论文阅读:Deep Feature Fusion for VHR Remote Sensing Scene Classification
论文阅读:Deep Feature Fusion for VHR Remote Sensing Scene Classification
- 摘要
- 1. Introdudction
- 2. 方法描述
- A. VGG-Net特征提取
- B. Discriminant Correlation Analysis - DCA
- 3. 实验结果和设置
- 数据集
- 实验设置
- AID
- UC-Merced
- WHU-RS
摘要
目前可获取的遥感图像分辨率达到了高分、甚高分,这为甚高分(VHR)影像分类带来了挑战。本文提出了一个VHR场景理解框架。首先,visual geometry group network (VGG-Net)模型被用来提取图像的信息;其次,我们选择全连接层,合并他们以构建最终的VHR图像场景的表达;然后,使用discriminant correlation analysis (DCA)特征融合策略,进一步改善特征提取过程,从而以很小的计算代价,高效融合特征。在三个数据库上实验:UC-MERCED,WHU-RS19,AID。实验结果超过state-of-art方法。利用特征融合技术比单纯利用原始深特征具有更高的准确率。此外,基于DCA融合的图像描述方法能产生较好的信息特征来描述低维的图像场景。
1. Introdudction
VHR图像的高维性和统计特性是VHR场景理解[1]最具挑战性的地方。
一些基础传统手工特征方法…… Lu[7]等人通过对不同尺度图像场景的分析,提出了一种新的模型来构造多分辨率特征,然后构造了基于稀疏特征选择的流形正则化模型。但是,以上这些方法提取的都是低级特征,忽略原始数据中的信息。
由于上述商法的局限性,Zhang[8]等人提出一种两步的高效框架:1)块采样 2)无监督特征学习的稀疏自编码器。第一步中,提出了一个显著性检测方法context-aware saliency,作为提取表达性块的采样策略;第二步中,每个块用其中的像素密度值表达。该方法的不足:忽略了VHR图像的语义含义。
为了挑战这个缺点,Cheng[9]等人提出了一个可以用于目标检测和图像分类的新方法:基于部分检测器集合(COPD)的多类地理空间目标检测和地理图像分类。之后[10],他们针对VHR遥感影像,提出了一种基于“零件”的高效的面向中层视觉要素的土地利用分类方法。这两个方法基于部分监测,在UC Merced数据集上取得了很高的精度。
在过去十年,深度学习方法被用于VHR场景分类。Vaduva[11]等人提出了一个深度方法。[12]提出了一个混合深度卷积神经网络(CNN) 用于卫星图像汽车检测。[13]提出了堆叠自动编码器提取高光谱图像分类的富空间信息特征。[14]提出了用深度学习去选择富信息特征。在[1.]的研究中,引入了一种基于CNN的新方法,将贪婪分层无监督的[15]预处理与有效的强制种群和生命周期稀疏算法[16]相结合,从卫星图像中学习稀疏特征表示。虽然深度学习网络具有较强的鲁棒性和效率,但是上述方法并没有达到较高的精度。
CNN是最成功的深度学习方法之一,因为它在ImageNet大规模视觉识别竞赛中表现出色。 CNN的成功归功于其学习层次表示来描述图像场景的能力。 最近,CNN已经在遥感图像分析的背景下开发,其已经变得越来越流行用于图像场景表示。在[17]中,提出了一种基于CNN的深度集合框架用于场景分类。 不幸的是,很难训练新的CNN,因为它需要非常大的标记数据集并且消耗很长的成本时间[18]。 一些文献已经证明,CNN可以促进不同领域之间的迁移学习,并且工作得非常好。 而且,由于遥感场景分类任务中训练样本的规模较小,很难对CNN模型进行全面训练。 因此,迁移预训练的CNN这种方法已经用于场景分类。迁移分类有两种迁移方式。 一种是直接把具有参数固定的预训练的CNN作为特征提取器[19] - [21]。 另一种是使用预训练的CNN,然后在VHR数据集上对它们进行微调[22],[23]。 Penatti等[20]表明,预训练的CNN可用于识别日常物体并很好地对遥感场景进行分类。 此外,已经开发了更多基于预训练CNN的策略以形成用于场景分类的更好表示。 奥斯曼等人[19]通过稀疏自编码器对卷积特征进行编码来表示图像场景,探索了一种新的VHR场景分类方法。 [22]的研究提出了一种通过学习旋转不变CNN进行光学目标检测的有效方法。 Marmanis等人。 [24]使用预训练的OverFeat模型作为特征提取器,然后将特征传递到监督CNN进行分类。 胡等人 [21]引入了基于预训练CNN的两种情景用于VHR图像场景分类:1)第二全连接层被视为场景图像的最终特征描述符; 2)从最后卷积层提取多个尺度的密集特征,然后通过特征编码方法将密集(多尺度卷积)特征编码为全局表示。
克服上述限制的有效策略是特征融合。 盛等人 [25]引入了颜色直方图和SIFT特征的融合。 [26]和[27]中的研究结合了三个以上的特征描述符来表示图像。 最近,[28]的研究介绍了VHR图像的光谱和结构图像信息的组合。 光谱信息由从采样贴片组中提取的一阶和二阶统计量表示。 并且使用密集的SIFT特征描述符作为结构信息。最近,[29]的研究提出了局部和全局特征的组合来计算BoVW。 如何获得良好的特征描述符来表示用于场景分类的VHR图像仍然是VHR图像场景理解的关键任务。 根据预训练CNN在计算机视觉领域的成功,以及视觉几何组网(VGG-net)在特征提取任务中的巨大成功,我们引入了一个基于预训练VGG-Net模型的新框架来为VHR图像自动学习特征描述符。
如前所述,特征融合是场景理解的有效步骤。 我们提出在CNN算法的输出之间进行组合,其中最终特征可以有效地表示场景图像。 为了减少特征的维数并使用适当的特征融合方法,我们建议在本文中使用判别相关分析(DCA)。 本文的主要贡献有三个方面:
1)我们采用预训练的深CNN模型进行VHR图像场景分类,其中我们使用VGG-Net作为特征提取器,通过选择有用的层来获得图像场景的良好表示。
2)我们首次在VGG-Net模型的不同全连接层之间进行组合,其中每层的输出被假定为特征描述符并且组合以构造输入图像的最终特征表示。 融合深度学习特征比其他特征表示方法(例如SIFT,加速鲁棒特征(SURF)和定向梯度直方图(HOG))以及基于预训练CNN的当前方法表现更好。
3)我们引入DCA以非常低的维度表示融合特征,这允许实现良好的分类性能并加速分类任务。
2. 方法描述
方法包含三部分,如图所示:VGG特征提取;用DCA方法融合特征;SVM分类器。
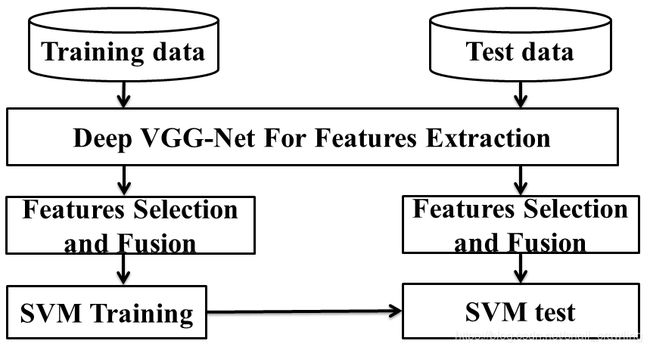
A. VGG-Net特征提取

近几年提出的CNN模型大多数为5层或7层,我们的框架基于VGG-Net,有19层,因此可以提供信息更加丰富的特征。传统方法基于低级特征,例如SIFT、SURF、HOG, 或者直接基于深度特征,本文基于VGG-Net特征的融合。VGG-Net使得特征提取能够获得更丰富的信息。在本文中,使用经过预处理的网络的第一层和第二层全连接层的输出作为特征描述子。
B. Discriminant Correlation Analysis - DCA
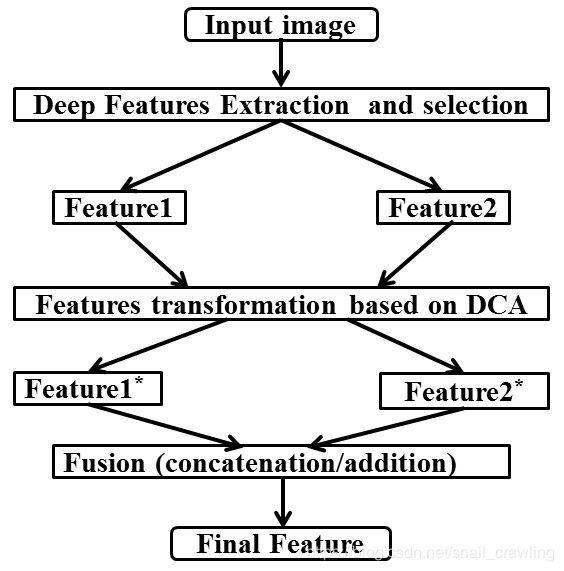
特征融合的目的,是把从图像中提取的特征,合并成一个比输入特征更具有判别能力的特征。如何正确融合特征是一个难题。两个经典的特征融合方法:
- 系列特征融合[35],直接将两个特征进行连接。两个输入特征x和y的维数若为p和q,输出特征z的维数为p+q;
- 并行策略[36],[37],将这两个特征向量组合成复向量,对于输入特征x和y,z = x + iy,其中i是虚数单位。
孙等人[38]引入典型相关分析canonical correlation analysis (CCA) 来融合特征。基于CCA的融合方法使用两个输入特征间的相关关系,计算两种变换,变换后的特征比输入的两个特征集有更高的相关性 。
假设X(p,n)和Y(q,n)是两个特征矩阵,n是特征数量,p和q分别代表他们特征的维度。Sxx和Syy代表各自的协方差矩阵,Sxy是集合间的协方差矩阵,Syx = (Sxy)^T。整体协方差矩阵S为:

CCA的目标是定义一个线性合并
X*=(Wx)^T X
Y*= (Wx)^T X
然后最大化成对特征的相关:

如[38]中个所述,变换后的特征通过以下两种方式合并:


CCA的主要不足,在于忽略了数据集中类结构间的关系。我们想要最大化特征集之间的相关性,所以将每组特征中的类分开。
最近,[44]解决了CCA的弱点,引入了DCA。DCA最大化两个特征集中对应特征的相关关系,同时最大化不同类之间的差异。
3. 实验结果和设置
数据集
AID
UC-Merced
WHU-RS
实验设置
为了分析,我们提取图像的VGG-Net特征。之后用了两种融合技术:
- 标准融合
- DCA融合
AID
整体精度对比
融合方法对比

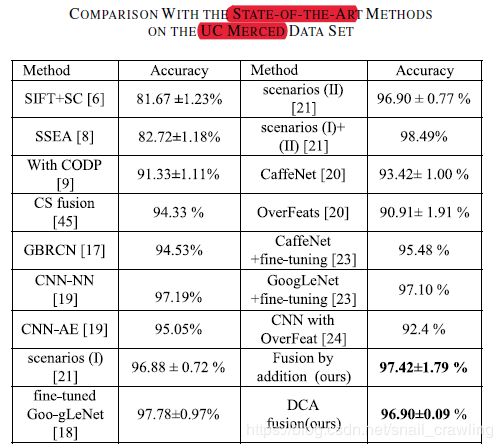
UC-Merced
融合方法对比

和现有最好的方法对比
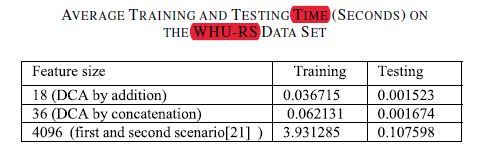
训练集、测试集比例

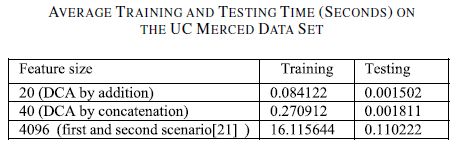
训练和测试时间
WHU-RS
融合策略

整体精度

训练和测试时间