postgreSQL配置文件 postgresql.conf —— 千月的零基础学习PostgreSQL(2)
PostgreSQL 配置文件postgresql.conf
配置文件主要影响这服务器实例的基本行为,比如允许的连接数,操作允许占用的最大内存数,指定哪些用户可以用何种方式连接到数据库等等。当然这一切在数据库安装好时都有一个默认值,但是如果你需要对你的数据库进行定制的话,可以对这些数值进行符合需求的修改。
1、配置文件的位置
既然叫配置文件,那么他必须先是一个文件。我们知道Oracle的配置文件分为pfile 和 spfile,postgreSQL的配置文件有点类似于 pfile ,可以直接编辑。因为安装环境不同,所以配置文件的位置也有所区别,我们首先要找到配置文件在哪里。
进入psql环境。如果失败了,查看下告警内容,是不是没有切换到 postgres 用户下还是数据库没有启动。没有启动的话用下面的命令启动下。
/etc/init.d/postgresql start
当然也可以设置成开机自动启动。记得提前用 su - 切换到 root 用户再操作。
chkconfig -add postgresql
我们进入 psql 环境后使用如下命令来查找数据库的配置文件的位置。
select name,setting from pg_settings where category='File Locations‘;
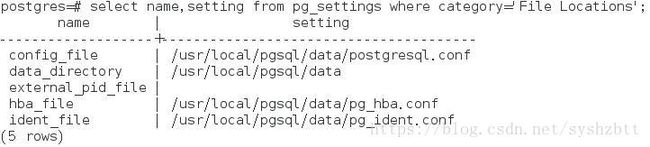
基本上select 语句查询大家应该都很熟悉了。不太熟的可以去网上找个教程去补习下。这里几个注意点,其实和 oracle 的语法相同。
字符串用单引号扩起来,结尾使用分号结束
,没打分号就回车其实是换行。
千月:postgres 自带的 psql 可以tab键自动补全,可以方向键移动光标,上下键查找过去的命令,比 oracle 自带的 sqlplus 好用多了,Oracle要实现这些,需要另装插件。
2、postgresql.conf 和 postgresql.auto.conf
这个配置文件,主要包含着一些通用的设置,算是最重要的配置文件。不过从9.4版本开始,postgresql 引入了一个新的配置文件 postgresql.auto.conf 在存在相同配置的情况下系统先执行 auto.conf 这个文件,换句话说
auto.conf 配置文件优先级高于 conf 文件
。值得注意的是 auto.conf这个文件必须在 psql 中使用 alter system 来修改,而conf可以直接在文本编辑器中修改。
千月:既然 postgresql 是 oracle 的主要开源竞争对手,我们可以拿oracle来做比较,oracle 分为 pfile 和 spfile ,在oracle数据库启动时会先查找 spfile 如果没有才使用 pfile ,Oracle 在使用 pfile 进入系统后,可以用 pfile 生成 spfile ,再次启动数据库后用spfile引导。 在postgresql 里和 oracle 一样的是 postgresql.conf 与 pfile 同为文本格式, postgresql.auto.conf 和 spfile 同为二进制格式。不过区别在于postgres里两个文件同时生效,仅仅是优先级不同。在使用 alter system set 修改postgres的配置文件的时候,仅影响 auto.conf 这个文件的内容,将 参数设回 default 时,auto.conf文件的这项配置会被删除,重新用回 conf 文件的设置。这点和 oracle 不同。
顺便说下,oracle管理员使用 alter system set 修改参数到 spfile 后,
create pfile from spfile ; 是个好习惯哦。
我们这里演示几个关键的设置
使用命令
select name,context,unit,setting,boot_val,reset_val
from pg_settings
where name in
( 'listen_addresses','max_connection','shared_buffers','effective_cache_size','work_mem','maintenance_work_mem'
)
order by context,name ;

这里查询的列含义分为如下:
context :
当这个值为 postmaster 时,需要重启数据库才能生效,而 user 只要重新加载配置即可全局生效。重启数据库意味着全部服务的中断,而重新加载配置不会。
unit :
单位,表示后面这些值的单位。单位主要照顾可读性,比如,你有2G内存,你单位是MB就是2048,但是你要用8KB就是256000,可读性就差太多了。
setting :
当前设置
boot_val :
默认设置
reset_val :
重启或重新加载配置后的设置
通过查看 setting 和 reset_val 是否相同可以看出配置是否生效。
各主要参数含义如下:
listen_addresses :
可以连接服务器使用的IP,一般初始值为 localhost或者local,意味着只有本机可以连接数据库。
这里一般设置为 " * " ,允许全部的IP连接数据库。
port :
侦听端口,默认为5432。
千月:我认为不是特殊原因不要更改默认侦听端口。有时会给运维带来莫名的麻烦。要通知很多协同部门,相关的管理软件也要修改。一个迷糊就出点问题。还是遵循“非必要,勿更改”的原则配置吧。
max_connections :
允许的最大并发连接数,简单来说就是同时多少人能连接你的数据库。
千月:这设置多少其实要看你的需求和系统能负载能力(内存影响较大),不是简单的线性累加。受到很多因素的影响,一个生产环境中,有的连接会占用资源很多,尽量在调查后再设置此值,要是消耗的资源超出你的主机所能承受的范围,可是要宕机的。还有一个要注意的是,我们所说的一个连接,不是指一台主机,而是一个连接进程。所以不能单纯的想有几个人要连接,以此来设置最大连接数。
share_buffers:
共享缓存大小,主要存储了最近访问的数据页。
所有用户会话均会共享此缓存区
。
千月:缓存是全体用户共享的,所以非常重要,此设置对查询速度有着非常大的影响。一般来说越大越好,至少达到系统内存的25%,但是不要超过8G,这对于现在主流的服务器来说毫无压力。如果超过了8G的话,根据格森第一法则,可以推出,消耗内存变多而得到的速度提升却很少,得不偿失。
零基础备注:
格森第一法则,又叫边际效益递减法则,因为一个变量在变化,而另一个变量不变,导致对第一个变量投入越来越多,得到的收益越来越少。举个例子:对于我们的数据库缓存来说,我们的全部数据就像书架上的书,我要找一本《哈姆雷特》就要翻书架,书架很多很多,找起来很慢,最终我们花了30分钟找到了,我们把这本《哈姆雷特》放到小推车里,这个小推车就是share_buffers,因为《哈姆雷特》非常热门,很多人要找,当别人要找《哈姆雷特》的时候,我很简单的花1分钟在小推车里翻翻就可以给他,对于这群人来说查找速度是不是变快了。但是如果这个小推车被做的越来越大,就像内存使用远远超过8G,就类似大卡车的大小了,里面堆满了冷门的书,有些甚至几天就一两个人找,我们也放到了卡车里,这时我们再找《哈姆雷特》,是不是就费劲了。因此我们得到的结果是,小推车share_buffers越大,超过了一个平衡点,我们系统的开销的越大,最后我们查找一些热门的书的效率都不能保障了,确实照顾了一些小众的用户,但大多数用户的体验变差,其实就得不偿失了。
effective_cache_size:
查询执行过程中可使用的最大缓存数。这个包括了数据库的开销,和系统的开销。
千月:这个值一般设置为系统内存的50%以上。系统并不会真的看见这个值设置4G就分配4G,这个值主要是给优化器做参考,优化器会根据这个值来判断系统能否为规划器制定的执行计划提供足够的内存。举个例子:我们需要查询一些数据,如果走索引(速度快,但是占用的中间内存高)需要5G内存,而effective_cache_size只设置了4G,那么优化器就会放弃速度快的索引而使用占用内存相对低的全表扫描进行查询,全表扫描会很慢,这不是我们希望看到的。
maintenance_work_mem:
设置执行 vaccum 操作可用的系统内存。这个值一般情况下不该超过1G。
千月:vaccum说来话长系列,简单的说就是在执行delete删除操作以后,我们仅仅是为删除的记录打上标记,而并没有真正的从物理上删除,也没有释放空间。因此这部分被删除的记录虽热显示被删除了,但是其他新增记录依然不能占用其物理空间,对于这种空间的占用我们称其为HWM(最高水位线),类似下图

HWM理论上只能增加,如果要释放空间的话,我们需要进行 vaccum 操作。当然在oracle系统上也有类似功能: alter table 表名 shrink space ; 工作的情况大概如下图所示。

其他的参数还有非常多。可以参照官方文档。这里捡几个有特点的说说,就不一一介绍了。