ShareTechnote系列LTE(15):HARQ
HARQ
HARQ(hybrid ARQ)是一个非常复杂的过程,这里仅简要描述。
先考虑一下术语。什么是H-ARQ?为什么用“Hybrid ”这个词?
ARQ代表自动重复请求,Hybrid 表示混合了FEC(前向纠错)。FEC也不是LTE特有的技术,是一种通用的纠错机制。
15.1 HARQ架构
下面是LTE HARQ实体的总体架构,详细描述见36.321 5.4.2.1和5.4.2.2。
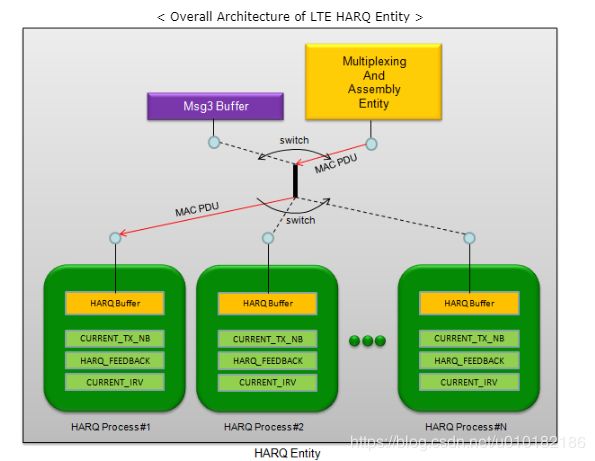
15.2 HARQ进程
根据是用于FDD还是TDD以及是用于上行链路还是下行链路,HARQ处理模式稍微不同,这里只谈FDD。
在FDD中,我们使用8个HARQ进程。
i)下行链路:异步过程
a)可以任意顺序使用8个HARQ进程(异步进程)。
b)在获取数据之前,UE不知道任何有关下行数据的HARQ进程信息。所以网络在PDCCH(DCI)中发送这些信息(进程ID,RV)。
ii)上行链路:同步过程
a)必须在特定的子帧中使用特定的进程(同步进程)。UE必须每8个子帧使用相同的HARQ进程号。
b)由于UE必须在特定的子帧上使用特定的HARQ进程ID,因此eNode B确切地知道何时会出现哪个HARQ进程。eNode B还可以知晓RV,因为eNode B的上行 Grant(DCI 0)可以使用MCS字段指定RV。
c)它有两种操作模式:自适应和非自适应HARQ
<自适应上行HARQ进程>
下面是一个典型的上行HARQ进程的例子(关键思想是每次上行重传使用不同的RV,RV由DCI 0确定)。

<非自适应上行HARQ进程>
以下是非自适应上行HARQ进程的一个例子(关键思想是每次上行重传使用不同的RV,并且RV由TS36.321“5.4.2.2 HARQ进程”中指定的预定义序列确定)。

UE如何知道它是否应该进行自适应重传和非自适应重传? 如果检测到DCI 0且未切换NDI,则执行自适应重传(在这种情况下,UE不关心HARQ反馈(PHICH),它根据DCI 0信息重新传输)。如果得到HARQ反馈(PHICH=NACK),但没有得到DCI 0,则执行非自适应重传。在这种情况下,UE在没有来自DCI 0的信息的情况下重新传输预先定义的RV和MCS中的PUSCH。
上行链路的详细HARQ过程在36.321-5.4.2.2中进行了描述,下面是对图中规范的解释:

15.3 HARQ进程ID同步
当通过HARQ进程传输数据时,接收器和发送器应该知道每个HARQ进程的进程ID的信息,这样接收器就可以成功地保存每个进程数据,而不会混淆。
如果是异步HARQ(如LTE中的PDSCH传输),发送方应明确告知接收方HARQ进程ID。对于LTE,DCI1和DCI2携带这些信息。
如果是同步harq呢?在这种情况下,不必通知进程ID,可以从传输时间推断出进程ID(在LTE上行HARQ情况下,此计时用SFN和子帧号表示),计算公式如下:
![]()
接收端(LTE中的eNode B)是否需要知道确切的HARQ进程ID?不是的。只要eNode B准备至少8个HARQ缓冲区,并为每个子帧分别存储至少8个子帧跨度的PUSCH,就可以正确解码每个HARQ数据。一个可能的步骤如下:
i)eNode B准备8个单独的HARQ缓冲区,并将其命名为buf0、buf1、、buf7。
ii)当eNode B接收到第一个PUSCH时,将其放入eNode B中的第一个上行HARQ缓冲区(buf0)中。
iii)当eNode B接收到第二个PUSCH时,将其放入eNode B中的第二个上行HARQ缓冲区(buf1)中……重复此过程
iv)当eNode B接收到第8个PUSCH时,将其放入eNode B中的第8个上行HARQ缓冲区(buf7)中。
v)当eNode B接收到第9个PUSCH时,将其放入eNode B中的第一个上行HARQ缓冲区(buf0)。重复此过程。
这样,在UE端分配的上行HARQ进程ID和在eNode B接收器缓冲区分配的buf编号之间可能存在不匹配,但解码数据不会有问题。