流量进行抓包,查看流量中是否包含序列化数据来判断,如java序列化数据的特征为以标记(ac ed 00 05)开头。确定了反序列化输入点后,再考察应用的Class Path中是否包含相应的基础库,如Apache Commons Collections库,可通过“grep -R InvokerTransformer .”确认是否包含exp需要的类库(把“InvokerTransformer”删除干净则此漏洞便无法触发)。
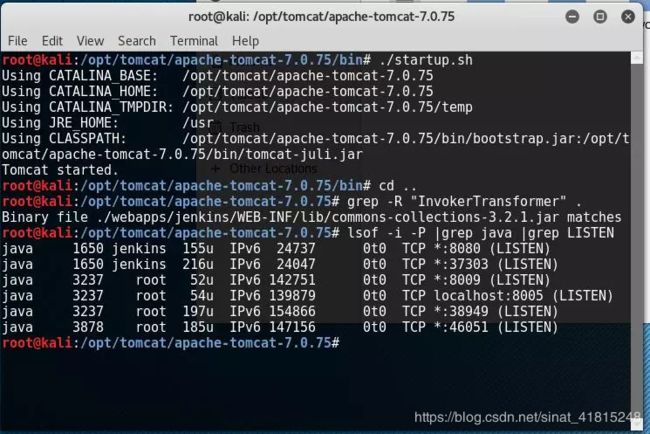
3.新版本虽然抓不到端口信息了,但是exp需要的基础类库仍然存在。
4.解决方法:可以加入防火墙过滤相应端口的通信。假若反序列化可以设置Java类型的白名单,那么问题的影响就小了很多。使用加密通信,如SSL。